




 本文介绍了PyTorch中数据加载的相关概念,包括Dataset用于保存和处理数据,DataLoader作为迭代器批量加载数据,以及Sampler自定义数据采样策略。详细阐述了Dataset的__init__、__len__、__getitem__方法,DataLoader的参数如batch_size、shuffle和num_workers,以及Sampler的SequentialSampler和RandomSampler等。同时,提到了collate_fn用于数据预处理,最后解析了DataLoader数据加载的运行流程。
本文介绍了PyTorch中数据加载的相关概念,包括Dataset用于保存和处理数据,DataLoader作为迭代器批量加载数据,以及Sampler自定义数据采样策略。详细阐述了Dataset的__init__、__len__、__getitem__方法,DataLoader的参数如batch_size、shuffle和num_workers,以及Sampler的SequentialSampler和RandomSampler等。同时,提到了collate_fn用于数据预处理,最后解析了DataLoader数据加载的运行流程。
简介:
在 PyTorch 中,我们的数据集往往会用一个类去表示,在训练时用 Dataloader 产生一个 batch 的数据。简单说,用一个类 抽象地表示数据集,而 Dataloader 作为迭代器,每次产生一个 batch 大小的数据,节省内存。
Dataset用于存放、处理图片和相应的标签。
Dataloader则是决定了我们以怎样的采样策略,每次输送多少张图片和标签到网络中进行学习。先通过sampler拿到图片和标签的索引【可能一个也可能是一个batch】,然后再通过索引从Dataset中拿到图片和对应的标签。
几者间的关系如下:
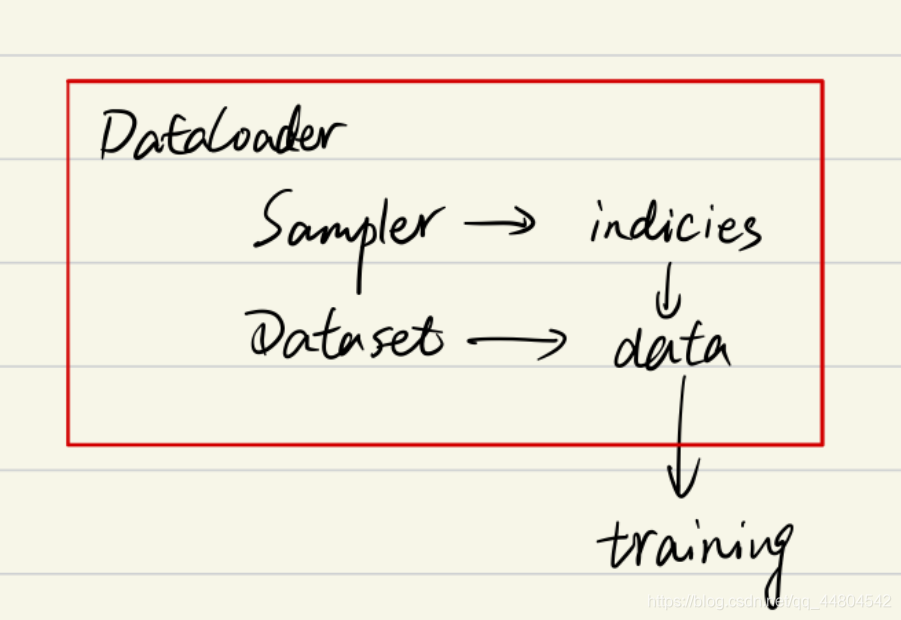
pytorch中加载数据的顺序是:
①创建一个dataset对象
②创建一个dataloader对象
③循环dataloader对象,将data,label拿到模型中去训练
Dataset
torch.utils.data.Dataset是一个抽象类,是Pytorch中图像数据集中最为重要的一个类,也是Pytorch中所有数据集加载类中应该继承的父类。
作用:保存数据集的图片和相应的标签,通过索引能够完成图片的加载以及预处理、标签的加载以及预处理。Datasets是后续构建Dataloader工具函数的实例参数之一。
在Dataset可以自己定义图片和标签的加载方式【针对不同的标签格式书写不同的加载方式】,各种预处理操作
用户想要加载自定义的数据只需要继承这个类,并且覆写其中的几个方法即可:
①__init__:传入数据,初始化信息
②__len__:返回整个数据集的大小
③__getitem__:返回一条训练数据【使用dataset[i]返回数据集中第i个样本】。根据传入的下标返回label和transform之后的图片并将其转换成tensor
注意:方法2-3必须重写,不覆写这两个方法会直接返回错误
class FirstDataset(data.Dataset):#需要继承data.Dataset
def __init__(self):
# TODO
# 1. 初始化文件路径或文件名列表。
#也就是在这个模块里,我们所做的工作就是初始化该类的一些基本参数。
pass
def __getitem__(self, index):
# TODO
#1。从文件中读取一个数据
#2。预处理数据(例如torchvision.Transform)。
#3。返回数据对(例如图像和标签)。
#这里需要注意的是,read one data,是一个data
pass
def __len__(self):
# 您应该将0更改为数据集的总大小
实例讲解
#导入相关模块
from torch.utils.data import DataLoader,Dataset
from skimage import io,transform
import matplotlib.pyplot as plt
import os
import torch
from torchvision import transforms
import numpy as np
class AnimalData(Dataset): #继承Dataset
def __init__(self, root_dir, transform=None): #__init__是初始化该类的一些基础参数
self.root_dir = root_dir #文件目录
self.transform = transform #变换
self.images = os.listdir(self.root_dir)#目录里的所有文件
def __len__(self):#返回整个数据集的大小
return len(self.images)
def __getitem__(self,index):#根据索引index返回dataset[index]
image_index = self.images[index]#根据索引index获取该图片
img_path = os.path.join(self.root_dir, image_index)#获取索引为index的图片的路径名
img = io.imread(img_path)# 读取该图片
label = img_path.split('\\')[-1].split('.')[0]# 根据该图片的路径名获取该图片的label,具体根据路径名进行分割。我这里是"E:\\Python Project\\Pytorch\\dogs-vs-cats\\train\\cat.0.jpg",所以先用"\\"分割,选取最后一个为['cat.0.jpg'],然后使用"."分割,选取[cat]作为该图片的标签
#label的解析方式多样
sample = {
'image':img,'label':label}#根据图片和标签创建字典
if self.transform:
sample = self.transform(sample)#对样本进行变换
return sample #返回该样本
设置好数据类之后,我们就可以将其用torch.utils.data.DataLoader加载,并访问它
if __name__=='__main__':
data = AnimalData('E:/Python Project/PyTorch/dogs-vs-cats/train',transform=None)#初始化类,设置数据集所在路径以及变换
dataloader = DataLoader(data,batch_size=128,shuffle=True 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









