






什么是大模型的微调
大模型的微调(Fine-tuning),通常是指在已经预训练好的大型语言模型(Large Language Models,简称LLMs)基础上,使用特定的数据集进行进一步的训练,以使模型适应特定的任务或领域。这个过程可以让模型学习到特定领域的知识,优化其在特定NLP任务中的表现,比如情感分析、实体识别、文本分类、对话生成等。
- 预训练模型:在微调之前,大模型通常已经经过大量的无监督预训练,这使得模型掌握了语言的基本统计特征和知识,具备了预测下一个词的能力。
- 任务特定的数据集:微调时,会使用与特定任务相关的标注数据对模型进行训练。这些数据提供了模型需要学习的特定领域的信息。
- 权重调整:微调过程中,模型的权重会根据特定任务的数据进行调整。这可以是全量参数更新(Full Fine-tuning),也可以是参数高效微调(Parameter-Efficient Fine-Tuning,PEFT),后者只更新模型中的一部分参数。
PEFT(Parameter-Efficient Fine-Tuning)
与传统的微调方法相比,PEFT有效地降低了计算和内存需求,因为它只对模型参数的一小部分进行微调,同时冻结大部分预训练网络。这种策略减轻了大语言模型灾难性的遗忘,并显著降低了计算和存储成本。
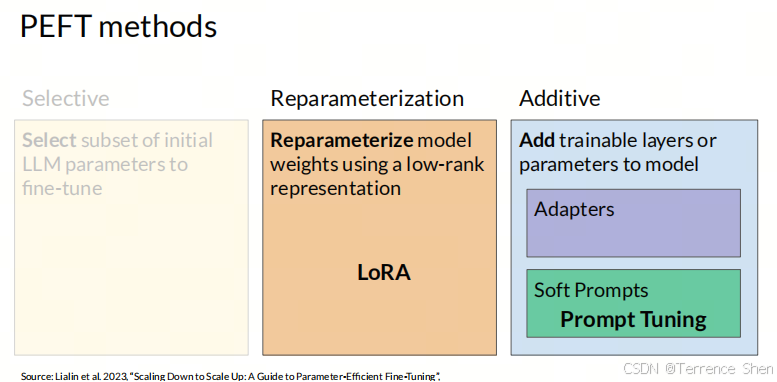
PEFT的主要方法 见 Adapters 和 Soft prompts 的链接。
Adapters
LoRA是现在很火爆的概念,当然这不是唯一。 是非常流行的PEFT方法,属于Adapters的一种。 Adapters是一种非常好的微调大模型的方法,可以在不改变原始LLM参数的情况下,增加新的任务。
LoRA
LoRA(Low-Rank Adapter)1 是最流行的 PEFT 方法之一,如果你刚开始使用 PEFT,它是一个很好的起点。它最初是为大型语言模型开发的,但由于其效率和有效性,它是一种非常流行的扩散模型训练方法。
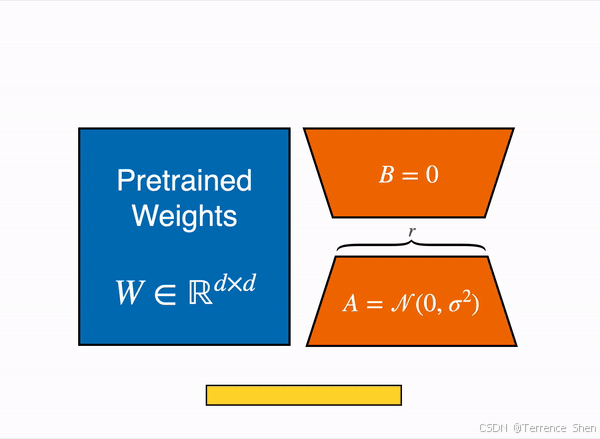
