









Elasticsearch入门教程
1.ES是什么?
1.如何理解es?
首先要知道它是做搜索用的,比如你想自己开发一个搜索引擎。
需求:用户会放置搜索参数 如:我是一个小哥哥,
效果:会返回一些网页信息
包含
:我的小狗狗叫黑虎
:是不是只有我,还在问,明天会更精彩
:怎么把哥哥锁在厕所
如以上效果,会把用户输入文本进行拆分,被拆分的每一个词都会作为搜索的关键词去做搜索。
当然,这里只是一个简单的举例,事实上它还能做很多事情。
1.对搜索文本document评分(也就是计算返回结果与用户输入文本的匹配度)。
2.一般的增删改查。等等
简单介绍一下es一个优点
:在数据量很大的情况下,搜索速度很快,近秒级。
我的理解较为粗浅:倒排索引。
什么是倒排索引呢?以上文中的需求案例:我的小狗狗叫黑虎。这个文本会被拆分成:我-的-小狗狗-叫-黑虎。同理其他的文本(这里指上文所说的其他的两句)也会被拆分。
es会有一种张专门的表去存储这些拆分后的词。以拆分后的词为单位,记录他们在哪个文本中出现过,一共出现的次数等等。当用户进行查询时,输入文本会被拆分,再将拆分后的词在这个文件中做匹配,返回匹配成功后的结果。
比如输入文本:我。这个词会在文件中记录出现在 我的小狗狗小黑虎,是不是只有我,还在问。这些文本记录中。因此这两条记录将会被返回。
当然以上只是一个简单理解,事实上es通常会用来做分布式的。一个index会被分片将数据存放在不同的服务器上,每一个分片都会有自己的一个备份。当搜索请求进来,es会分析id,确定数据在哪个分片上,然后将文本拆分,在分片所在的拆词文件中查找相应的数据。
:index 可以简单的想成mysql中的数据库
:分片 其实就是数据的水平分割,也就是分库。(比如mysql某一个数据库中每一张表都含有大量的数据,如果未加索引去查询会浪费很多时间,但是把这个数据库拆分成5份数据库,第一个数据库存放1-100w的数据,以此类推,可以减轻一个数据库的重量,当我进行请求时,我只需要知道某一条数据id的范围就可以查询)
:备份 防止es服务发生宕机,所以一般会把备份与主分片放在不同的服务器上。
:分析id 在备份中有简单说明水平分割数据库。分片就是对index的水平切割。请求入口在计算id(或者称为主维度)时,会先计算id的hash值,在与分片的数量求余。当然,当插入数据时,也是以相同的方法计算文本(document)应该在哪个分片中。
至此相信大家已经对es有一个粗浅的概念理解了,但事实上,请不要忘记,这只是一个粗浅的认识。对于大多数开发人员来说,对于数据库,能增删改查就可以了,那接下来就开始了。
2.安装、启动es
没有brew的同学,请自行安装并配置homebrew的国内下载镜像
1.安装
brew install elastricsearch
当然,如果你觉得下载很慢,这里提供所有环境的es下载地址。
地址链接: https://thans.cn/mirror/elasticsearch.html
提示:
:1.没有brew的同学,请自行安装并配置homebrew的国内下载镜像
:2.这个网址可能更新的不及时 es7.6是博主此刻最新的,然而网址最新是7.3不过无伤大雅.就冲这个链接,我觉得您应该给我个赞~
2.运行
进入安装目录下的bin文件,并执行es(博主):
cd elasticsearch-7.3.2/bin
./elasticsearch
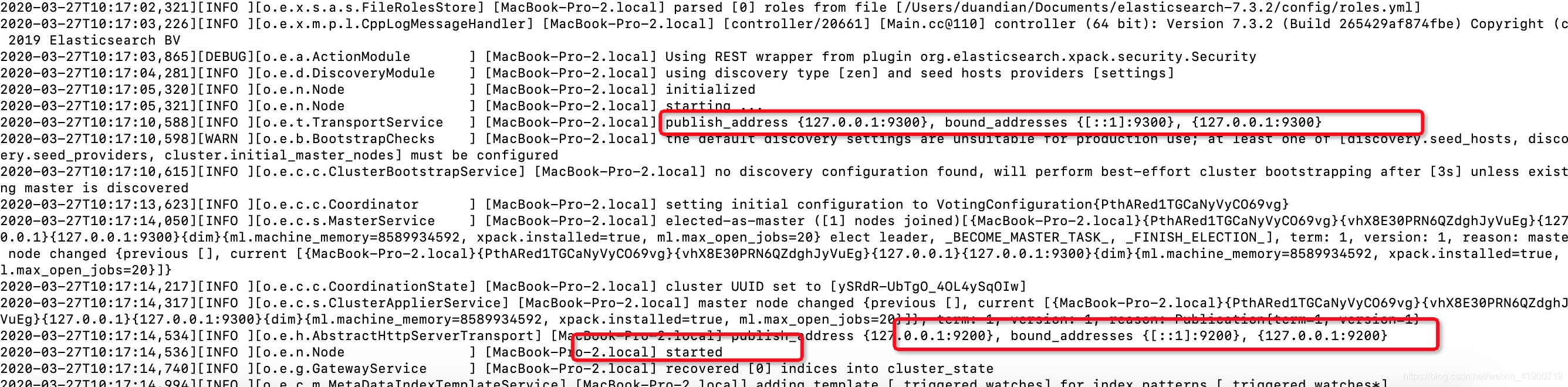
启动成功:会显示stared,并且绑定两个端口。9200,9300.
