







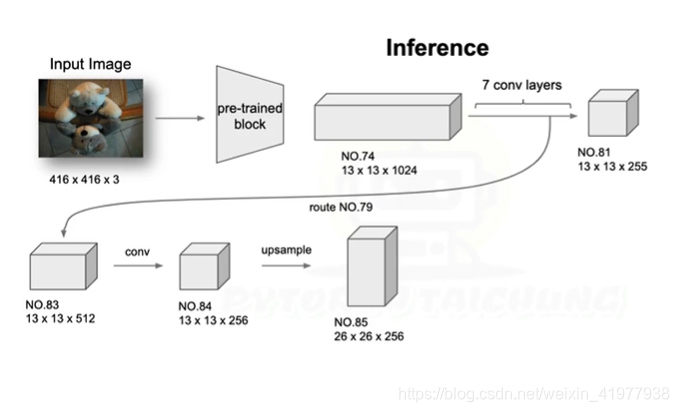
为什么输入尺度416*416:经过下采样得到13*13,有中心点,作者发现大目标中心经常在中心点上,而448*448经过卷积得到
14*14无中心点。
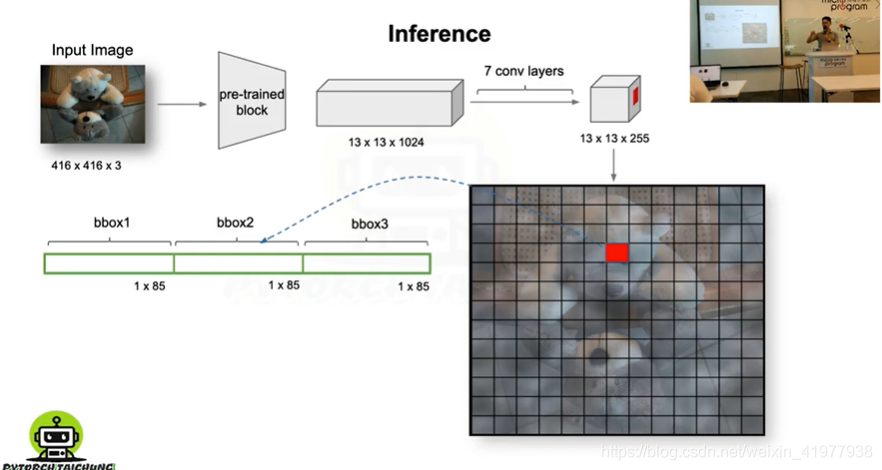
深度详解,为什么是255深度
实际上是3个bbox
每个85深度包含:(x,y,w,h,s,cls1_s,cls2_s....,cls80_s)s代表有没有物体的几率,cls_s代表为每一类的概率
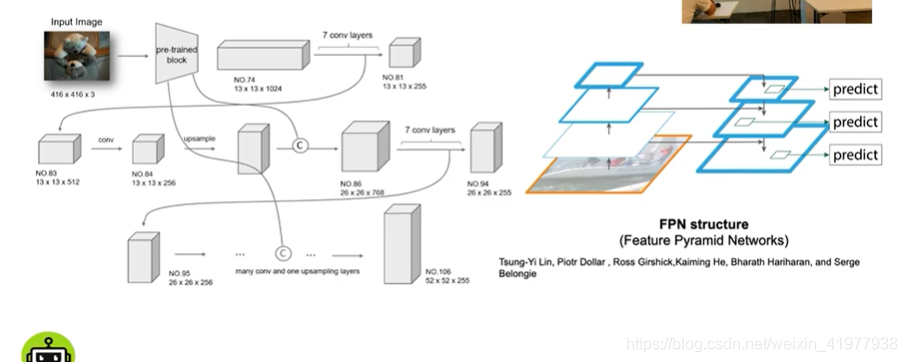
结构图
类fpn结构 ,concat各个大小的feature map
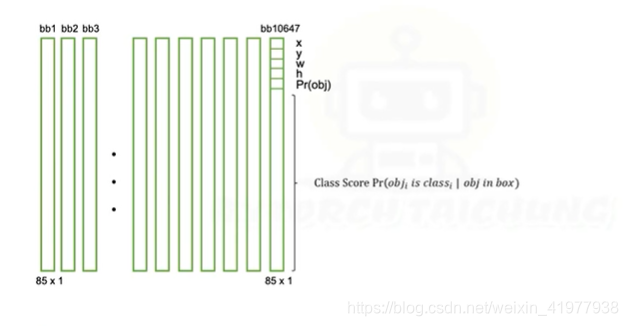
yolov3一次产生共多少bbox?
3*13*13+
3*26*26+
3*52*52=10647

