




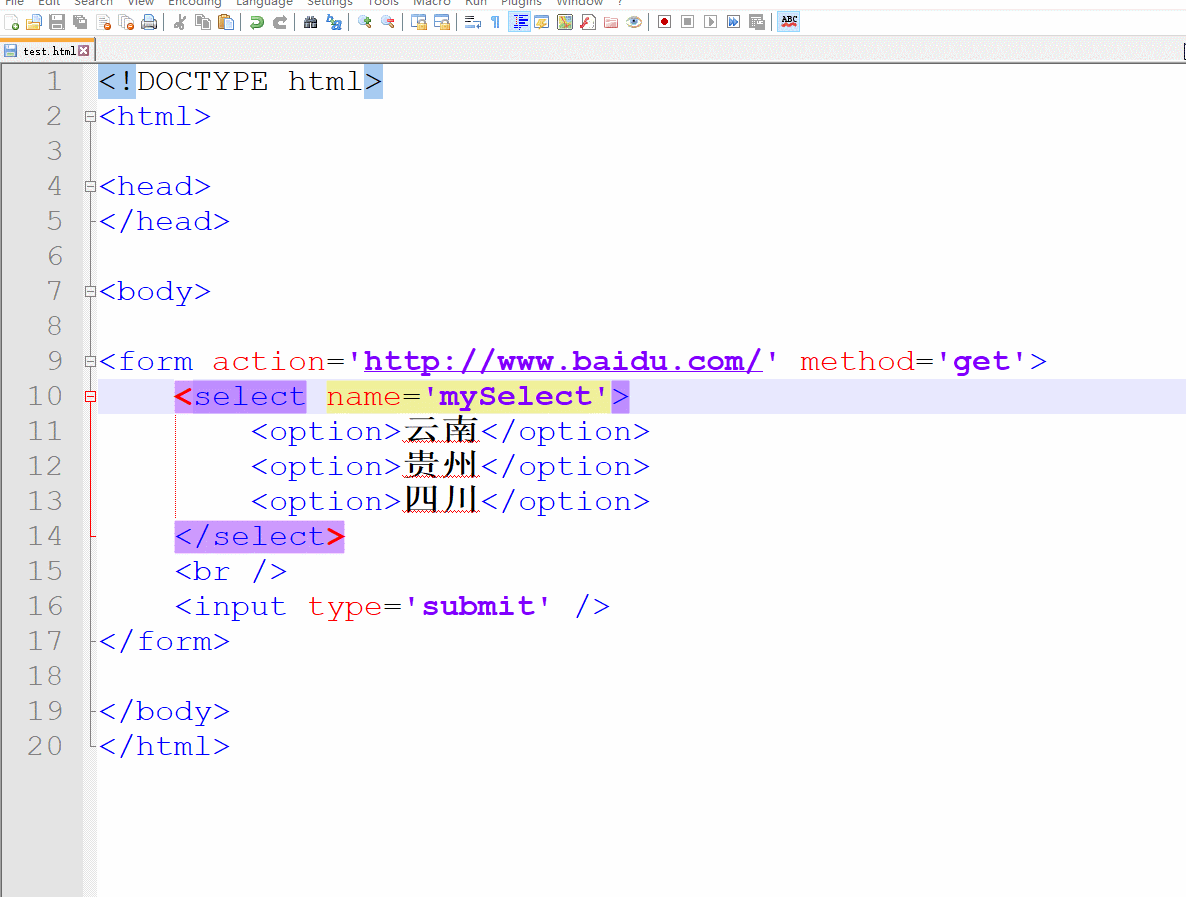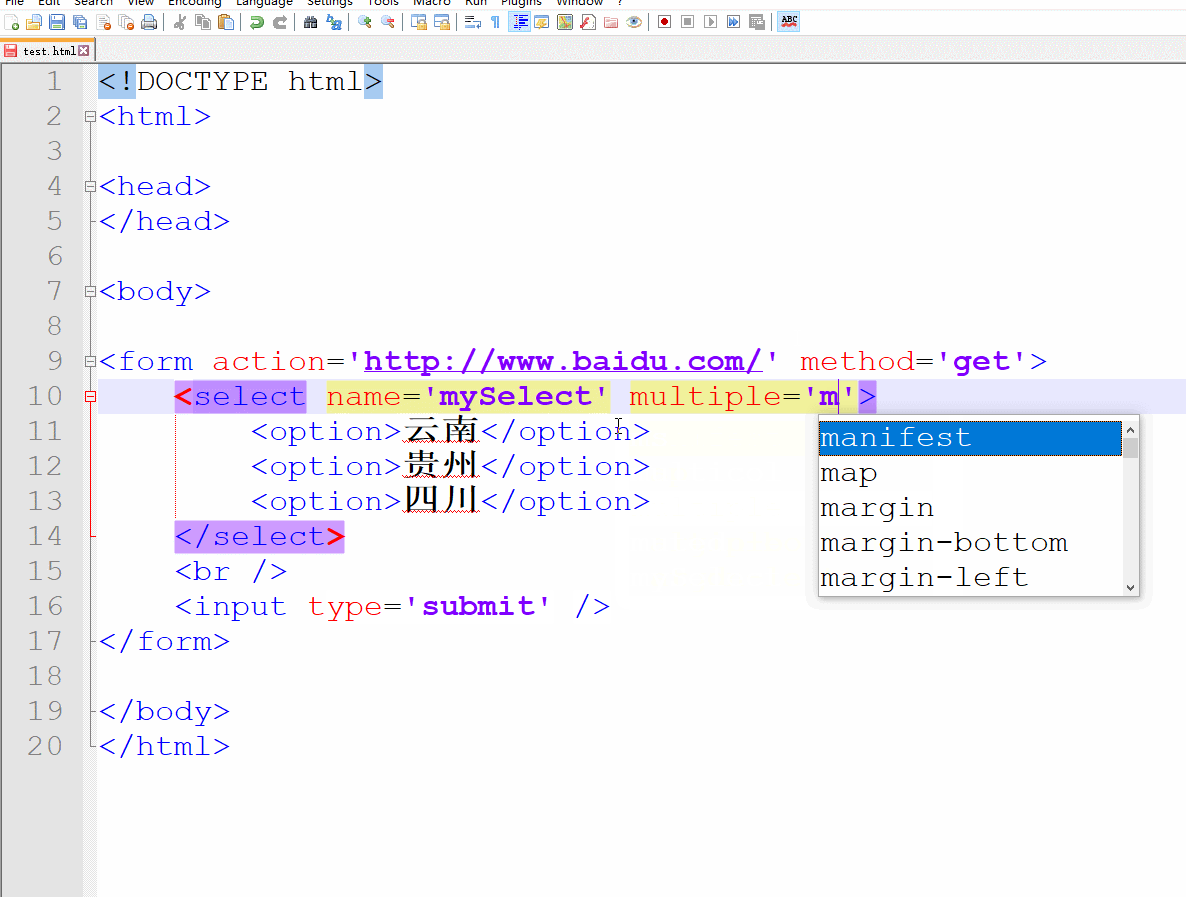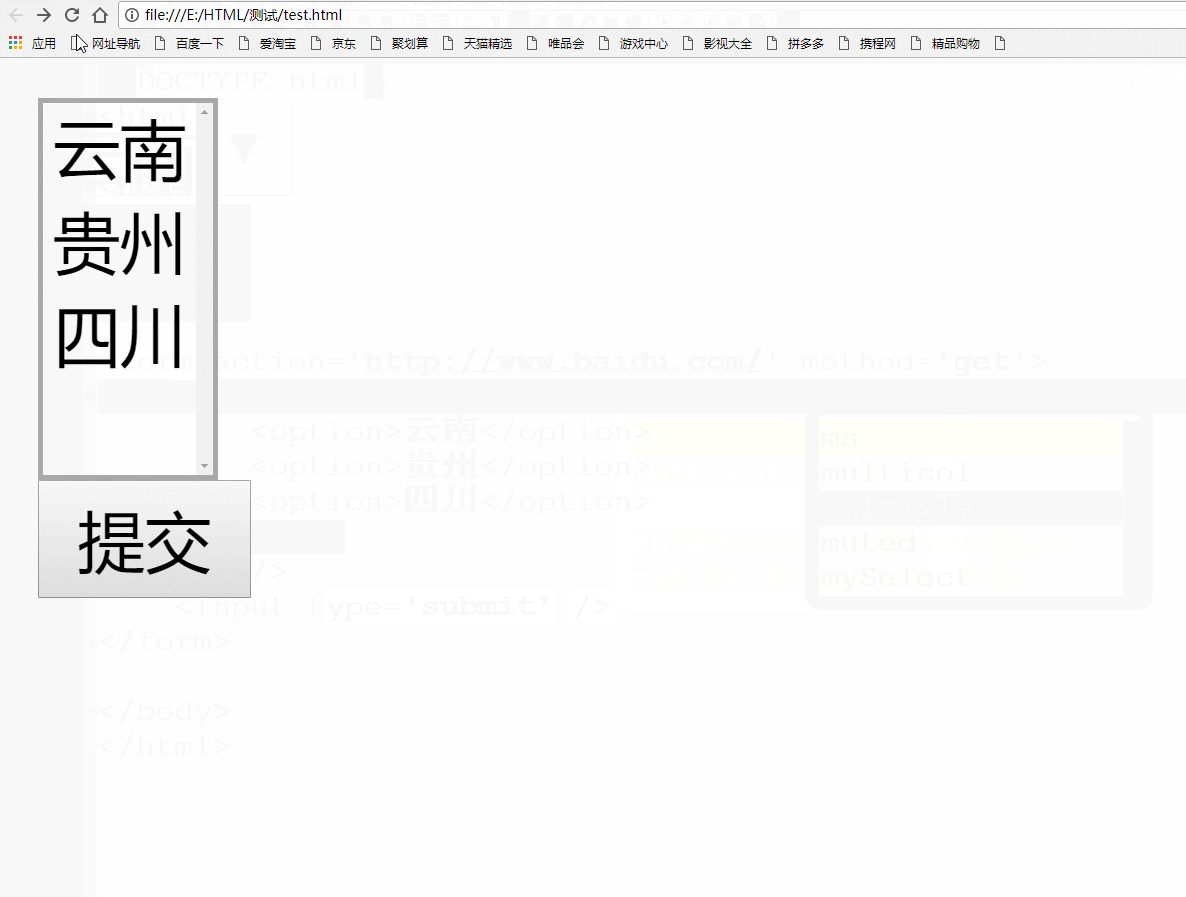