






多模态
类型1: 输入与输出模态不同
类型2:多模态输入
类型3:多模态输出

多模态网络的要素

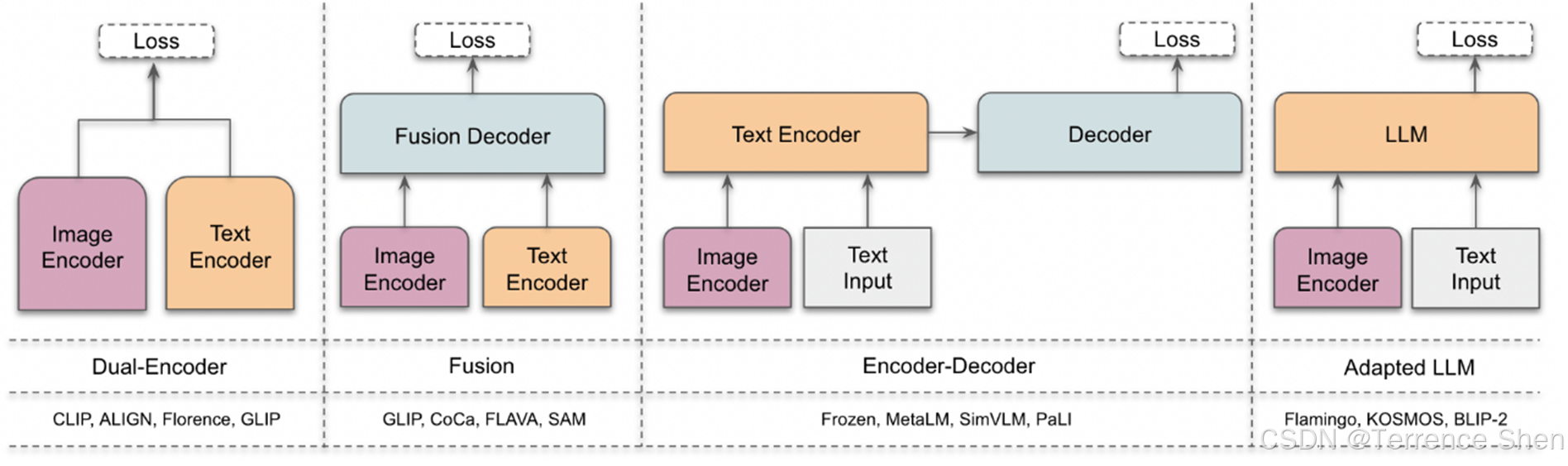
参考文献: Awais M, Naseer M, Khan S, et al. Foundational models defining a new era in vision: A survey and outlook. arXiv, 2023.
