







 本文详细介绍了如何使用PyTorch的torchvision.datasets加载预定义数据集如CIFAR10,以及如何通过torch.utils.data.Dataset自定义数据集。通过示例展示了数据的可视化方法,并解释了DataLoader的作用,它能按批次加载数据并支持多进程加速。此外,还讨论了数据集的结构和如何进行数据转换。
本文详细介绍了如何使用PyTorch的torchvision.datasets加载预定义数据集如CIFAR10,以及如何通过torch.utils.data.Dataset自定义数据集。通过示例展示了数据的可视化方法,并解释了DataLoader的作用,它能按批次加载数据并支持多进程加速。此外,还讨论了数据集的结构和如何进行数据转换。
目录
为避免用于处理数据的代码与训练模型的代码混淆在一起,能将数据集代码与模型训练代码分离是最好的,这样能够提高代码的整体可读性和模块化。
因此PyTorch提供了两个数据集相关的类:torch.utils.data.DataLoader 和 torch.utils.data.Dataset,这两个类允许我们使用预加载的数据集或使用自己的数据构建数据集。 其中:
Dataset存储样本数据及其相应的标签;DataLoader则能够将Dataset包装成一个可迭代对象,便于访问样本数据及其相应标签。
PyTorch 中提供了许多预加载的数据集,涵盖了图像类、文本类以及视频类:
图像类的如:CIFAR、COCO、ImageNet 等,这些数据集是 torch.utils.data.Dataset 的子类,可用于对模型进行原型设计和基准测试,能够实现特定于特定数据的功能。
1. 利用 torchvision.datasets 加载数据集
以下示例代码来自 Pytorch 官网教程。
以如何从 TorchVision 加载 CIFAR10 数据集为例。
该数据集共有 60000 60000 60000 张彩色图像,图像大小为 32 ∗ 32 ∗ 3 32*32*3 32∗32∗3,分为 10 10 10 个类,每类有 6000 6000 6000 张图。:
labels = {0: 'airplane', 1: 'automobile', 2: 'bird', 3: 'cat', 4: 'deer', 5: 'dog', 6:'frog', 7: 'horse', 8: 'ship', 9: 'truck'}