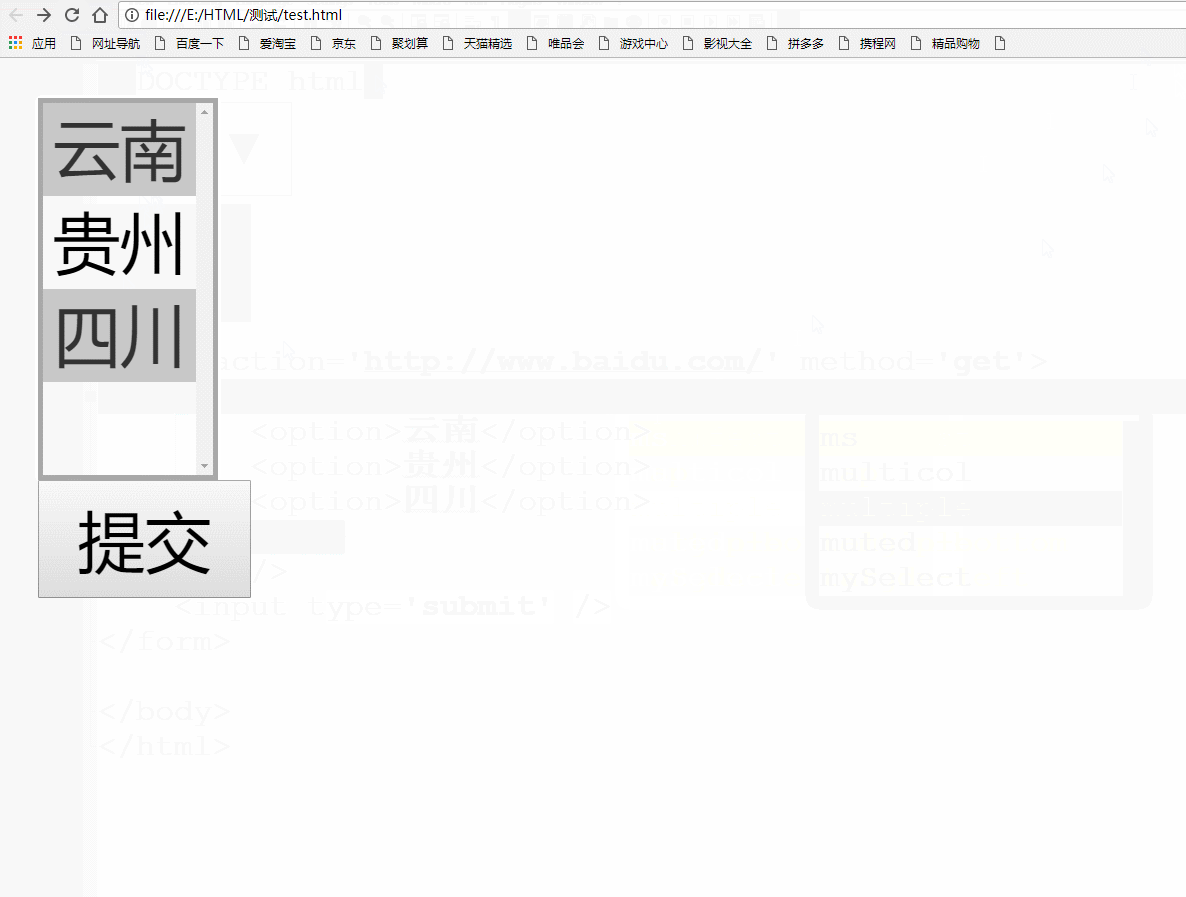
什么是下拉列表,废话不多说,我们先来看看它的真容吧:)
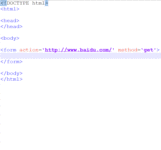