CLIP(Contrastive Language-Image Pre-training)
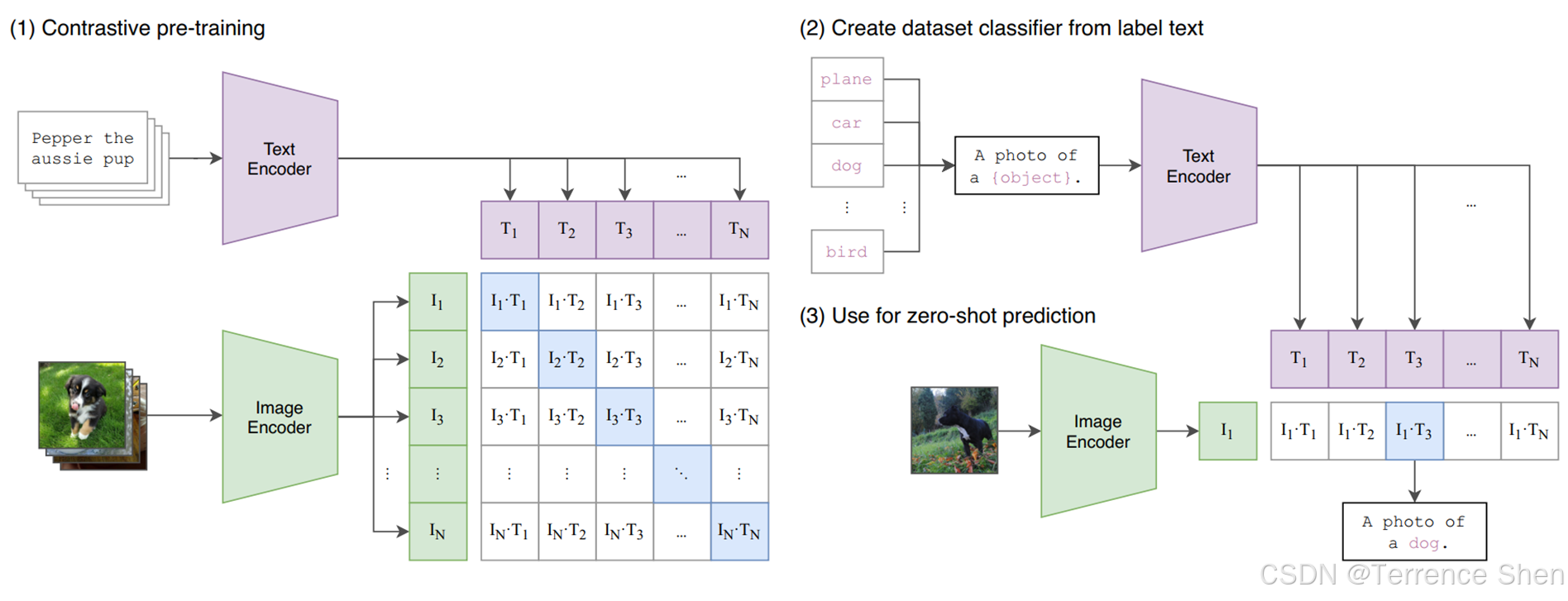
参考文献:Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision. ICML, 2021.
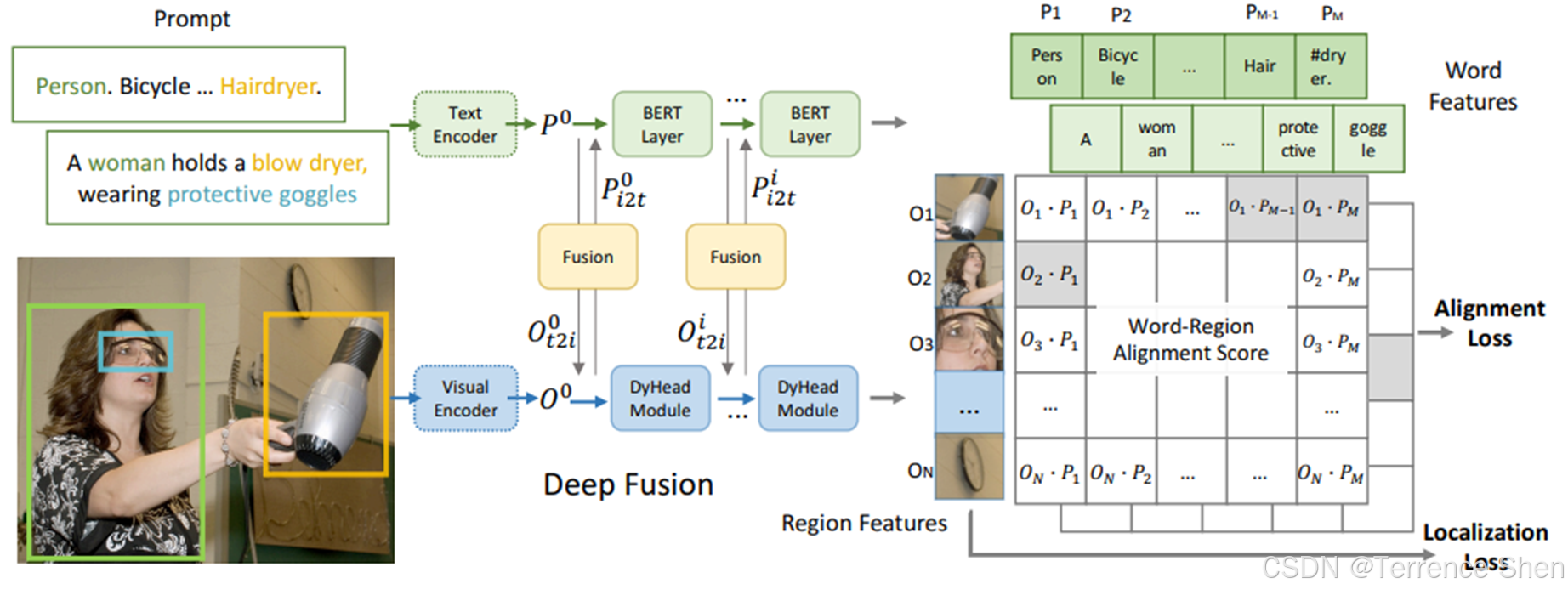
GLIP(Grounded Language-image pre-training)
