







 本文介绍了如何使用StyleGAN Encoder通过随机剪裁方法找到真实人脸对应的特征码。详细阐述了该方法的原理,并提到了相关开源项目和核心代码结构。文章还提及了运行项目的系统需求、资源下载及源代码修改等注意事项。
本文介绍了如何使用StyleGAN Encoder通过随机剪裁方法找到真实人脸对应的特征码。详细阐述了该方法的原理,并提到了相关开源项目和核心代码结构。文章还提及了运行项目的系统需求、资源下载及源代码修改等注意事项。
在上一篇文章中,我们用了四种方法来寻找真实人脸对应的特征码,都没有成功,内容请参考:
https://blog.youkuaiyun.com/weixin_41943311/article/details/102952854
而事实上,这个问题在2017年2月就已经被美国加州大学圣迭戈分校的Zachary C Lipton和Subarna Tripathi解决,他们的研究成果发表在下面的网址上:
https://arxiv.org/abs/1702.04782
也可以到百度网盘上下载英文论文《PRECISE RECOVERY OF LATENT VECTORS FROM GENERATIVE ADVERSARIAL NETWORKS》:
https://pan.baidu.com/s/1xCWTD5CA615CHOUS-9ToNA
提取码: wkum
他们把解决办法称之为“stochastic clipping”(随机剪裁),其基本原理大致是:特征码(特征向量)中每个数值通常处于一个有限的空间内,论文指出通常分布在[-1.0, 1.0]这个变动区间内,因此可以从某个特征向量开始(甚至于从全零向量开始),先把超出[-1.0, 1.0]范围的数值剪裁到[-1.0, 1.0]区间,然后以这个特征向量为基准值(平均值),在[-1.0, 1.0]这个变动区间内,按正态分布的规律随机取得新向量,计算新向量通过GAN生成的新图片与原图片之间的损失函数,然后用梯度下降的方法寻找使损失函数最小的最优解。论文指出,他们可以使损失函数降低到0,这样就找到了真实人脸对应的“相当精确”的特征码。
基于这个思想,在github.com 上有若干开源项目提供了源代码,我选用的开源项目是:pbaylies/stylegan-encoder,对应的网址是:
https://github.com/pbaylies/stylegan-encoder
在这个开源项目里,作者把变动区间调整为[-2.0, 2.0]。有读者指出更好的变动区间是 [-0.25, 1.5],在这个区间内能够取得更优的质量。
这个开源项目实现的效果如下图所示(左一为源图;中间是基于预训练ResNet从源图“反向”生成dlatents,然后再用这个dlatents生成的“假脸”图片;右一是经随机剪裁方法最终找到的人脸dlatens,并用这个人脸dlatents生成的极为接近源图的“假脸”):

由于我们得到了人脸对应的dlatents,因此可以操纵这个dlatents,从而可以改变人脸的面部表情。
我们可以按下图所示把整个项目下载到本地,并解压缩之:
在工作目录下,新建.\raw_images目录,并把需要提取特征码的真实人脸图片copy到这个目录下。
使用时,可以按一下步骤操作:
(一)从图片中抽取并对齐人脸:
python align_images.py raw_images/ aligned_images/
(二)找到对齐人脸图片的latent表达:
python encode_images.py aligned_images/ generated_images/ latent_representations/
这个StyleGAN Encoder的核心代码结构如下图所示:

使用中有一些问题要注意:
(1)对显卡内存的要求较高,主页中注明的系统需求如下:
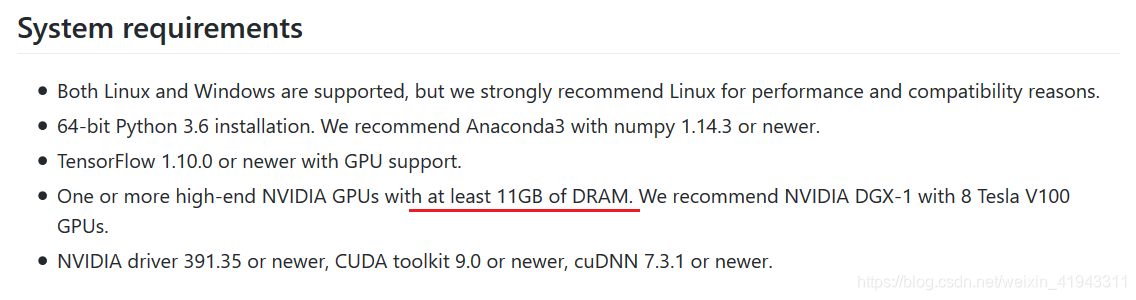
实测,Windows 10 + NVIDIA GeForce RTX 2080Ti 可以运行本项目。
(2)由于不能方便地访问drive.google.com等网站,源代码中的部分资源无法获得,需要提前下载这些资源并修改源代码,包括:
(2.1)预训练的resnet50模型,用于从源图生成优化迭代的初始dlatents,可以从百度网盘下载:
https://pan.baidu.com/s/19ZdGEL5d9J1bpszTJsu0Yw
提取码: zabp
下载以后,将文件copy到工作目录的.\data下
(2.2)预训练的StyleGAN模型,用于从dlatents生成“假”的人脸图片,可以从百度网盘下载:
https://pan.baidu.com/s/1huez99L92_mqbP9sMev5Mw
提取码: jhb5
下载以后,将文件copy到工作目录的.\models下
对应修改的文件是:.\encode_images.py
对应修改的内容如下:
"""
with dnnlib.util.open_url(args.model_url, cache_dir=config.cache_dir) as f:
generator_network, discriminator_network, Gs_network = pickle.load(f)
"""
# 加载StyleGAN模型
Model = './models/karras2019stylegan-ffhq-1024x1024.pkl'
model_file = glob.glob(Model)
if len(model_file) == 1:
model_file = open(model_file[0], "rb")
else:
raise Exception('Failed to find the model')
generator_network, discriminator_network, Gs_network = pickle.load(model_file)
(2.3)预训练的VGG16模型,用于从图片提取features,可以从百度网盘下载:
https://pan.baidu.com/s/1vP6NM9-w4s3Cy6l4T7QpbQ
提取码: 5qkp
下载以后,将文件copy到工作目录的.\models下
对应修改的文件是:.\encode_images.py
对应修改的内容如下:
perc_model = None
if (args.use_lpips_loss > 0.00000001): # '--use_lpips_loss', default = 100
"""
with dnnlib.util.open_url('https://drive.google.com/uc?id=1N2-m9qszOeVC9Tq77WxsLnuWwOedQiD2', cache_dir=config.cache_dir) as f:
perc_model = pickle.load(f)
"""
# 加载VGG16 perceptual模型
Model = './models/vgg16_zhang_perceptual.pkl'
model_file = glob.glob(Model)
if len(model_file) == 1:
model_file = open(model_file[0], "rb")
else:
raise Exception('Failed to find the model')
perc_model = pickle.load(model_file)解决以上问题,基本就可以顺利运行了!
完整的带中文注释的源代码如下:
.\encode_images.py
import os
import argparse
import pickle
from tqdm import tqdm
import PIL.Image
import numpy as np
import dnnlib
import dnnlib.tflib as tflib
import config
from encoder.generator_model import Generator
from encoder.perceptual_model import PerceptualModel, load_images
from keras.models import load_model
import glob
import random
def split_to_batches(l, n):
for i in range(0, len(l), n):
yield l[i:i + n]
def main():
parser = argparse.ArgumentParser(description='Find latent representation of reference images using perceptual losses', formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('src_dir', help='Directory with images for encoding')
parser.add_argument('generated_images_dir', help='Directory for storing generated images')
parser.add_argument('dlatent_dir', help='Directory for storing dlatent representations')
parser.add_argument('--data_dir', default='data', help='Directory for storing optional models')
parser.add_argument('--mask_dir', default='masks', help='Directory for storing optional masks')
parser.add_argument('--load_last', default='', help='Start with embeddings from directory')
parser.add_argument('--dlatent_avg', default='', help='Use dlatent from file specified here for truncation instead of dlatent_avg from Gs')
parser.add_argument('--model_url', default='https://drive.google.com/uc?id=1MEGjdvVpUsu1jB4zrXZN7Y4kBBOzizDQ', help='Fetch a StyleGAN model to train on from this URL') # karras2019stylegan-ffhq-1024x1024.pkl
parser.add_argument('--model_res', default=1024, help='The dimension of images in the StyleGAN model', type=int)
parser.add_argument('--batch_size', default=1, help='Batch size for generator and perceptual model', type=int)
# Perceptual model params
parser.add_argument('--image_size', default=256, help='Size of images for perceptual model', type=int)
parser.add_argument('--resnet_image_size', default=256, help='Size of images for the Resnet model', type=int)
parser.add_argument('--lr', default=0.02, help='Learning rate for perceptual model', type=float)
parser.add_argument('--decay_rate', default=0.9, help='Decay rate for learning rate', type=float)
parser.add_argument('--iterations', default=100, help='Number of optimization steps for each batch', type=int)
parser.add_argument('--decay_steps', default=10, help='Decay steps for learning rate decay (as a percent of iterations)', type=float)
parser.add_argument('--load 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8950
8950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