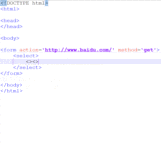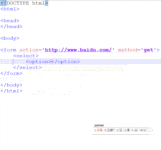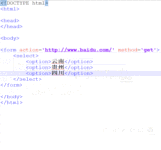
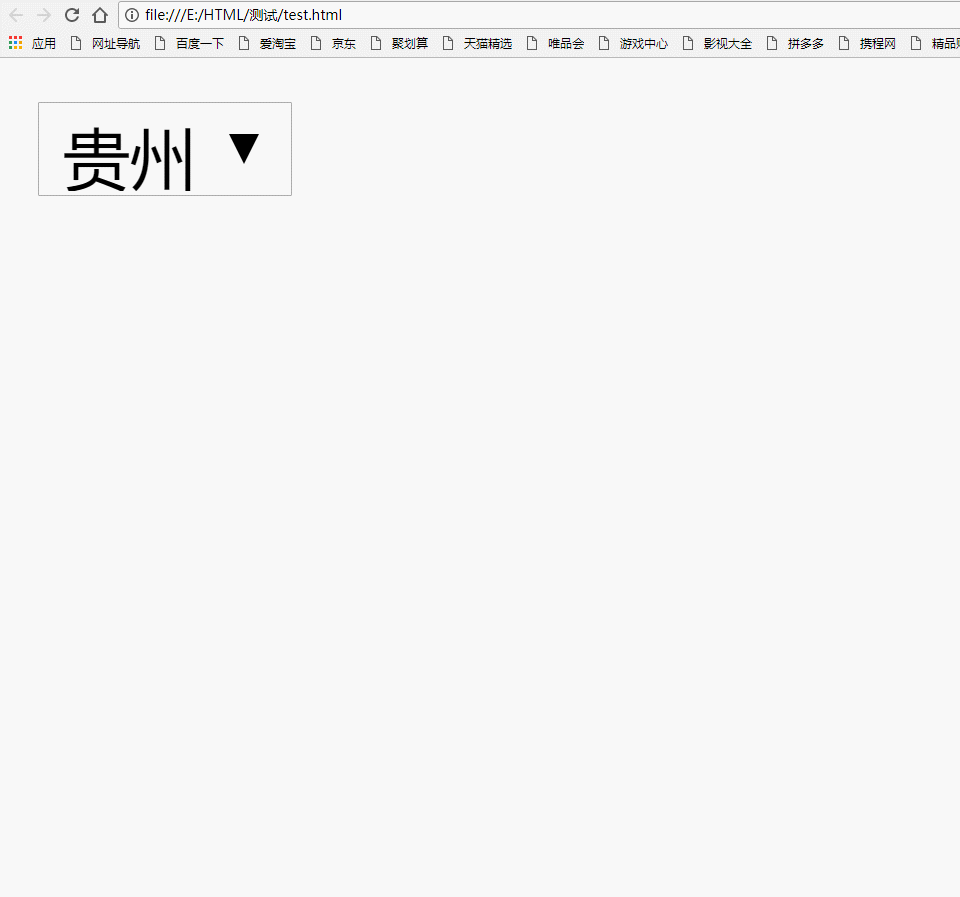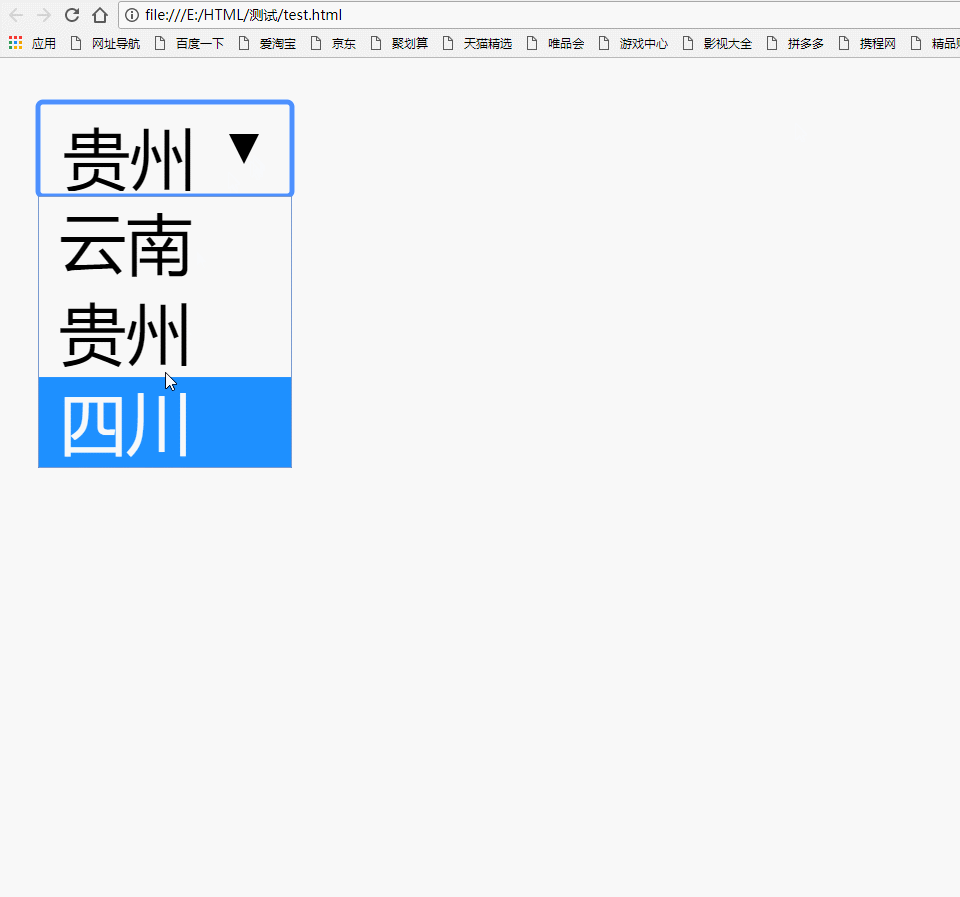