9300:es服务器节点之前的通信接口,比如当你的es要对一个index分片做备份。上文有提到过分片是存放在不同的服务器,因为是不是需要一个通过将存储的数据,创建数据的指令传送需要备份的服务器?纳,就是通过这个接口.
9200:es与外部链接的接口,http形式,用户可以通过这个端口做增删改查
3.安装、启动 kibana
kibana,这里只是一个做增上改查的数据发送的平台。可以用postman替代。事实上kibana还有许多复杂的功能等待着你发现。
brew install kibana
brew services start kibana # 启动在5601端口

我这里会提前有些小的demo,不用管。后面会一一讲解。
ps:
也会有一些其他的数据可视化管理平台。简单入门的话,没必要下那么多东西。
4.ES的增删改查
在做增删改查之前,先对es结构有一个简单的了解。
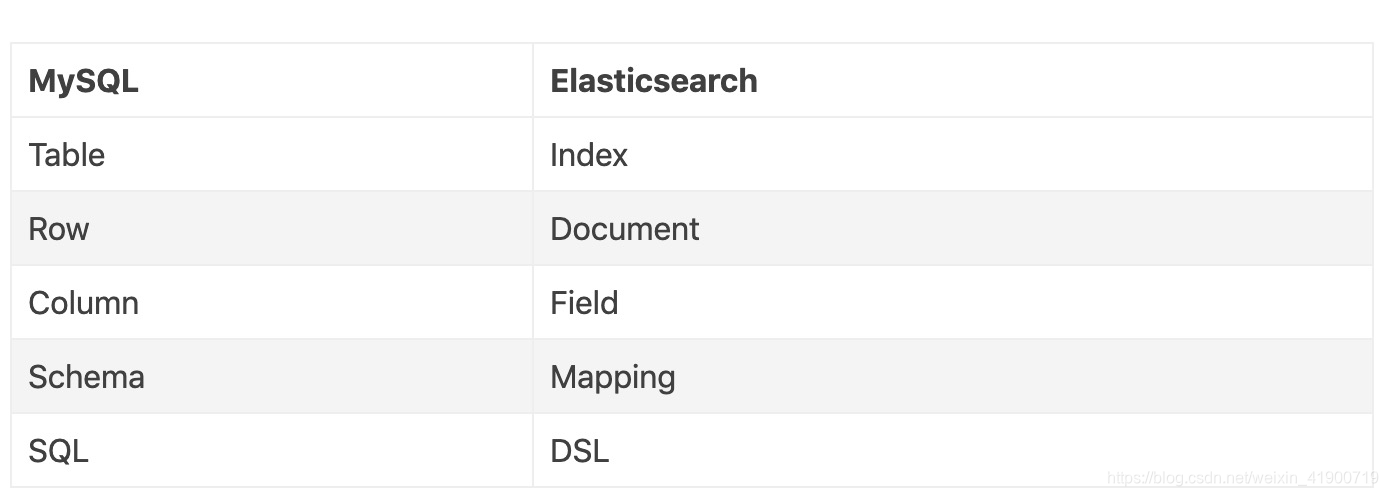
会不好有一丝丝的奇怪,之前不是说index对应mysql的数据库吗,这里怎么对应的是一张表。
事实上在es5中会支持一个数据库index包含多个表type,这里其实是有问题的,在es6中就默认规定一个index中只能存放一张表,但是你可以随意规定表的名字。在es7中一个index只能有一个默认type “_doc”。而在es8中将会抹去type这个概念。
:问题 首先一个表中会有很多字段field,上文中有提过es会把文档(一条记录数据 document),拆词放在一个文档中供查询使用。es在生成这个文档的时候,会把同一个index中相同名称的field放在一起。这个时候会产生一个问题,一个index可以含有很多表,但是如果表中间出现字段名称相同的情况,它们类型也必须相同。 这是他们的规定,我们也是小开发,没什么办法。事实上,在设计之初,index其实应该是一种文档的集合,index中的记录应该会有一种相关性,如果设计成多个表就会破坏这种相关性。而es会需要这些相关性做一些计算。这样想,一个index只能放一张表的问题是不是就可以很好的接受的。
事先说明:由于我不是按照真正的创建、修改、删除顺序去做如下操作,因此请读者在阅读一下文段时,请按段理解,比如删除的一条记录并不是一下代码创建的。了解用法才是应该的
创建index:
# es使用restful风格参数。post 多做增加、delete多用于删除、put多用于修改等+json
#运行时请自行删掉注释
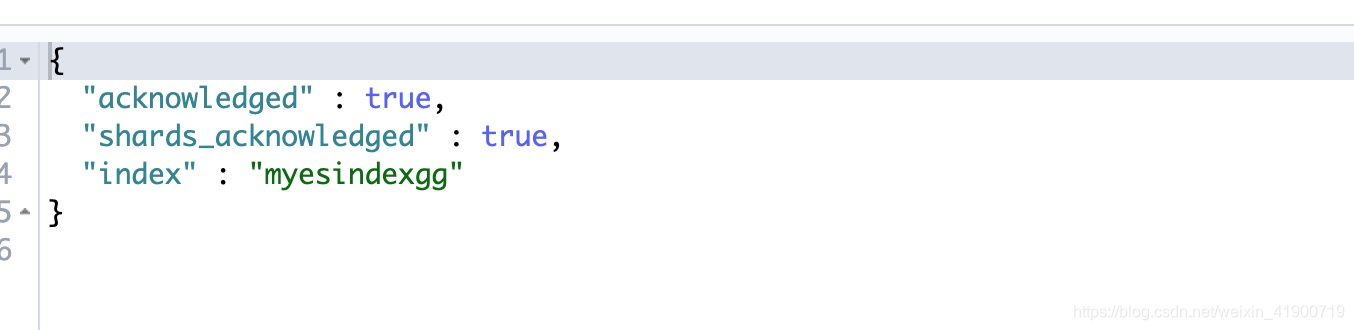
PUT myesindex
{
"settings": {
"number_of_shards": 3, # index的分片数量,在创建数据库时定好,不可更改(会造成已插入的数据丢失,不明白可看上文所提到的如何通过id查询数据)