其中:
- 50000 50000 50000 张用于训练,构成了 5 5 5 个训练批,每一批10000张图;
- 另外 10000 10000 10000 用于测试,单独构成 1 1 1 批。
我们需要用到以下参数来加载 CIFAR10 数据集。
| param | 含义 |
|---|---|
| root | 训练集和测试集的存放路径 |
| train | True 表示训练集,False 表示测试集 |
| download=True | True 表示若 root 下无数据则在线下载 |
| transform | 指定训练数据或测试数据的转换 |
| target_transform | 指定标签数据的转换 |
示例代码如下:
# -------------------------------- #
# 1. 直接加载数据
# -------------------------------- #
from torchvision import datasets
from torchvision.transforms import ToTensor
training_data = datasets.CIFAR10(
root="data", # 根目录,也可写为'./data'
train=True, # 表示下载的是训练集
download=True, # 在线下载
transform=ToTensor() # 将训练集中的数据转换为 Tensor 类型
)
test_data = datasets.CIFAR10(
root="data",
train=False, # 表示下载的是测试集
download=True, # 在线下载
transform=ToTensor() # 将训练集中的数据转换为 Tensor 类型
)
一般网络不太稳定时下载会比较慢,所以也可以手动下载然后解压到指定的路径下。
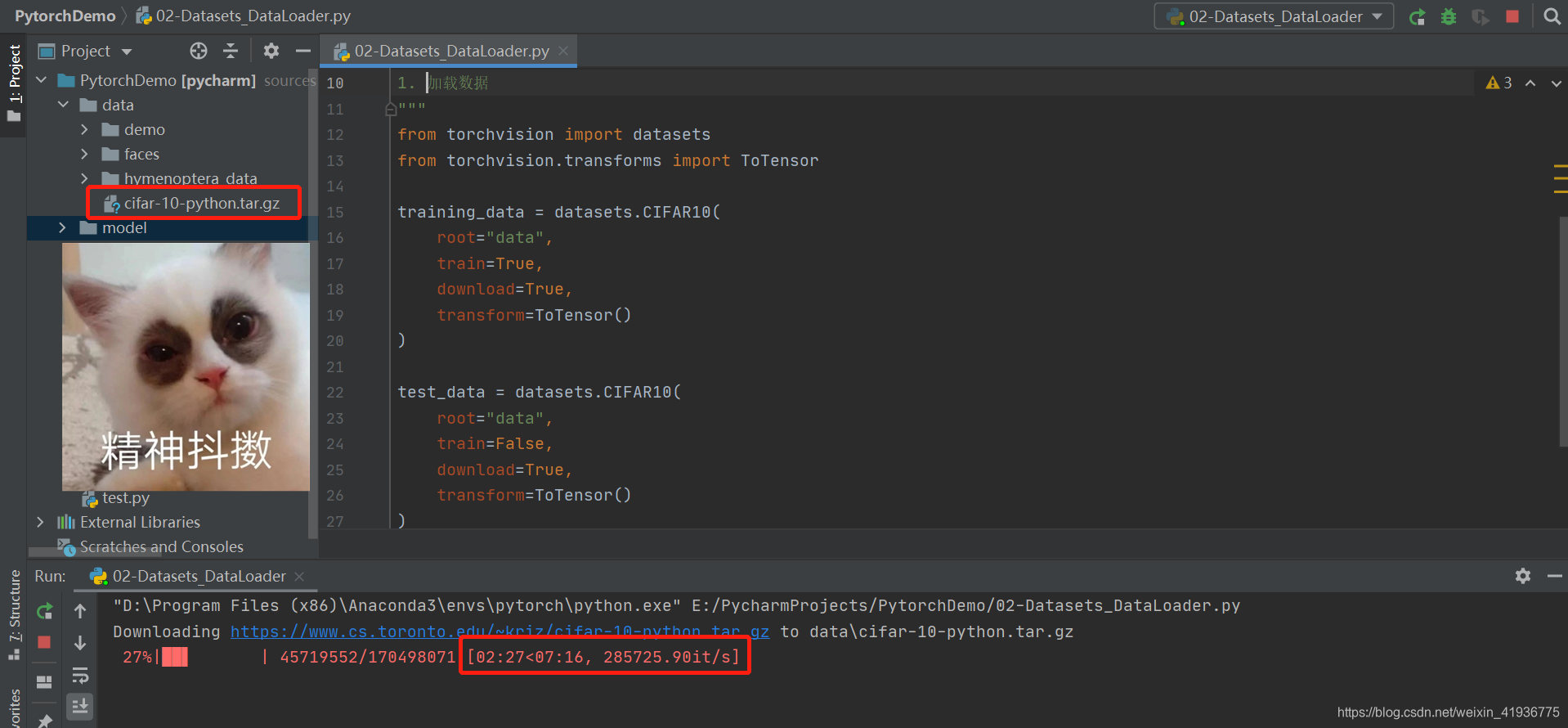
下载完成后会自动解压到指定的路径下。
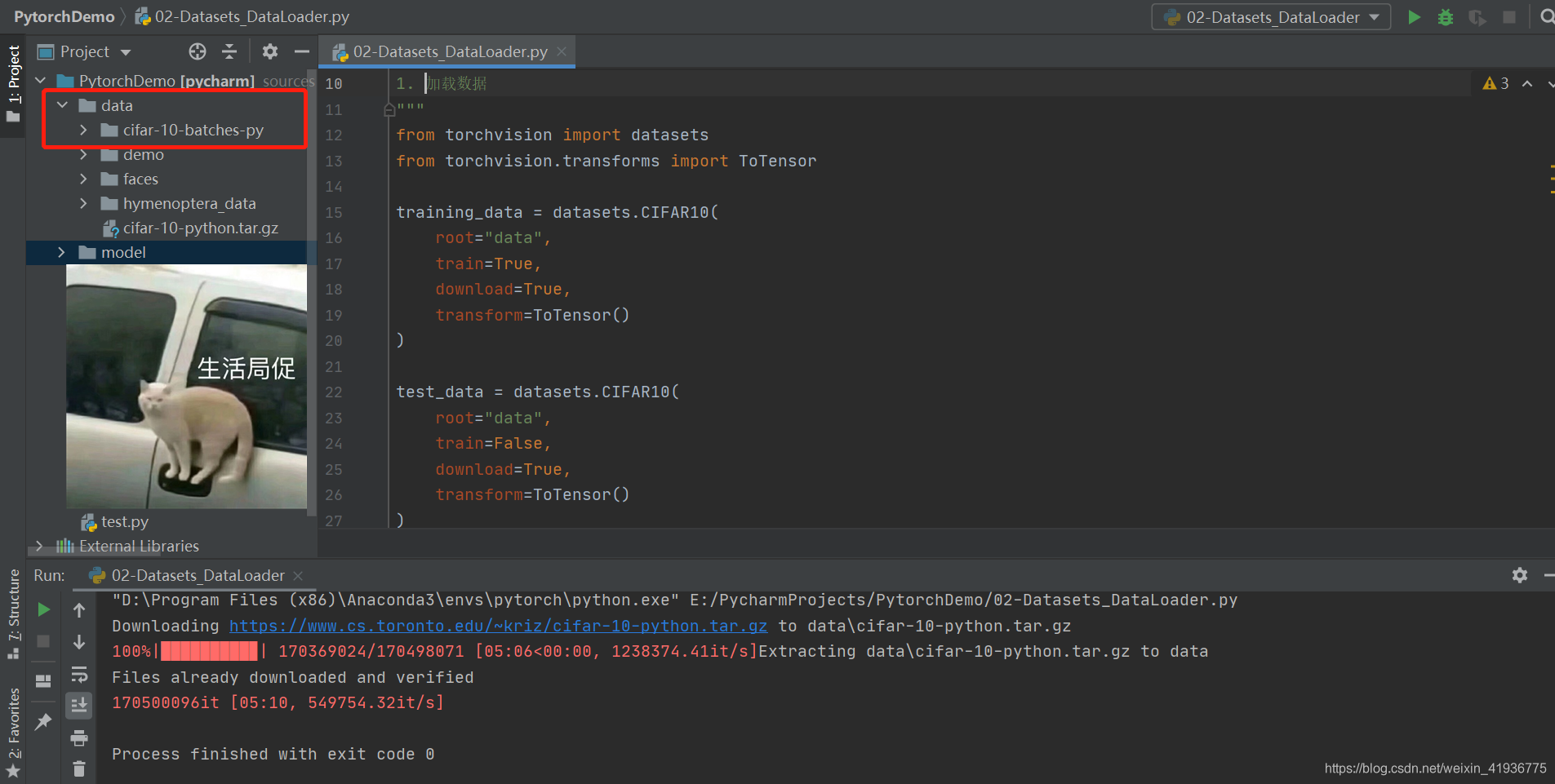
我们知道以 torchvision.datasets.CIFAR10() 加载的数据集存储了样本数据和对应的标签,那么具体是以什么结构存在的呢?尝试输出一下训练集:
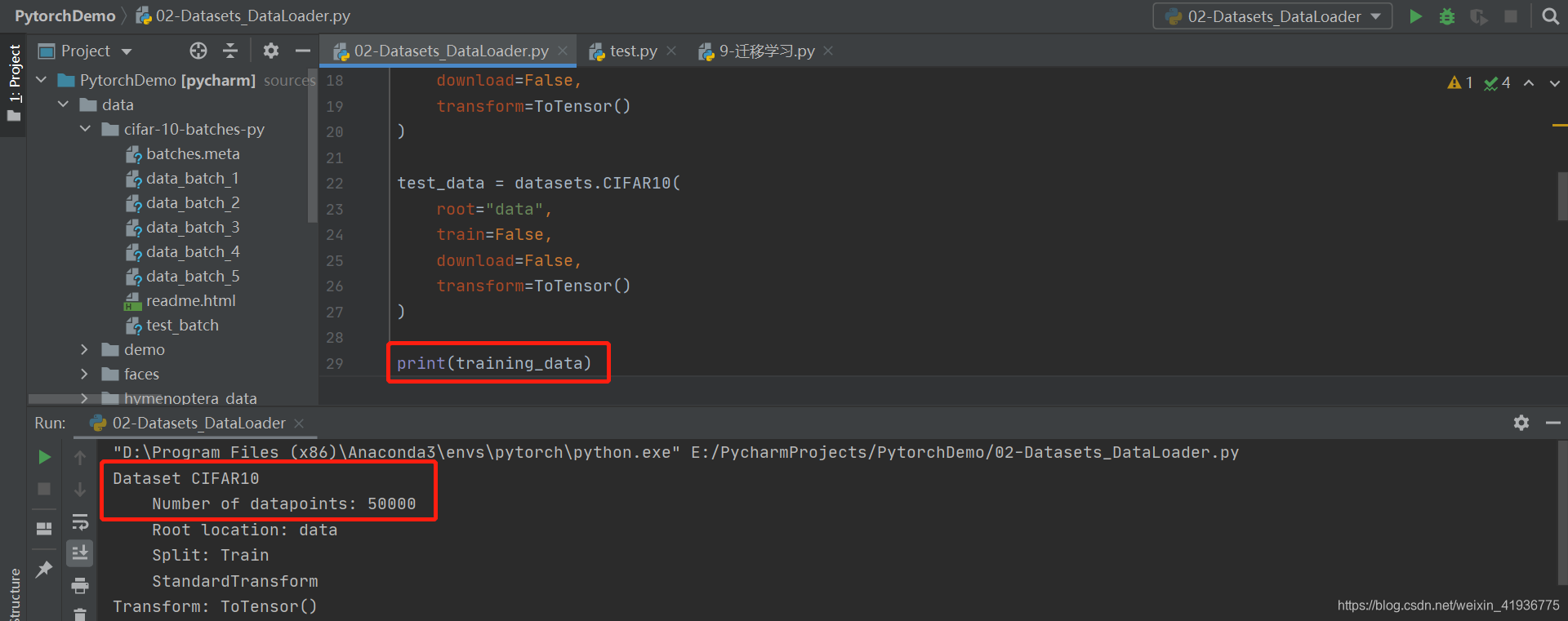
