









 本文深入解析InfluxDB的元数据结构,包括DatabaseInfo、RetentionPolicyInfo和ShardGroupInfo。阐述了Shard和ShardGroup的创建过程,强调了预创建策略以及时间对齐的重要性。此外,讨论了如何根据时间戳找到合适的ShardGroup进行数据写入。InfluxDB的元数据管理清晰地展现了其数据组织和存储的逻辑。
本文深入解析InfluxDB的元数据结构,包括DatabaseInfo、RetentionPolicyInfo和ShardGroupInfo。阐述了Shard和ShardGroup的创建过程,强调了预创建策略以及时间对齐的重要性。此外,讨论了如何根据时间戳找到合适的ShardGroup进行数据写入。InfluxDB的元数据管理清晰地展现了其数据组织和存储的逻辑。
~~ 在前面几章,介绍了influxdb的基本概念,经常的用法,以及怎么编译源码,以及服务启动部分。
- influxdb概念详解1
- influxdb安装和使用
- influxdb概念详解2
- influxdb源码编译
- influxdb启动分析
老规矩还是回顾一下influxdb的基本存储模型:
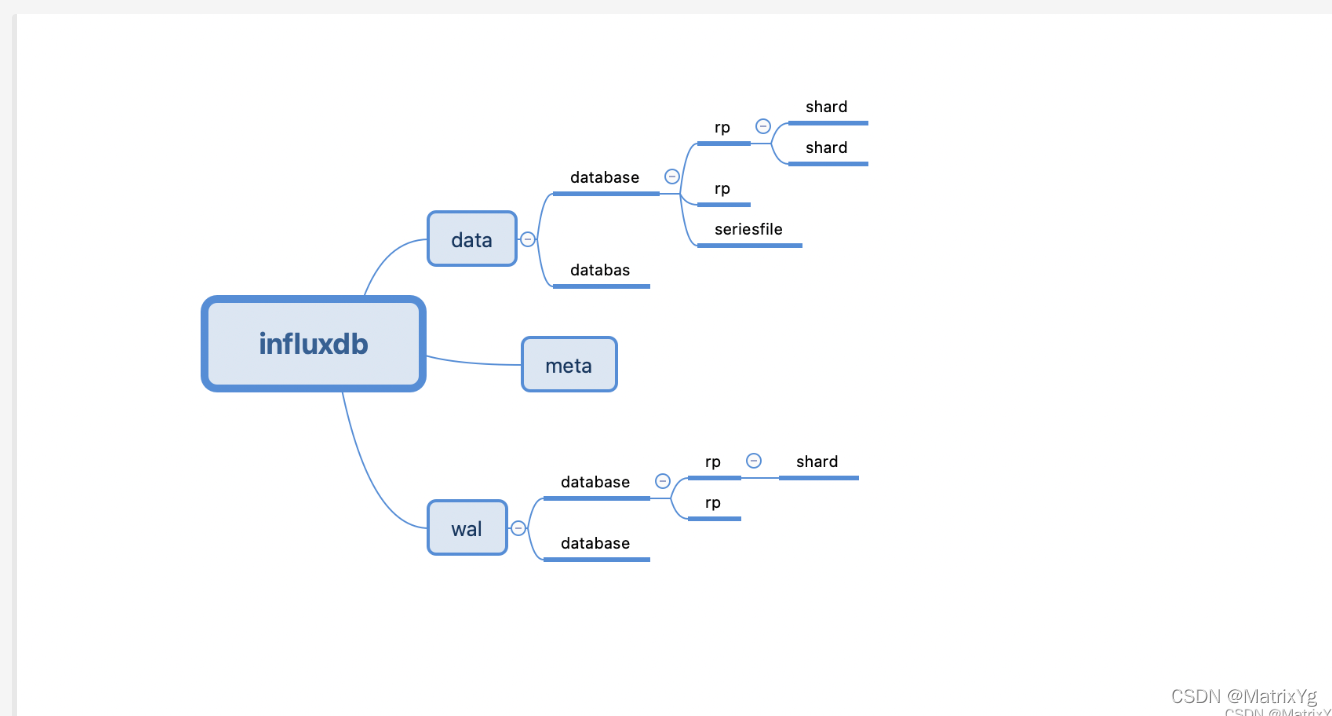
可以看到meta,data,wal是几个比较重要的模块。在上一章我们看到了influxdb在启动的时候,装配server模型,然后启动server。其中依赖了metaClient,这一章就分析一下meta结构。
Meta都有哪些
~~ meta信息指的就是influxdb的元数据信息,这个结构在influxdb/services/meta/data.go中定义
type Data struct {
Term uint64 // associated raft term
Index uint64 // associated raft index
ClusterID uint64
Databases []DatabaseInfo
Users []UserInfo
// adminUserExists provides a constant time mechanism for determining
// if there is at least one admin user.