Flamingo
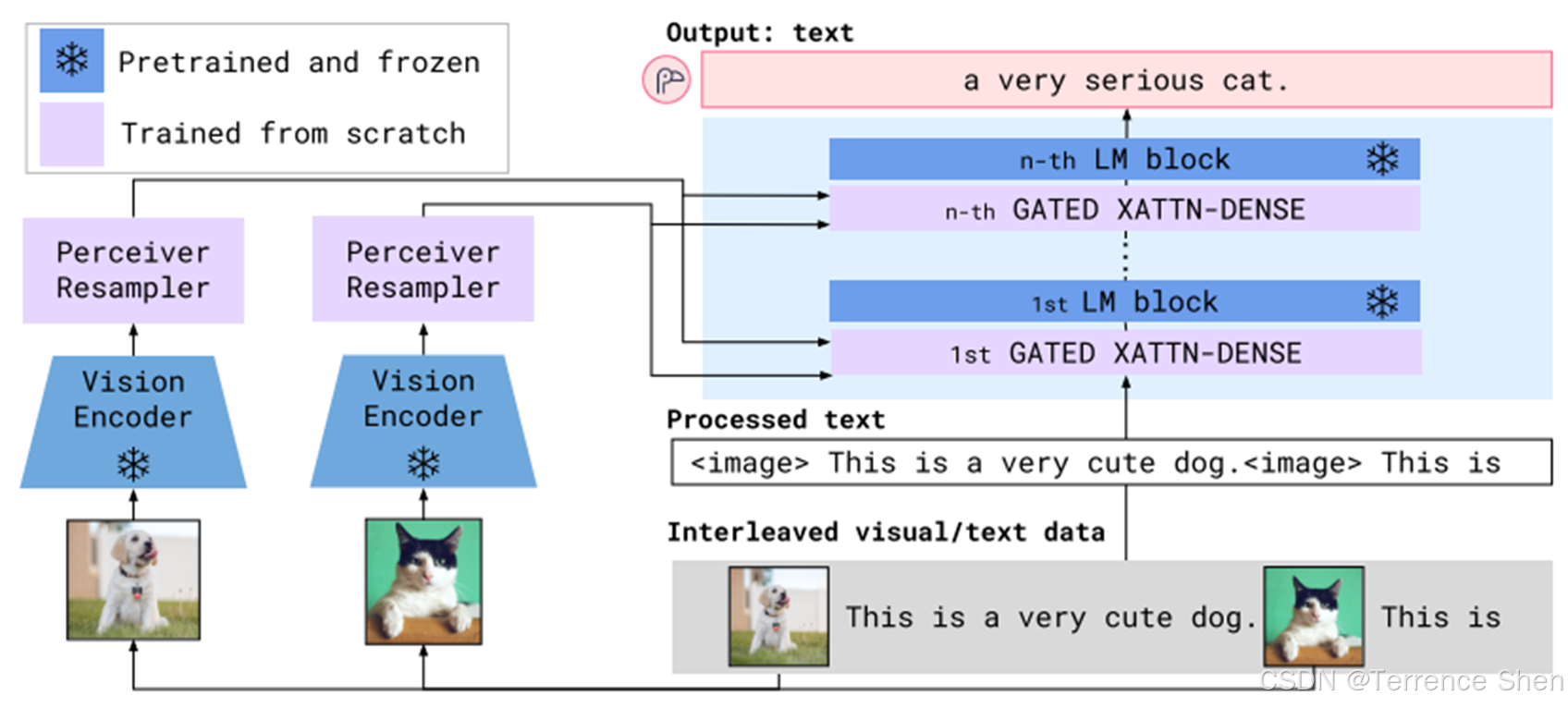
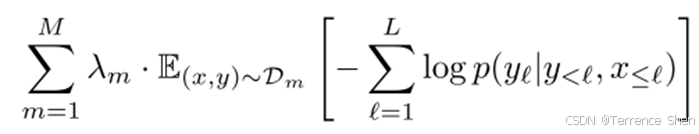
参考文献: Alayrac J B, Donahue J, Luc P, et al. Flamingo: a visual language model for few-shot learning. NIPS, 2022.