之后经过s的值筛选+non—maximum筛选
每个bbox向量里有什么?以及运算的过程
1。长度的含义
probj:有没有物体
2.第二步 找出最大的cls值(蓝色的)
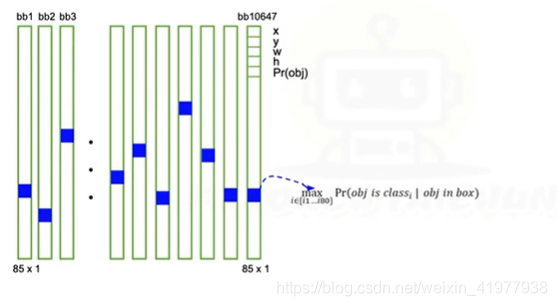
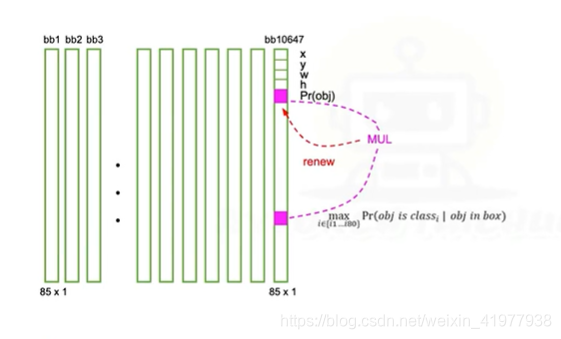
3第三步,将Pr_obj和Pr_max_cls相乘,得到的值更新到PR_obj的位置

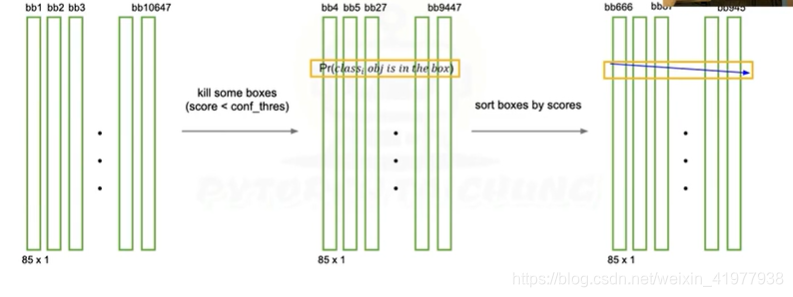
4第四步,删掉score小于conf_thres的,然后排序,最后做非极大值抑制
loss对比(v1和v3)
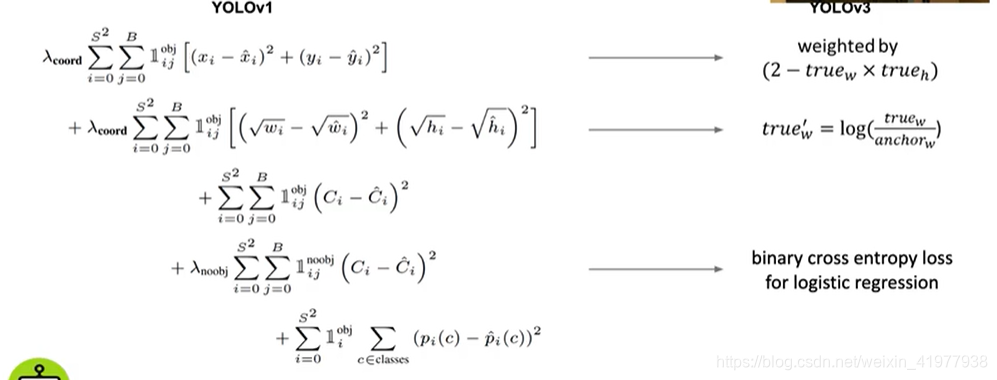

















 5158
5158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