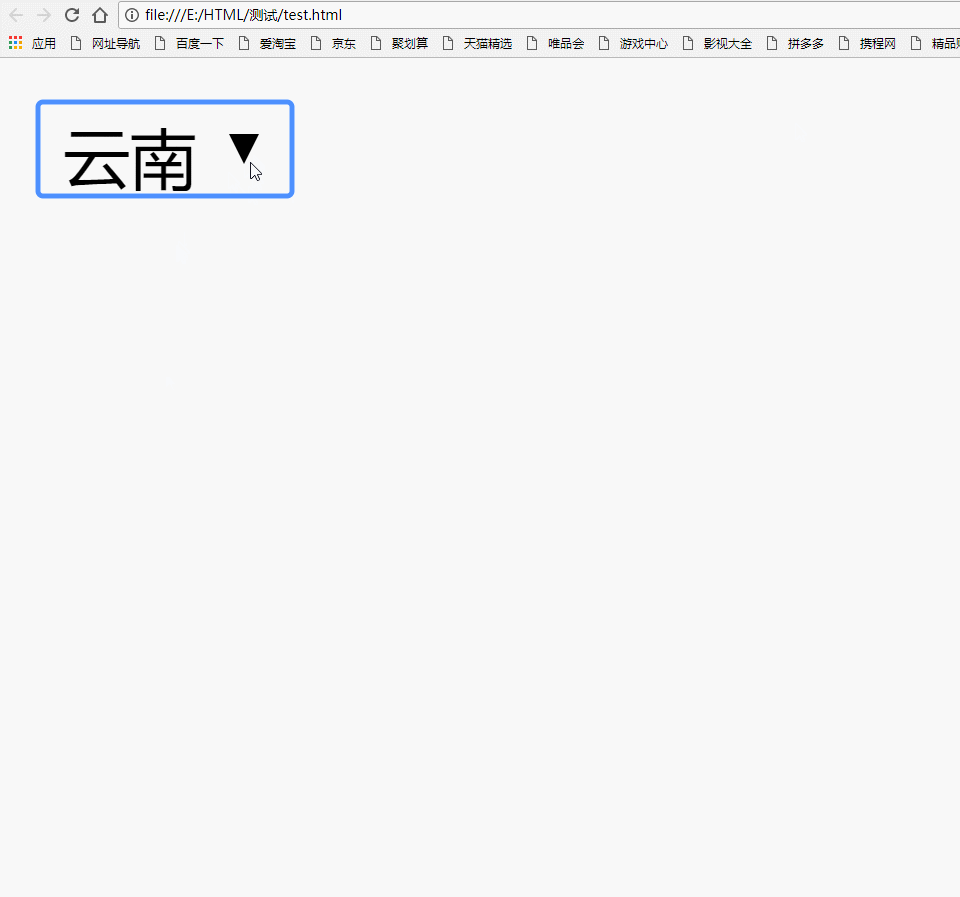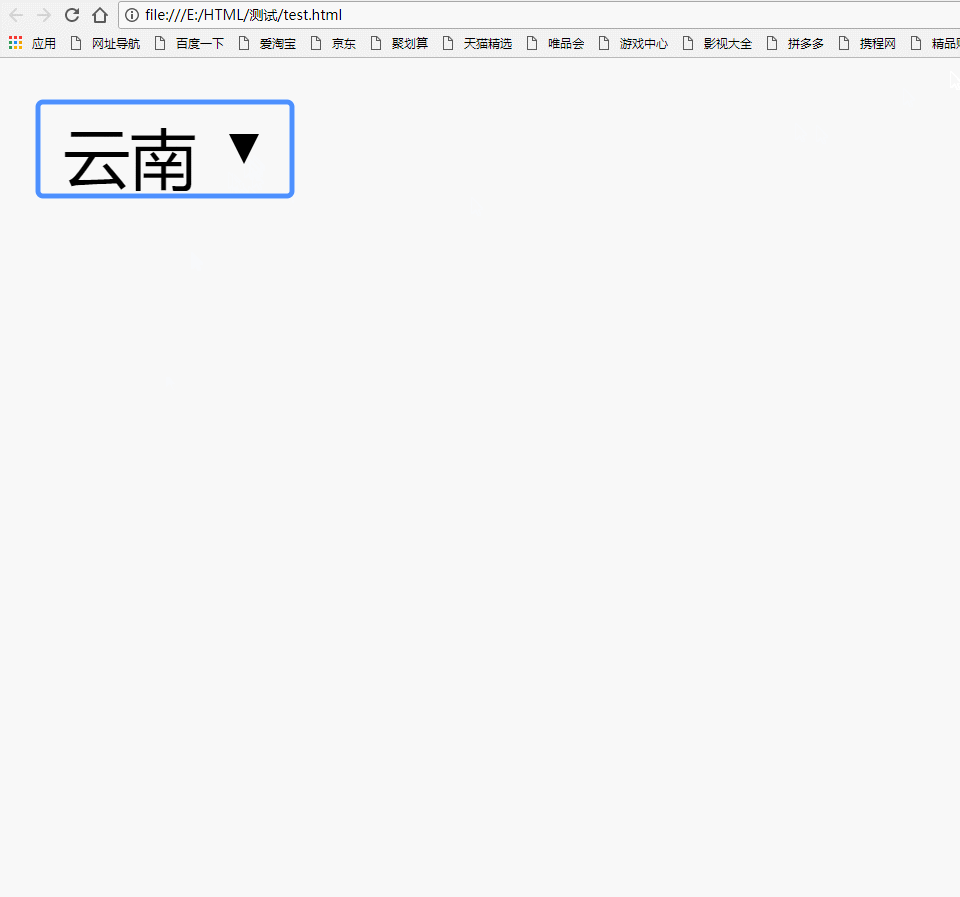
记住:一定不要忘记给select标签写上name属性,否则服务器无法接收到数据哦!