多模态视觉对话效果:

LLaVA
网络结构:
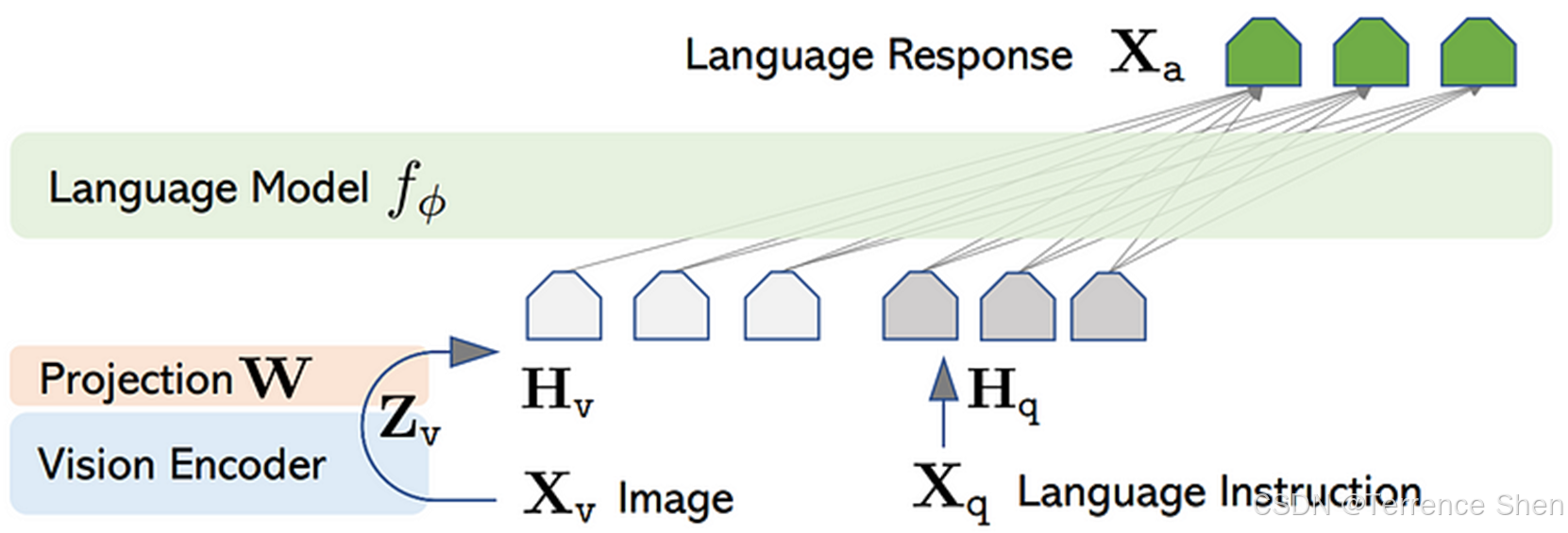
参考文献:Liu H, Li C, Wu Q, et al. Visual instruction tuning. arXiv, 2023.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











