




Tiny-LLM
大体流程
git clone https://github.com/KMnO4-zx/tiny-llm
# 安装环境
python3 -m pip install -r requirements.txt
# 训练Tokenizer:
python train_vocab.py --download True --vocab_size 4096
# 数据预处理:
python preprocess.py
# 训练模型:
python train.py
# 使用模型生成文本:
python sample.py --prompt "One day, Lily met a Shoggoth"
经过上述的部分,理论上就训练好了一个小型的llm模型,以下按照步骤解读各个模块的代码(由于有着比较大的显存,设置了大的bs,但目前看起来好像是训飞了)
训练tokenizer
这里核心的训练tokenizer的代码是这段
import sentencepiece as spm
# SentencePiece 模型的前缀路径,将用于保存分词器
prefix = os.path.join(DATA_CACHE_DIR, f"tok{vocab_size}")
spm.SentencePieceTrainer.train(
input=tiny_file, # 输入文件为之前生成的 tiny.txt
model_prefix=prefix, # 模型前缀路径
model_type="bpe", # 使用 Byte-Pair Encoding (BPE) 训练分词器
vocab_size=vocab_size, # 词汇表大小
self_test_sample_size=0, # 自测样本大小设置为 0
input_format="text", # 输入文件格式为纯文本
character_coverage=1.0, # 覆盖所有字符(包括非常见字符)
num_threads=os.cpu_count(), # 使用 CPU 的线程数
split_digits=True, # 拆分数字
allow_whitespace_only_pieces=True, # 允许仅由空格组成的词元
byte_fallback=True, # 启用字节级回退
unk_surface=r" \342\201\207 ", # UNK token 表示未知字符的方式
normalization_rule_name="identity" # 使用“identity”归一化规则
)
由于使用的是一个tiny数据集,这里使用的词汇表大小设置为4096
训练 Tokenizer 时,SentencePiece 会自动生成两个文件:tok4096.model 和 tok4096.vocab,其中 tok4096.model 是我们训练好的模型文件,位于 data 目录下。这个文件可以用于将文本数据转换为 Token 序列,也可以将 Token 序列还原为文本。
其中关于Tokenizer的比较重要的使用方法可以参考如下的实现
class Tokenizer:
def __init__(self, tokenizer_model=None):
"""
初始化分词器。加载预训练的SentencePiece模型,并设置一些特殊的token ID。
参数:
tokenizer_model: str, 可选,分词器模型的路径,如果不指定则使用默认路径 TOKENIZER_MODEL。
"""
# 如果提供了分词器模型路径,使用该路径;否则使用默认模型路径
model_path = tokenizer_model if tokenizer_model else TOKENIZER_MODEL
# 确保模型文件存在
assert os.path.isfile(model_path), model_path
# 加载 SentencePiece 模型
self.sp_model = SentencePieceProcessor(model_file=model_path)
self.model_path = model_path
...
def encode(self, s: str, bos: bool, eos: bool) -> List[int]:
"""
将字符串编码为词元ID列表。可以选择是否添加句子开头 (BOS) 和句子结尾 (EOS) 标记。
参数:
s: str, 要编码的字符串。
bos: bool, 是否在编码的词元列表前添加 BOS 标记。
eos: bool, 是否在编码的词元列表末尾添加 EOS 标记。
返回:
List[int]: 编码后的词元ID列表。
"""
# 确保输入是字符串类型
assert type(s) is str
# 使用SentencePiece将字符串编码为词元ID
t = self.sp_model.encode(s)
...
def decode(self, t: List[int]) -> str:
"""
将词元ID列表解码为字符串。
参数:
t: List[int], 词元ID列表。
返回:
str: 解码后的字符串。
"""
return self.sp_model.decode(t)
由此实现了对tokenizer的基本初始化以及对给定的文本和数字的编码和解码
数据处理
这里数据集的预处理方法的代码是先前使用的比较少的书写格式,可以参考学习下。
在这部分中,首先定义了 process_shard 函数,用于处理数据分片。该函数的主要功能是将文本数据分词后,转换为更高效的二进制文件格式,以便后续更快速地加载和处理数据。具体的代码见下:
def process_shard(args, vocab_size, tokenizer_model_path):
"""
处理数据分片,将其中的文本进行分词并保存为二进制文件。
参数:
args: tuple, 包含分片ID和分片文件名
vocab_size: int, 词汇表大小,用于决定输出文件存储路径
"""
# 提取分片ID和文件名
shard_id, shard = args
...