那!要是我们想让用户一下选择多个选项可不可以了?
当然可以!我们只要给select标签写上multiple属性就好。
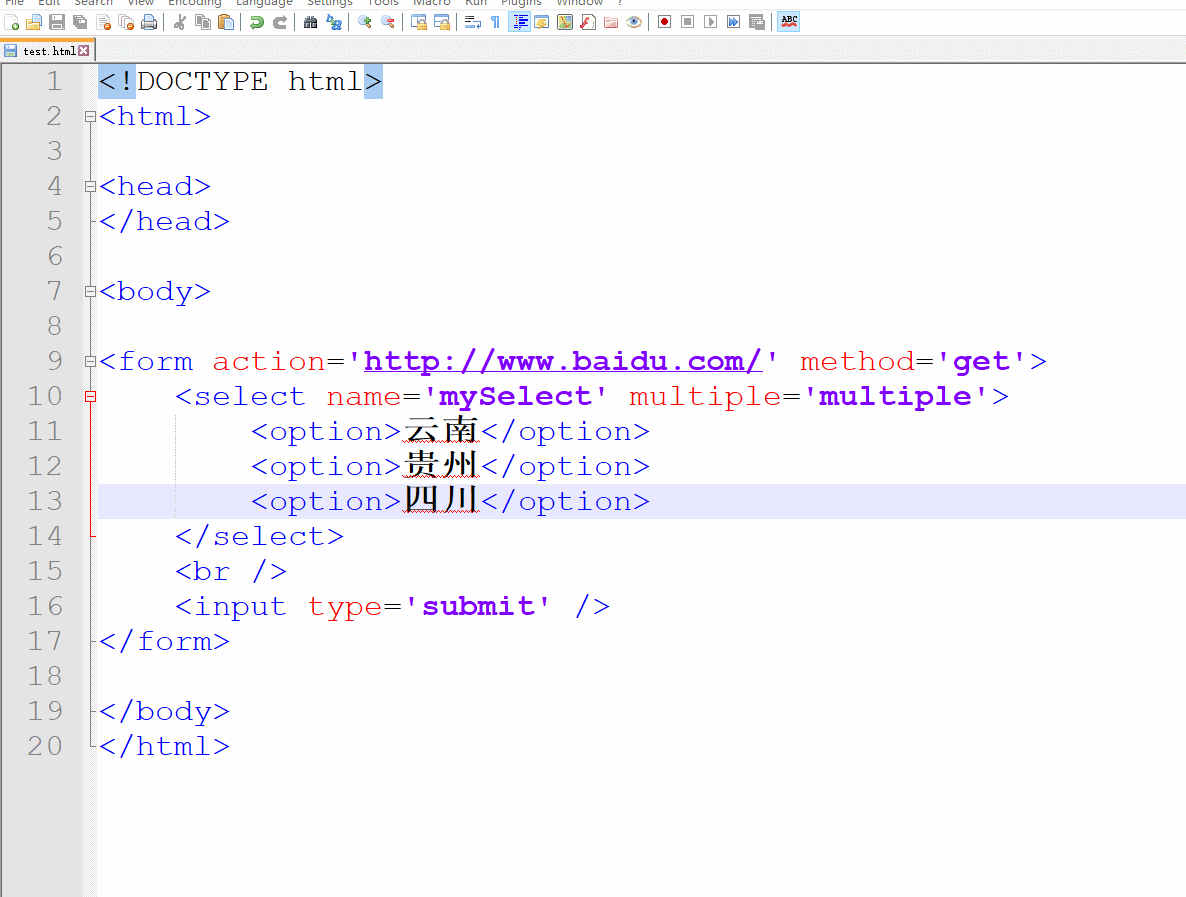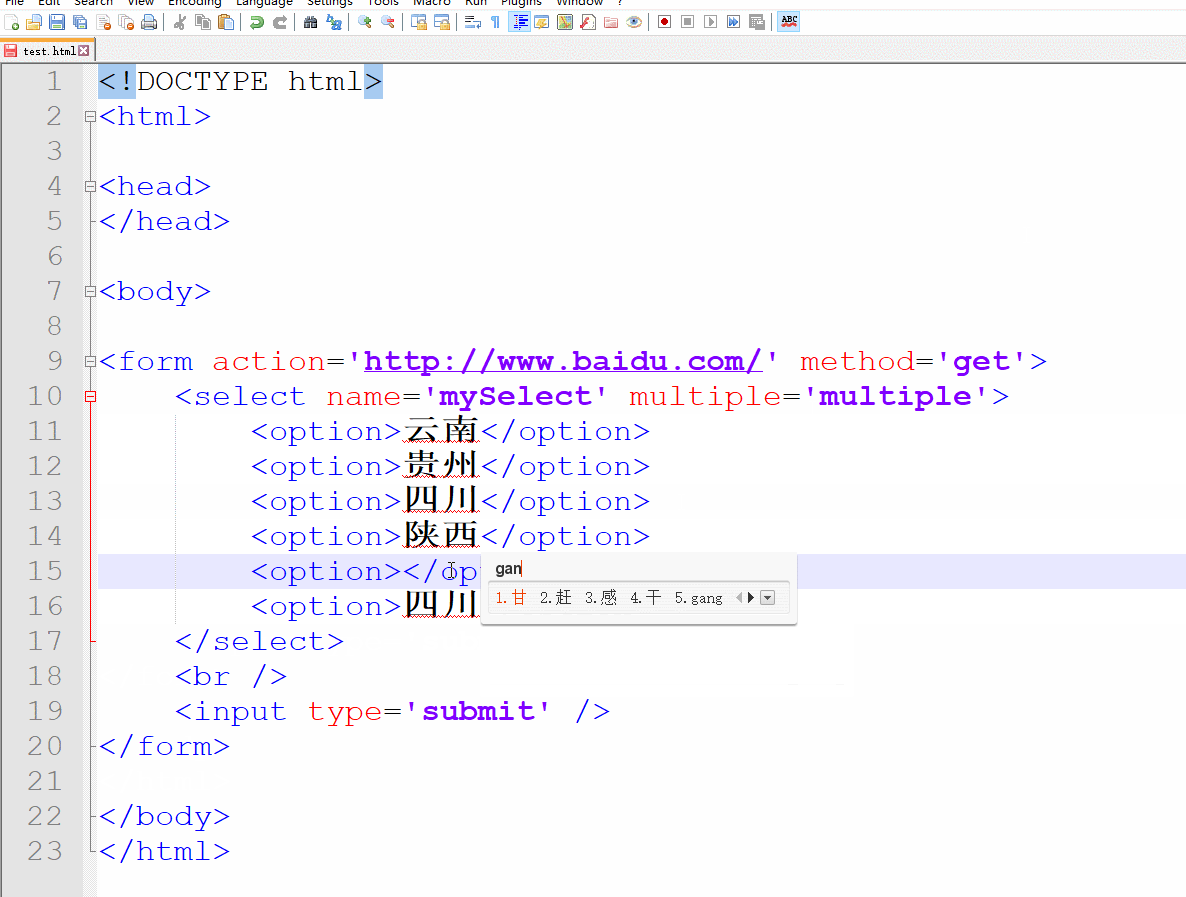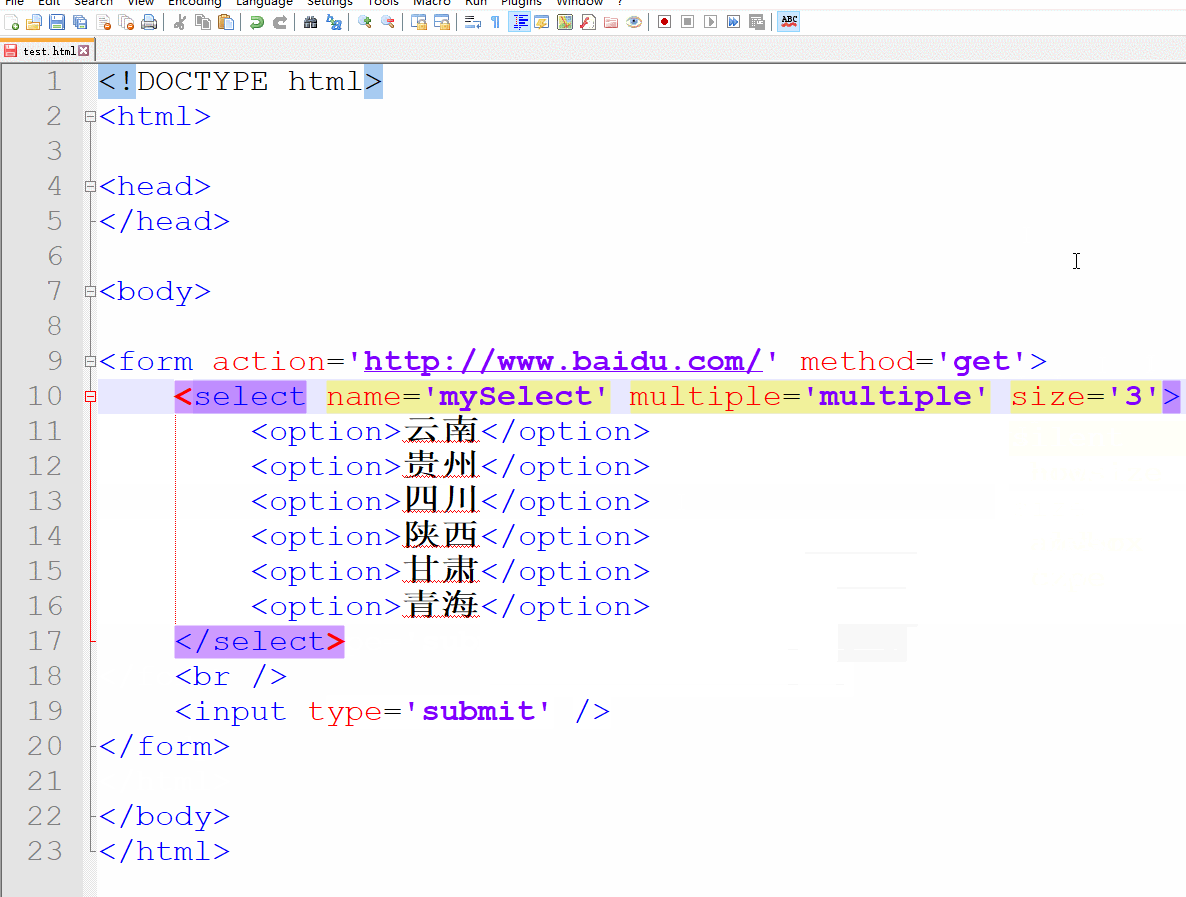