







 该研究提出了用于多人3D姿态估计的压缩体积热图方法,通过自底向上的自监督学习框架,解决内存占用大和输入分辨率限制的问题。利用高分辨率的体积热图映射和自编码器,预测并细化3D关节位置。在JTA、CMUpanoptic和Human360m数据集上,该方法表现出优于其他方法的性能,尤其是在处理多人重叠场景时。
该研究提出了用于多人3D姿态估计的压缩体积热图方法,通过自底向上的自监督学习框架,解决内存占用大和输入分辨率限制的问题。利用高分辨率的体积热图映射和自编码器,预测并细化3D关节位置。在JTA、CMUpanoptic和Human360m数据集上,该方法表现出优于其他方法的性能,尤其是在处理多人重叠场景时。
Compressed Volumetric Heatmaps for Multi-Person 3D Pose Estimation
题目:《用于多人3D姿态估计的压缩体积热图》
作者:Matteo Fabbri, Fabio Lanzi, Simone Calderara,Stefano Alletto, Rita Cucchiara
University of Modena and Reggio Emilia,Panasonic R&D Company of America
来源:CVPR 2020
研究方向:单目/多视角-单人姿态识别/多人姿态识别-无监督学习
已有研究:
1、对2D数据用热图预测关节位置,产生问题:
①对内存计算量大;
②限制输入要求小分辨率图片。
2、现有3D姿态研究类型:
①估计2D关节,将其投影至3D关节坐标;
②联合估计2D姿态与3D姿态;
③直接从RGB图像中学习3D姿态(本文采用方法)。
3、现有对单目-多人姿态估计方式:
①自底向上:在单目中产生多人关节位置,推断出强遮挡下的3D姿态,用关节向量表示3D姿态,同时编码不依赖人数限制;
②自顶向上:设定识别一个人的边界框,针对每个人得到单人的3D姿态。
改进: ①自监督学习框架:采用自底向上的方式
②使用高分辨率的体积热图映射为一个紧凑更易处理的表示
③处理运行时间恒定(文中只提出未详细介绍)
研究方法(思路):
整体结构:采用自编码结构,直接从RGB图像中学习3D姿态
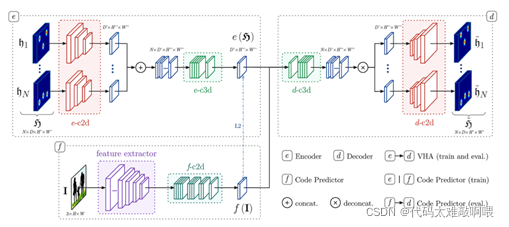
实现细节:
LoCO:学习压缩输出,自底向上创建一个保留原始GT内容的替代GT,以此减少内存的使用
👇
体积热图自编码:多分支体积热图自编码器(VHA)
👇
编码预测器:通过输入RGB图像I使用VHA编码,预测出f(I)与e(h)均方误差训练编码预测器
(其中:①使用VHA编码:用预先训练好的特征提取器(本文中使用Inception-v3),再用4个2D卷积块f-c2d;②f(I):使用局部最大值,用针孔摄像机[HX3] 方程恢复被检测关节的真实三维坐标)
👇
连接关节:基于距离的启发式方法
(从头部最高点-headtop作为根关节点,用3D欧几里得距离连接剩下的N-1个关节。设置肢体长度阈值来确定相邻连接关节)
👇
姿态细化:使用多层感知机模型MLP作为位姿细化器
根位姿:头部最高点headtop,设置为X1
输入:根相对位置Prr+高斯噪声,用MSE损失作为训练的位姿细化器
由位姿细化器+根相对位姿训练
输出:相应的3D姿态位置
数据集:
1、JTA数据集:城市,多人
评估:F1-score[HX4]
对比结果:①比较LoCO与Location map: Location 不适合多人重叠拥挤场景;
②与yolo-v3多人方法比较:自顶向上,处理帧数少,会丢失重叠拥挤场景;
③与不压缩热量比较:训练复杂。
2、CMU panoptic数据集:单人+多人
评估:F1-score[HX4] 、MPJPE
对比结果:比其他3种多人方式F1-score值高。
3、Human 360m数据集:单人
评估:F1-score[HX4] 、MPJPE
对比结果:文中提出的框架对单人模型也有良好的泛化能力。
[HX1]RGB-D(深度图像)
深度图像 = 普通的RGB三通道彩色图像 + Depth Map
在3D计算机图形中,Depth Map(深度图)是包含与视点的场景对象的表面的距离有关的信息的图像或图像通道。其中,Depth Map 类似于灰度图像,只是它的每个像素值是传感器距离物体的实际距离。通常RGB图像和Depth图像是配准的,因而像素点之间具有一对一的对应关系。
[HX2]体素化(Voxelization)是将物体的几何形式表示转换成最接近该物体的体素表示形式,产生体数据集,其不仅包含模型的表面信息,而且能描述模型的内部属性。表示模型的空间体素跟表示图像的二维像素比较相似,只不过从二维的点扩展到三维的立方体单元,而且基于体素的三维模型有诸多应用。
[HX3]参考:https://blog.youkuaiyun.com/a1059682127/article/details/80632168


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