可以看到训练集的大小是
50000
50000
50000,然后尝试输出 training_data 中的第一个样本数据:
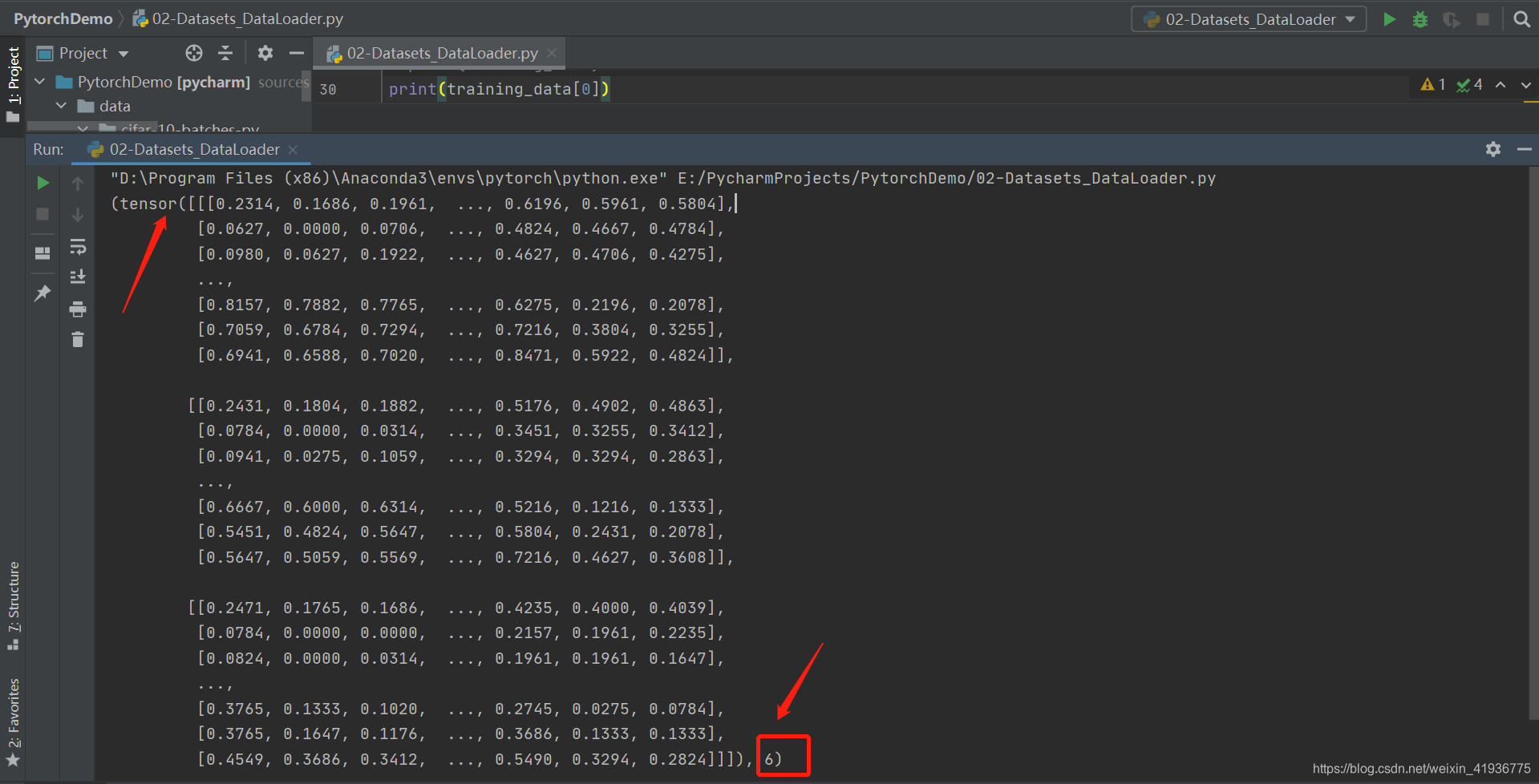
可以看到,training_data[0] 是以 (tensor, label) 这种元组的形式进行存储的,其中 tensor 代表图像信息,label 则以数字标签的形式存在。知道 training_data 的数据结构后,就可以可视化其中的数据了。
2. 可视化数据
2.1 手动索引
从上一部分知道 Dataset 类似于列表,也可以手动建立索引:training_data [index], 因此可以使用 matplotlib 可视化一些样本数据。
# -------------------------------- #
# 2. 可视化数据
# -------------------------------- #
import torch
import numpy as np
import matplotlib.pyplot as plt
labels_map = {
0: "airplane",
1: "automobile",
2: "bird",
3: "cat",
4: "deer",
5: "dog",
6: "frog",
7: "horse",
8: "ship",
9: "truck",
}
figure = plt.figure(figsize=(8, 8)) # 指定 figure 的宽和高
cols, rows = 3, 3 # 展示 9 张图像
for i in range(1, cols * rows + 1):
# 从 training_data 中随机选择一个样本并取出它的索引
sample_idx = torch.randint(len(training_data), size=(1,)).item()
# 从 training_data 中获取该索引对应的图像信息与数字标签信息
# 此时的 img 是一个 tensor 类型的数据
# pytorch中的图像存储格式为(N,C,H,W), 而python读取的图像格式一般为(H,W,C)
# 因此有时需要用到tensor的维度转换
img, label = training_data[sample_idx]
img = torch.transpose(img, 0, 2)