adminUserExists bool
MaxShardGroupID uint64
MaxShardID uint64
}
这里有两个非常重要的数据结构:Databases和Users
Databases:保存了influxdb所有和数据库相关的信息,例如retention policy,continousQuery等
Users: users 保存了用户相关的信息。
除此之外,还能看到两个比较有趣的字段,Term和Index这个上面的注释说的是,和raft term相关的,因为influxdb集群版其实是没有开放的,这里侧面证明了,influxdb 集群版中实现副本共识用的是raft算法,在开源的时候,其实有一些部分没有删除干净。
~~~
在上面的两个结构中,UserInfo不是重点关心的,主要看一下Datatases。
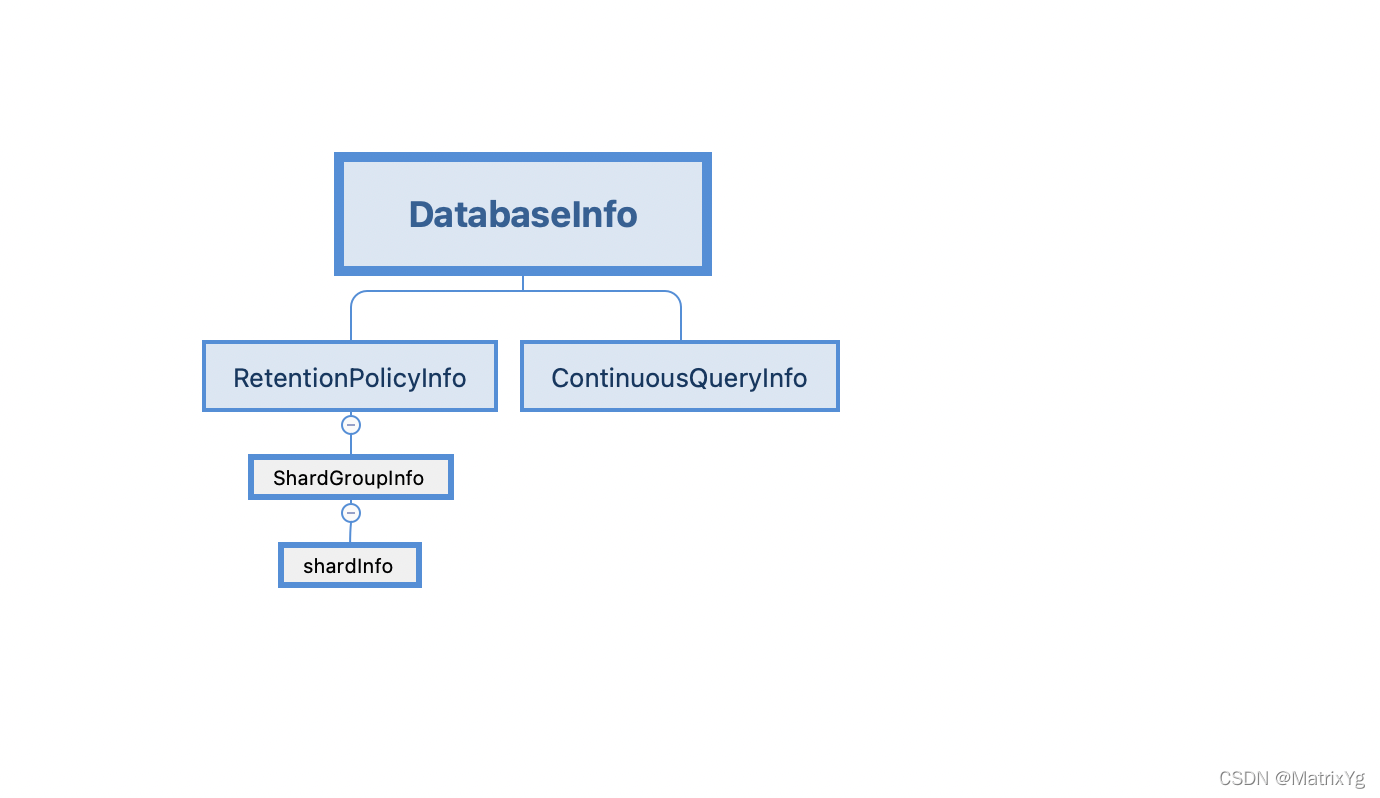
接下来按照从下往上来分析每个结构
Shard
在之前的 influxdb概念详解2中有解释到shard这个概念,这个代表了是一个的分片存储。描述Shard的元数据信息很简洁;
type ShardInfo struct {
ID uint64
Owners []ShardOwner
}
只有一个id,也就是shardId另外一个字段是Owners,表示shard对应的node。ShardOwner的结构也很简单:
type ShardOwner struct {
NodeID uint64
}
总体来看描述shard的meta信息比较简单。
Shard group
~~~ 在之前的概念介绍中,描述了shardGroup的概念,这个指的是一组shard。描述shardGroup的元数据信息:
type ShardGroupInfo struct {
ID uint64
StartTime time.Time
EndTime time.Time
DeletedAt time.Time
Shards []ShardInfo
TruncatedAt time.Time
}
首先是属于这个shardGroup的一组shard,然后是这个shardGroup的id,全局唯一递增的id;StartTime和EndTime表示这个shardGroup的开始和结束时间。说道这里可能有些人有点疑惑,先回顾一下概念:

在创建一个retention policy时,可以指定这个retention policy对应的shard duration,这个参数决定了一个shard group的范围。举个例子:
首先创建一个数据库test2
然后在这个数据库上,创建一个retention policy
CREATE RETENTION POLICY keep_one_week ON test2 DURATION 2w REPLICATION 1 SHARD DURATION 1w
这里表示创建的这个retention policy 过期时间是2 week,每1 week创建一个shard group,当系统运行一段时间之后,系统的内部是这个样子:
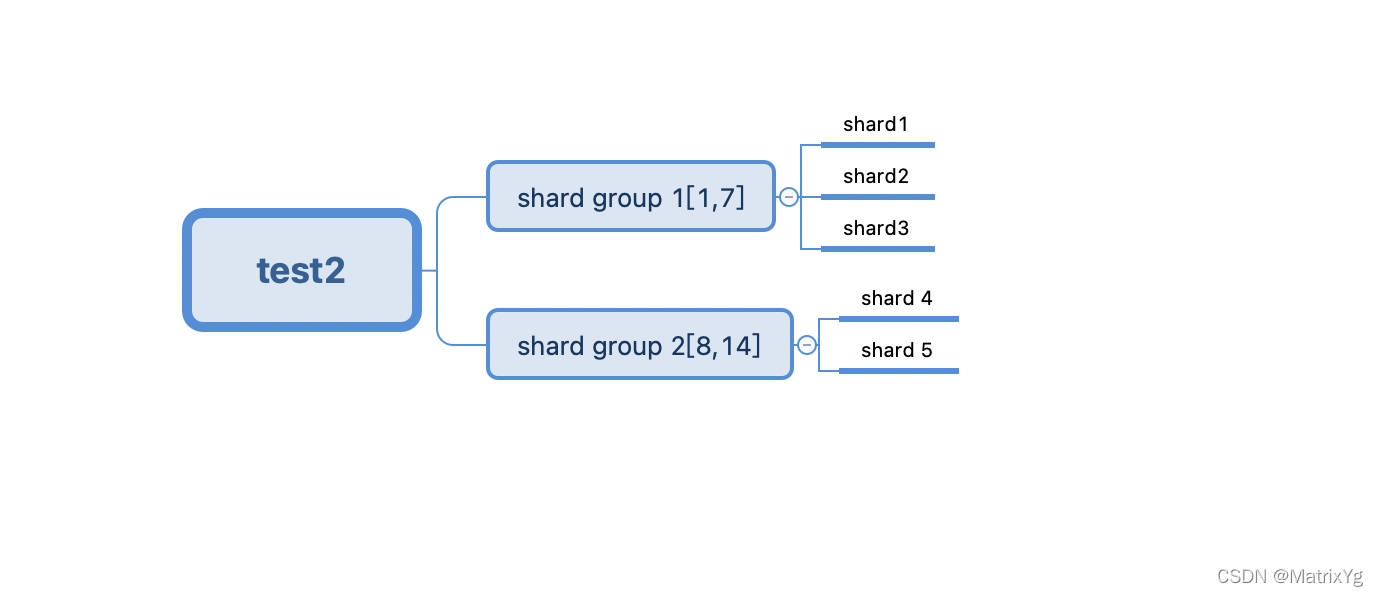
第[1,7]天创建的shard,都位于shard group 1内,第[8,14]天创建的shard,都在shard group 2内。
~~~
复习之后,其实shard group是从时间上,对shard做一个逻辑上的分组注意这里说的是逻辑上,shard group只是一个逻辑概念,在存储的时候,这些shard是平铺开的,并不是一个shard group的shard 存储在一起。
来看一下shardGroup几个核心的操作。
ShardGroup的创建
shardGroup的创建是一种预先创建的模式。在influxdb/services/precreator/service.go中,有一个定时轮询的goroutine
func (s *Service) runPrecreation() {
defer s.wg.Done()
for {
select {
case <-time.After(s.checkInterval):
if err := s.precreate(time.Now().UTC()); err != nil {
s.Logger.Info("Failed to precreate shards", zap.Error(err))
}
case <-s.done:
s.Logger.Info("Terminating precreation service")
return
}
}
}
func (s *Service) precreate(now time.Time) error {
cutoff := now.Add(s.advancePeriod).UTC()
return s.MetaClient.PrecreateShardGroups(now, cutoff)
}
这里会定时的检查,是不是需要预先创建一些东西,创建shardGroup的逻辑就这里。
PrecreateShardGroups的实现在influxdb/services/meta/client.go中。
func (c *Client) PrecreateShardGroups(from, to time.Time) error {
c.mu.Lock()
defer c.mu.Unlock()
data := c.cacheData.Clone()
var changed bool
for _, di := range data.Databases {
for _, rp := range di.RetentionPolicies {
if len(rp.ShardGroups) == 0 {
// No data was ever written to this group, or all groups have been deleted.
continue
}
g := rp.ShardGroups[len(rp.ShardGroups)-1] // Get the last group in time.
if !g.Deleted() && g.EndTime.Before(to) && g.EndTime.After(from) {
// Group is not deleted, will end before the future time, but is still yet to expire.
// This last check is important, so the system doesn't create shards groups wholly
// in the past.
// Create successive shard group.
