







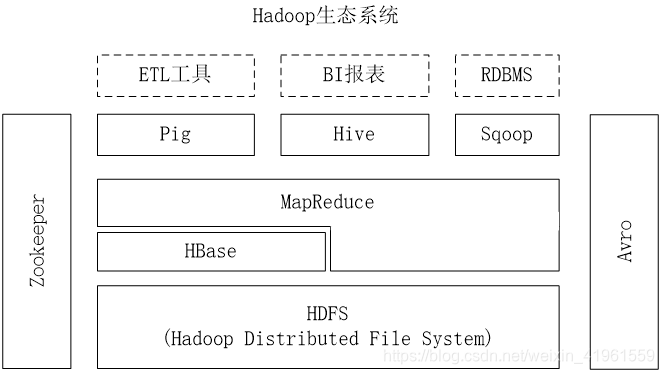
1概述
1.1 从BigTable说起
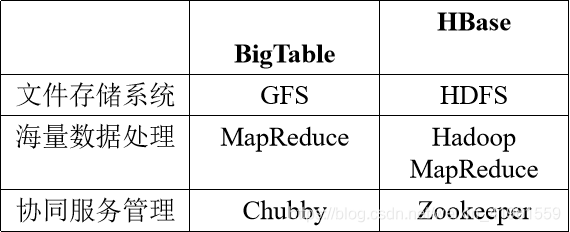
BigTable是一个分布式存储系统,起初用于解决典型的互联网搜索问题。
-
建立互联网索引
① 爬虫持续不断地抓取新页面,这些页面每页一行地存储到BigTable里
② MapReduce计算作业运行在整张表上,生成索引,为网络搜索应用做准备 -
搜索互联网
③ 用户发起网络搜索请求
④ 网络搜索应用查询建立好的索引,从BigTable得到网页
⑤ 搜索结果提交给用户
BigTable是一个分布式存储系统,利用谷歌提出的MapReduce分布式并行计算模型来处理海量数据。
使用谷歌分布式文件系统GFS作为底层数据存储。
采用Chubby提供协同服务管理。
可以扩展到PB级别的数据和上千台机器,具备广泛应用性、可扩展性、高性能和高可用性等特点。
谷歌的许多项目都存储在BigTable中,包括搜索、地图、财经、打印、社交网站Orkut、视频共享网站YouTube和博客网站Blogger等。
1.2 HBase简介
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。
HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。
关系数据库已经流行很多年,并且Hadoop已经有了HDFS和MapReduce,为什么需要HBase?
- Hadoop可以很好地解决大规模数据的离线批量处理问题,但是,受限于Hadoop MapReduce编程框架的高延迟数据处理机制,使得Hadoop无法满足大规模数据实时处理应用的需求。
- HDFS面向批量访问模式,不是随机访问模式。
- 传统的通用关系型数据库无法应对在数据规模剧增时导致的系统扩展性和性能问题(分库分表也不能很好解决)。
- 传统关系数据库在数据结构变化时一般需要停机维护;空列浪费存储空间。
- 因此,业界出现了一类面向半结构化数据存储和处理的高可扩展、低写入/查询延迟的系统,例如,键值数据库、文档数据库和列族数据库(如BigTable和HBase等)。
- HBase已经成功应用于互联网服务领域和传统行业的众多在线式数据分析处理系统中。
1.3 HBase与传统关系数据库的对比分析

① 数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase则采用了更加简单的数据模型,它把数据存储为未经解释的字符串
② 数据操作:关系数据库中包含了丰富的操作,其中会涉及复杂的多表连接。HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为HBase在设计上就避免了复杂的表和表之间的关系
③ 存储模式:关系数据库是基于行模式存储的。HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的
④ 数据索引:关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。HBase只有一个索引——行键,通过巧妙的设计,HBase中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来
⑤ 数据维护:在关系数据库中,更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留
⑥ 可伸缩性:关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反,HBase和BigTable这些分布式数据库就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩
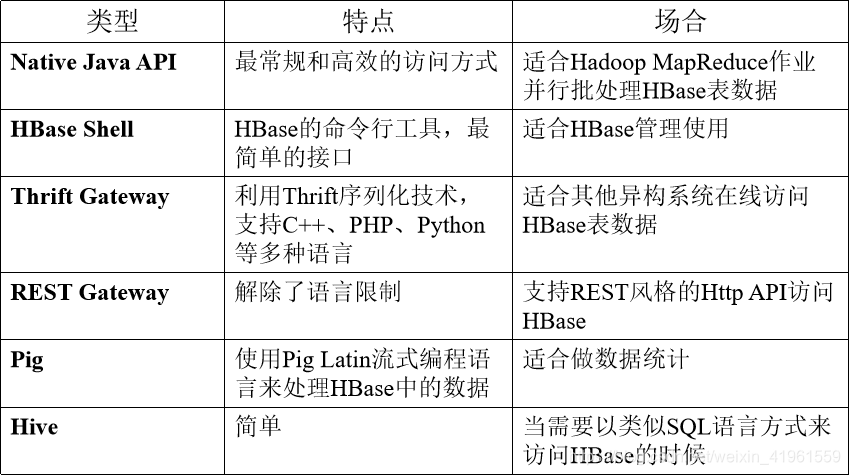
2 HBase访问接口
3 HBase数据模型
3.1 数据模型概述
- HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳
- 每个值是一个未经解释的字符串,没有数据类型
- 用户在表中存储数据,每一行都有一个可排序的行键和任意多的列 <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