# 向 figure 中添加子图
figure.add_subplot(rows, cols, i)
# 并将子图的 title 设置为该图像对应的标签名称
plt.title(labels_map[label])
plt.axis("off")
"""
1. plt.imshow(X, cmp) 函数负责对图像进行处理,并显示其格式,但是不能显示图像
plt.show() 才能显示图像。
关于plt.imshow(X, cmp):
其中 X 为图像数据,支持以下几种 shape:
* (M, N)
* (M, N, 3)
* (M, N, 4)
前两维 (M, N) 定义了图像的宽和高,如果第三维度是 1 的话,就需要利用下面这个函数进行压缩。
2. torch.squeeze(input, dim=None, *, out=None) → Tensor
返回 维度值=1 的维度均被删除的一个张量
eg: 若输入的形状为 (M, N, 1),则输出的形状为 (M, N)
若给出参数 dim,则仅针对该维判断维度值是否为1,若为1,则去掉该维,否则输入不变。
"""
plt.imshow(img)
plt.show()
展示图像:

2.2 构造迭代对象
利用 enumerate() 可以将 Dataset 构造为一个可迭代对象,从而不需要手动获取索引值。
# -------------------------------- #
# 2. 可视化数据
# -------------------------------- #
import torch
import numpy as np
import matplotlib.pyplot as plt
labels_map = {
0: "airplane",
1: "automobile",
2: "bird",
3: "cat",
4: "deer",
5: "dog",
6: "frog",
7: "horse",
8: "ship",
9: "truck",
}
figure = plt.figure(figsize=(8, 8)) # 指定 figure 的宽和高
cols, rows = 3, 3 # 展示 9 张图像
for i, (img, label) in enumerate(training_data):
img = torch.transpose(img, 0, 2)