"number_of_replicas": 2 #备份的数量
}
}
#创建一个较为完整的数据库
PUT twotypeindex02
{
"settings":{
"number_of_shards":5,
"number_of_replicas": 1
},
"mappings": { # 固定写法,用来声明index的字段及字段类型
"properties":{ # 固定写法,用来声明index的字段及字段类型,之前在这一层上面会有一层type,现已去掉。因此会和mappings意思有点重复
"user_name":{
"type":"long"
},
"age":{
"type":"integer"
},
"height":{
"type":"float"
},
"sex":{
"type":"boolean"
}
}
}
}
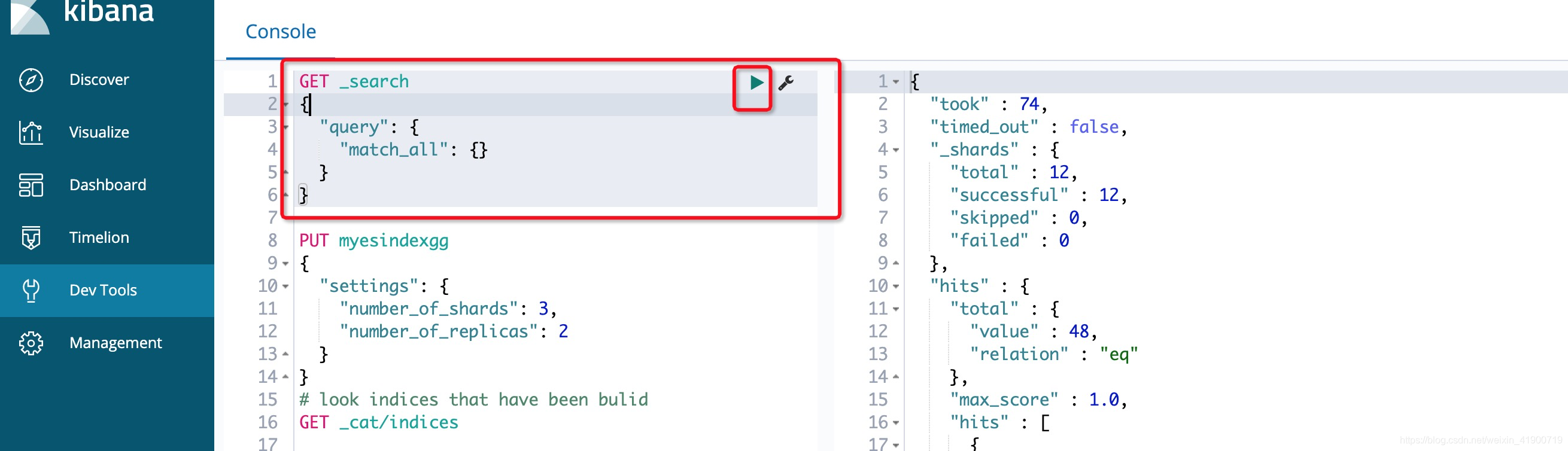
搜索所有有数据
GET _search
{
"query": {
"match_all": {}
}
}
更改配置文件
# 修改文件配置时候可能需要先关闭一下index,可以先直接修改试一下
# close index
POST myesindex/_close
# open index
POST myesindex/_open
# 修改mappings下内容,注意索引名称,不要copy上面的
PUT myesindex/_mappings
{
"properties":{
"user_name":{
"type":"text"
},
"age":{
"type":"text"
},
"height":{
"type":"text"
},
"sex":{
"type":"text"
}
}
}
# 更改setting,这里会报错,因为number_of_shards分片数量不可以被修改,读者自行删除
PUT myesindex22/_setting
{
"settings":{
"number_of_shards":5,
"number_of_replicas": 1
},
"mappings": {
"user":{
"properties":{
"user_name":{
"type":"long"
},
"age":{
"type":"int"
},
"height":{
"type":"float"
},
"sex":{
"type":"boolean"
}
}
}
}
}
添加记录
# create document
# 会返回数据的id,也可自己设定id
POST myesindex/_doc
{
"user_name":"NAME",
"age":"name is age",
"height":"12"
}