# 将token以二进制形式保存
with open(tokenized_filename, "wb") as f:
f.write(all_tokens.tobytes())
接下来,我们定义了 pretokenize 函数,用于批量处理多个数据分片。通过这一函数,所有数据可以并行处理,进一步加快预处理的速度。具体代码见下
# 定义预处理函数,用于对多个数据分片进行批量处理
def pretokenize(vocab_size):
"""
预处理所有的数据分片,并将分词后的数据保存为二进制文件。
参数:
vocab_size: int, 词汇表大小,用于决定输出文件存储路径
"""
# 数据所在目录
data_dir = os.path.join(DATA_CACHE_DIR, "TinyStories_all_data")
# 获取所有JSON文件的文件名列表,并按字典序排序
shard_filenames = sorted(glob.glob(os.path.join(data_dir, "*.json")))
# 如果词汇表大小大于0,则创建对应的保存目录
if vocab_size > 0:
bin_dir = os.path.join(DATA_CACHE_DIR, f"tok{vocab_size}")
os.makedirs(bin_dir, exist_ok=True)
# 使用partial函数将vocab_size绑定到process_shard函数
fun = partial(process_shard, vocab_size=vocab_size, tokenizer_model_path=TOKENIZER_MODEL)
# 使用进程池并行处理每个分片
with ProcessPoolExecutor() as executor:
executor.map(fun, enumerate(shard_filenames))
print("Done.")
其中使用了进程池和partial的结合的用法,可以参考学习以下
训练模型
暂时是直接使用
python3 train.py
具体的代码可能需要查看是否有一些较为新的用法
由此的一些运行结果
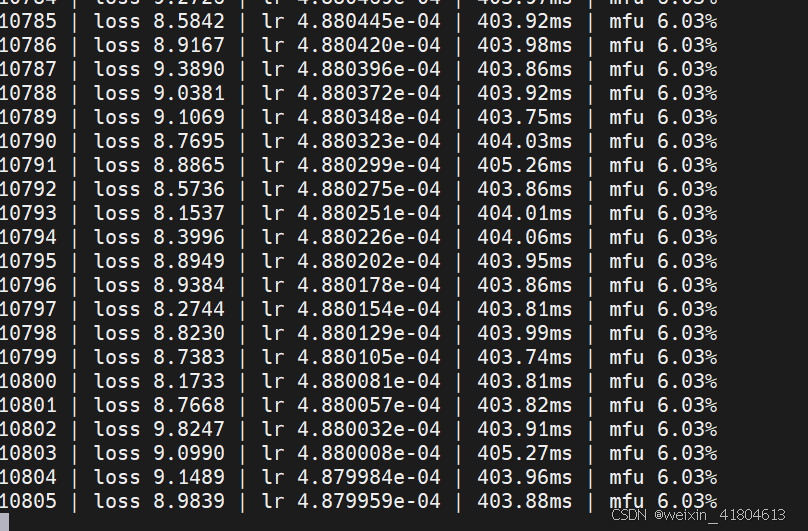
(但似乎还没有收敛)
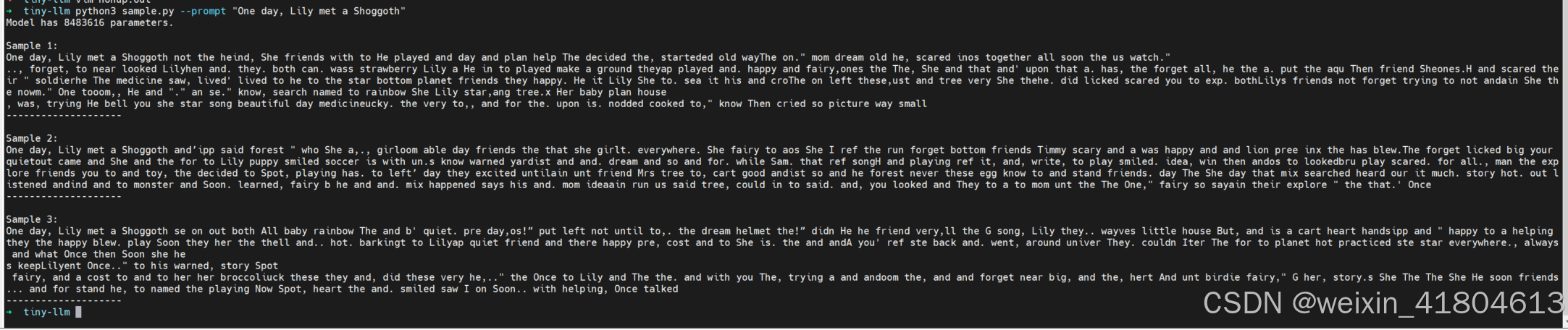
生成文本
最终的文本生成结果
python3 sample.py --prompt "One day, Lily met a Shoggoth"

















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