# 向 figure 中添加子图
figure.add_subplot(rows, cols, i+1)
# 并将子图的 title 设置为该图像对应的标签名称
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img)
if i == 8:
break
plt.show()
展示图像:

3. 利用 torch.utils.data.Dataset 类自定义数据集
自定义数据集类必须继承 torch.utils.data.Dataset 类,同时必须实现以下三个功能:
__init__():当实例化Dataset对象时,__init__函数将运行一次,并初始化包含图像,标签文件和两个转换的目录;__len__():返回数据集的大小;__getitem__():该函数从数据集中按照给定的索引idx加载并返回一个样本。 根据索引idx,该函数会标识图像在数据集中的位置,利用transform将其转换为tensor,并从self.img_labels中的csv数据中检索相应的标签(如果使用的话会在其上调用transform函数),然后以字典形式返回tensor格式的图像和对应的标签。
假设图像存储在目录 img_dir 中,各图像标签独立存储在 CSV 文件 annotations_file 中。
# -------------------------------- #
# 3. 构建自己的数据集
# -------------------------------- #
import os
import pandas as pd
from torchvision import datasets,transforms
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir,
transform=transforms.ToTensor(),
target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = datasets.ImageFolder(img_path, transform=None)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
sample = {"image": image, "label": label}
return sample
4. 利用 torch.utils.data.DataLoader 迭代数据集
Dataset 能够检索数据集的特征并一次标记一个样本,但在训练模型时,我们通常希望以 minibatches 方式传递样本,在每个 epoch 重新整理数据以减少模型的过拟合,并使用Python的多进程来加快数据检索的速度。DataLoader 加载器就能提供这样的便利, 它是一种可用 iter() 的可迭代对象,按照参数自动将数据分割成 minibatch,同时可选是否顺序随机打乱,能将 Dataset 对象转换为 tensor 。
# -------------------------------- #
# 4. 使用 DataLoader 获取数据
# -------------------------------- #
import torch
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
training_data = datasets.CIFAR10(
root="data",
train=True,
download=False,
transform=ToTensor()
)
test_data = datasets.CIFAR10(
root="data",
train=False,
download=False,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
labels_map = {
0: "airplane",
1: "automobile",
2: "bird",
3: "cat",
4: "deer",
5: "dog",
6: "frog",
7: "horse",
8: "ship",
9: "truck",
}
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0]
img = torch.transpose(img, 0, 2)
label = train_labels[0].item()
plt.title(labels_map[label])
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
运行结果:

展示图像:


















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