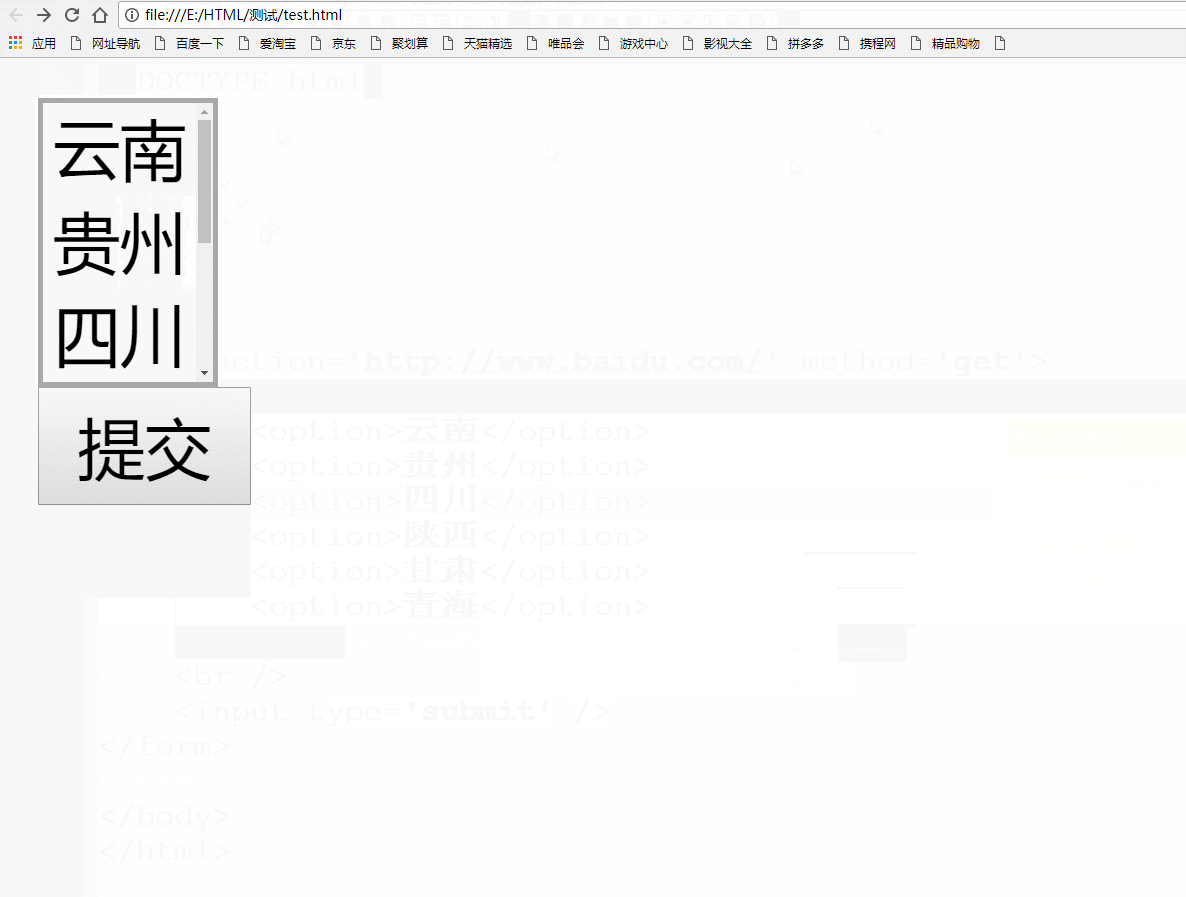
当列表的选项很多时,我们可以通过select标签的size属性来控制显示选项的数量。例如,这里我们只想让下拉列表显示3个选项。
我们还可以通过在select标签内嵌套optgroup标签来对下拉列表进行分组,即对option标签进行分组。
分好的每一个小组,又通过给optgroup标签设置label属性来命名。


最后,着重提醒一点,如果允许用户选择多项提交的话,select的name属性值一定要加上中括号,方便后端程序接收到多项数据!



















 1689
1689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