nextShardGroupTime := g.EndTime.Add(1 * time.Nanosecond)
// if it already exists, continue
if sg, _ := data.ShardGroupByTimestamp(di.Name, rp.Name, nextShardGroupTime); sg != nil {
c.logger.Info("Shard group already exists",
logger.ShardGroup(sg.ID),
logger.Database(di.Name),
logger.RetentionPolicy(rp.Name))
continue
}
newGroup, err := createShardGroup(data, di.Name, rp.Name, nextShardGroupTime)
if err != nil {
c.logger.Info("Failed to precreate successive shard group",
zap.Uint64("group_id", g.ID), zap.Error(err))
continue
}
changed = true
c.logger.Info("New shard group successfully precreated",
logger.ShardGroup(newGroup.ID),
logger.Database(di.Name),
logger.RetentionPolicy(rp.Name))
}
}
}
if changed {
if err := c.commit(data); err != nil {
return err
}
}
return nil
}
这个函数看上去有点长,但是逻辑并不复杂。
~~~
第7,8两行,是遍历所有的database,以及database下面的retention policy。这个在上面的结构分析也能看出来,shardgroup是位于这些结构之下的。然后13,14行是在取出来最后一个shardGroup,来检查,当前的时间是不是被最后一个shardGroup覆盖了。注意这里很重要,说明shardgroup数组,是按照结束时间升序排序了的,这个在后面也能看出来。
~~~
如果最后一个shardgroup的时间,是没有覆盖住当前的时间(这个当前的时间,指的是now-now+advandance,可以在上面看到)。那么开始创建。
~~~
第20行计算了下一个shardgroup的开始时间,这里是通过上一个shardgroup的结束时间+1,说明shardgroup的时间是完全连续的。
~~~
第29行开始真正创建shardGroup
createShardGroup里面有进行了一次校验,然后委托给了data结构的CreateShardGroup注意,到这里,逻辑还是在client.go里面。
func createShardGroup(data *Data, database, policy string, timestamp time.Time) (*ShardGroupInfo, error) {
// It is the responsibility of the caller to check if it exists before calling this method.
if sg, _ := data.ShardGroupByTimestamp(database, policy, timestamp); sg != nil {
return nil, ErrShardGroupExists
}
if err := data.CreateShardGroup(database, policy, timestamp); err != nil {
return nil, err
}
rpi, err := data.RetentionPolicy(database, policy)
if err != nil {
return nil, err
} else if rpi == nil {
return nil, errors.New("retention policy deleted after shard group created")
}
sgi := rpi.ShardGroupByTimestamp(timestamp)
return sgi, nil
}
进入data.CreateShardGroup,这里开始创建shardgroup
//CreateShardGroup creates a shard group on a database and policy for a given timestamp.
func (data *Data) CreateShardGroup(database, policy string, timestamp time.Time) error {
// Find retention policy.
rpi, err := data.RetentionPolicy(database, policy)
if err != nil {
return err
} else if rpi == nil {
return influxdb.ErrRetentionPolicyNotFound(policy)
}
// Verify that shard group doesn't already exist for this timestamp.
if rpi.ShardGroupByTimestamp(timestamp) != nil {
return nil
}
// Create the shard group.
data.MaxShardGroupID++
sgi := ShardGroupInfo{}
sgi.ID = data.MaxShardGroupID
// 这里是对齐到duration
sgi.StartTime = timestamp.Truncate(rpi.ShardGroupDuration).UTC()
sgi.EndTime = sgi.StartTime.Add(rpi.ShardGroupDuration).UTC()
if sgi.EndTime.After(time.Unix(0, models.MaxNanoTime)) {
// Shard group range is [start, end) so add one to the max time.
sgi.EndTime = time.Unix(0, models.MaxNanoTime+1)
}
data.MaxShardID++
sgi.Shards = []ShardInfo{
{ID: data.MaxShardID},
}
// Retention policy has a new shard group, so update the policy. Shard
// Groups must be stored in sorted order, as other parts of the system
// assume this to be the case.