# 创建id为01的记录
POST myesindex/_doc/01
{
"user_name":"NAME",
"age":"name is age",
"height":"12"
}
删除记录
# index+type+id值
DELETE myesindex/_doc/I7edGnEBVb-8fGnNC6RT
修改记录
# 注意!!!!
# es并不会真正的删除数据,数据在创建的时候会被写入磁盘不可更改,删除、修改记录其实都是对之前的数据修改,设置`是否删除`默认字段为1。所以修改记录就是删除记录+创建新的记录,只不过id值被指定
# 另外,在搜索记录时会把原有被删除的值也查询出来,但是会做一层过滤,过滤掉那些被删除的数据.
PUT twotypeindex02/_doc/SreXJnEBVb-8fGnNDaQf
{
"user_name":"10",
"age":"18",
"height":"2"
}
指定id查询
GET myesindex/_search_shards?routing=IredGnEBVb-8fGnNCKTP
结构体查询
其实就是查询的时候会有自己打的结构.
GET myesindex/_search
{
"query": {
"match": {
"user_name": "name"
}
},
"_source":["user_name","age"]
}
请大家自行查阅查询相关的语句,实在是太多了。
最后在举一个重点案例:
由于图片不能上传,这里只能手打。
1.请读者创建一个index,属性含有name,类型为text
2.插入三条数据,name值分别为
:my name is tom
:my name is yy
:my name is bob
3.查询数据
GET myesindex/_search
{
"query": {
"match": {
"name": "is name my"
}
}
}
#你会发现三条记录都被查询到了。以my name is tom 为例,es会将它拆分为 my, name, is, tom 四个单词,存储到索引文件中,每一个单词都会记录自己出现的文档信息,如果is 在三条记录中都有出现。而用户的输入文本 is name my,会被拆分为 is, name, my 三个单词从而在索引文件中查询数据时,三条记录都可以匹配到,这就是拆词。
ps
:es当然可以是实现mysql的所有查询方法
:es拆分后的单词都会被写成小写的形式记录下来,因此如果查询语句是小写如name,而记录中是NAME,依然会被匹配到,NAME会以小写的形式存放在索引文件中
如果有什么不对的地方,请指正,博主看到后会及时修改~

















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