LoRA 通过低秩分解用两个较小的矩阵(称为更新矩阵)表示权重更新 ∆W。这些新矩阵可以训练以适应新数据,同时保持参数总数较低。原始权重矩阵保持冻结状态,不会收到任何进一步的更新。为了产生最终结果,将原始权重和额外调整后的权重组合在一起。你还可以将适配器权重与基础模型合并,以消除推理延迟。
W_finetuning= W_pretrained + ∆W
∆W= B @ A
三者维度分别是(dXd, dXr, rXd), 所以如果r<<d的话,
2rd一定远小于 d的平方,参数量显然就大大下降了。
QLoRA
QLoRA(Quantized Low-Rank Adapter)2是一种新型的微调大型语言模型(LLM)的方法,它能够在减少内存使用的同时保持模型性能。这一技术由华盛顿大学提出,主要针对内存需求巨大的问题,使得在单个48GB GPU上微调650亿个参数的模型成为可能,同时保持完整的16位微调任务性能。
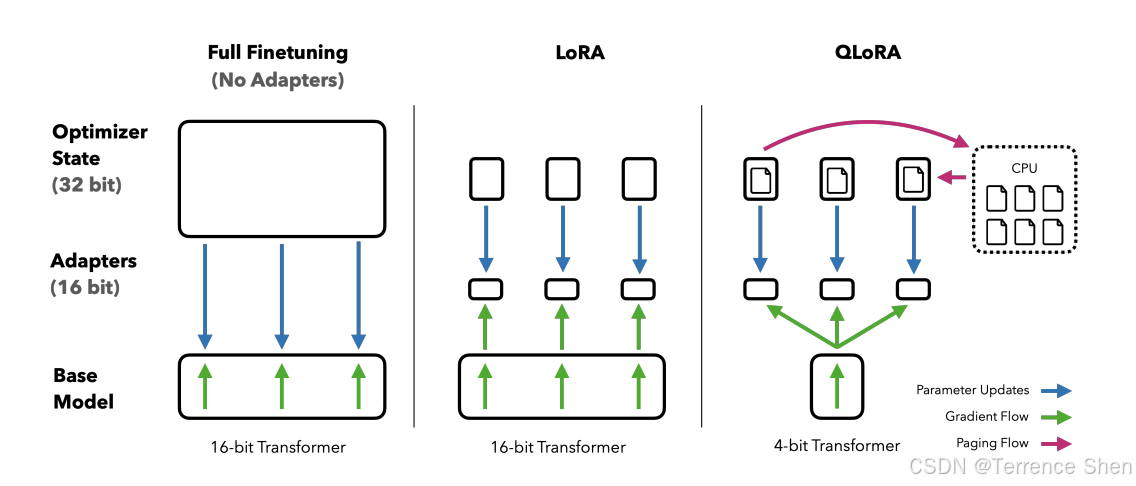
QLoRA的工作原理是先将预训练语言模型进行4位量化,显著减少模型的内存占用,然后使用低阶适配器(LoRA)方法对量化的模型进行微调。这种方法不仅减少了模型的体积,提高了速度,而且还保留了原始预训练语言模型的大部分准确性。
AdaLoRA
Ada就是Adaptive适应性,自适应的意思。
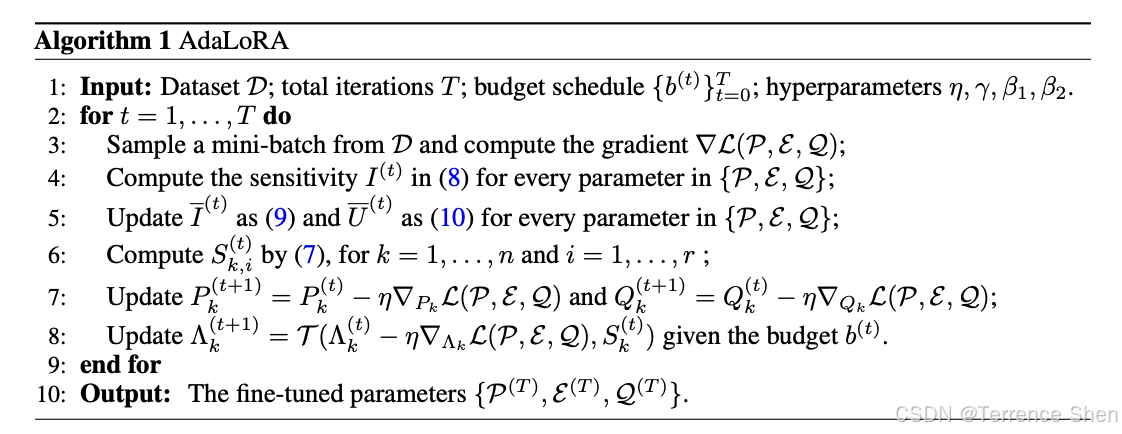
AdaLoRA(Adaptive Low-Rank Adapter)3是一种用于高效微调大型预训练语言模型的方法,它能够自适应地根据权重矩阵的重要性来分配参数预算。这种方法通过将权重矩阵的增量更新参数化为奇异值分解(Singular Value Decomposition, SVD)的形式,有效地剪枝不重要更新的奇异值,减少它们的参数预算,同时避免了进行密集的精确SVD计算。
AdaLoRA包含两个主要模块:
- SVD形式参数更新:直接将增量矩阵Δ参数化为SVD的形式,从而避免了在训练过程中进行SVD计算带来的资源消耗;
- 基于重要程度的参数分配:基于新的重要性度量标准,动态地在增量矩阵之间分配参数预算,通过操纵奇异值来实现


















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