rpi.ShardGroups = append(rpi.ShardGroups, sgi)
// 这里是强制转换,差点没看明白
sort.Sort(ShardGroupInfos(rpi.ShardGroups))
return nil
}
~~~
前面15行是一些基本参数的校验,直接跳过。
~~~
17行更新了maxShardGroupId,18行新建了shardGroup结构。
~~~
重点在21-22行,这里有些人可能会看不懂。这里其实是做了一个时间的对齐。timestamp参数是上面传下来的上一个shardgroup的endtime+1,这会把shardGroup 的开始时间,对齐到小于等于timestamp时间的并且是shard duration倍数最大的那个数。这里似乎说的有点奇怪,其实就是向下取整如果还是不明白,可以自己写两个单测,测试一下Truncate函数就明白了。
~~~
第40行,给shardgroup做了个排序,排序的规则刚才已经说了。具体的规则可以参考shardGroup的Less函数。
func (a ShardGroupInfos) Less(i, j int) bool {
iEnd := a[i].EndTime
if a[i].Truncated() {
iEnd = a[i].TruncatedAt
}
jEnd := a[j].EndTime
if a[j].Truncated() {
jEnd = a[j].TruncatedAt
}
if iEnd.Equal(jEnd) {
return a[i].StartTime.Before(a[j].StartTime)
}
return iEnd.Before(jEnd)
}
到这里一个shardgroup算是创建完了。
~~~
我们花费了大量的篇幅来描述shardgroup是怎么创建的,这里面可以看到一些influxdb在设计和实现的一些思想:
- 预先创建shardgroup,避免临时创建
- client.go的所有操作,都会委托到data.go里面执行。边界和职责很清晰。
- shardgroup的时间是完全连续的,并且开始和结束时间都是shard duration的倍数。按照shard duration对齐。
最后关于shardGroup还有一个重要的函数:
func (sgi *ShardGroupInfo) ShardFor(hash uint64) ShardInfo {
return sgi.Shards[hash%uint64(len(sgi.Shards))]
}
这个函数在写入的时候是十分重要的,用来选择某个point到底写入那个shard。其中入参hash是point的hash值。这里就是直接使用取模选取。
RetentionPolicy
~~~ 分析完shardgroup 之后,来到RetentionPolicy。retenteion policy 的描述也很简洁:
type RetentionPolicyInfo struct {
Name string
ReplicaN int
Duration time.Duration
ShardGroupDuration time.Duration // shardGroup的切分时长
ShardGroups []ShardGroupInfo // 所有的shardGroup
Subscriptions []SubscriptionInfo
}
retention policy除了刚才大力介绍的shardGroups,就是Duration和ShardGroupDuration,这两个参数在之前也介绍过了,不再赘述。ReplicaN表示副本数量,这个在集群版有用,暂时不多介绍。其他的就不再过多介绍。接下来介绍几个比较重要的函数:
func (rpi *RetentionPolicyInfo) ShardGroupByTimestamp(timestamp time.Time) *ShardGroupInfo {
for i := range rpi.ShardGroups {
sgi := &rpi.ShardGroups[i]
if sgi.Contains(timestamp) && !sgi.Deleted() && (!sgi.Truncated() || timestamp.Before(sgi.TruncatedAt)) {
return &rpi.ShardGroups[i]
}
}
return nil
}
这个函数式通过timestamp来寻找具体的shardgroup,这个函数在写入point的时候,需要确定当前的point位于那个shardgroup里面。这里有个细节,**由于shardgroup是按照时间排序的,这里顺序遍历,所以point会被写入第一个满足条件的shardgroup,也就是时间最小的那个
**。
其他的函数就不再介绍了。逻辑并不复杂。
DatabaseInfo
最后来到了顶层的结构:DatabaseInfo
type DatabaseInfo struct {
Name string
DefaultRetentionPolicy string
RetentionPolicies []RetentionPolicyInfo
ContinuousQueries []ContinuousQueryInfo
}
这个结构除了刚才介绍的retention policy,还有就是cq,关于cq我们后面单独会介绍,这里不再过多赘述。
databaseInfo结果是进一步的封装,把底层相关信息的接口给封装一下。如果上面的都能理解,那么这里的相关操作也不难理解。
Meta结构总结
这一章我们主要分析了databaseinfo,retention policy,shardgroup,shard等结构的元数据信息。这些信息被定义在influxdb/services/meta中
其中client.go提供了对这些信息统一的增删改查接口。data.go定义了这些结构的真正操作。internal下面是一些内部信息,用于序列化和反序列化的。到这里meta部分分析结束!感谢收看,方便的话,一键三连!


















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









