







 该博客详细记录了一位参赛者在天池大赛中,如何利用Linux进行模型训练和Mac平台的Docker提交过程。首先在Linux环境下,通过conda安装torch1.6.0,克隆baseline项目,下载并处理数据,使用预训练模型进行训练。然后在Mac上,初次接触Docker,通过阿里云获取镜像,构建并提交结果。整个过程包括Dockerfile的编写,镜像构建,以及结果的推送。
该博客详细记录了一位参赛者在天池大赛中,如何利用Linux进行模型训练和Mac平台的Docker提交过程。首先在Linux环境下,通过conda安装torch1.6.0,克隆baseline项目,下载并处理数据,使用预训练模型进行训练。然后在Mac上,初次接触Docker,通过阿里云获取镜像,构建并提交结果。整个过程包括Dockerfile的编写,镜像构建,以及结果的推送。
天池-基于预训练任务的泛化能力
背景
这是基于Datawhale的一次学习机会,其中涉及到了transformer,torch,以及docker的应用。
比赛链接
baseline链接
流程
由于本地的计算资源有限,所以是会有切换平台(mac, linux)进行操作,不同平台承担的工作如下
- Linux平台(模型训练部分) 根据提供的额baseline结果,跑通对应的模型
- mac平台(docker部分) 根据docker,进行结果的提交
Linux平台(模型部分)
- 版本适配: 使用的是torch 1.6.0版本(小坑 在配torch版本的时候,使用pip install下载,用清华镜像之类的会快一些 但经常会出现跟cuda版本适配的问题,还是推荐用conda下载,下载可以根据清华镜像,先查看是否有对应的版本号,然后进行下载,这部分我是抄的这里的作业 )
- 模型训练:
将baseline项目克隆到本地
> git clone https://github.com/finlay-liu/tianchi-multi-task-nlp.git
到本地后对应的项目情况

3. 数据下载及处理
wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/OCEMOTION_train1128.csv
wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/b/ocemotion_test_B.csv
wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/TNEWS_train1128.csv
wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/b/tnews_test_B.csv
wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/OCNLI_train1128.csv
wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/b/ocnli_test_B.csv
将下载好的数据,存放与对应的数据集名称下,并将对应文件夹下的train.csv文件更改为total.csv以及test文件更改为test.csv
然后返回原始的目录下,运行数据处理的脚本
python generate_data.py
-
预训练模型下载
在huggingface中文预训练的网页中下载config.json、vocab.txt和pytorch_model.bin,把这三个文件放进tianchi-multi-task-nlp/bert_pretrain_model文件夹下。 -
模型训练
如果上述步骤没问题的话,就可以进行模型的训练了
根据train.py
python train.py
其中 下述的超参内容可以根据自己的机器情况或者其他实际需求进行更改。
train(epochs=20,batchSize=16, device='cuda:0', lr=0.0001, use_dtp=True, pretrained_model=pretrained_model, tokenizer_model=tokenizer_model, weighted_loss=True)
-
结果查看
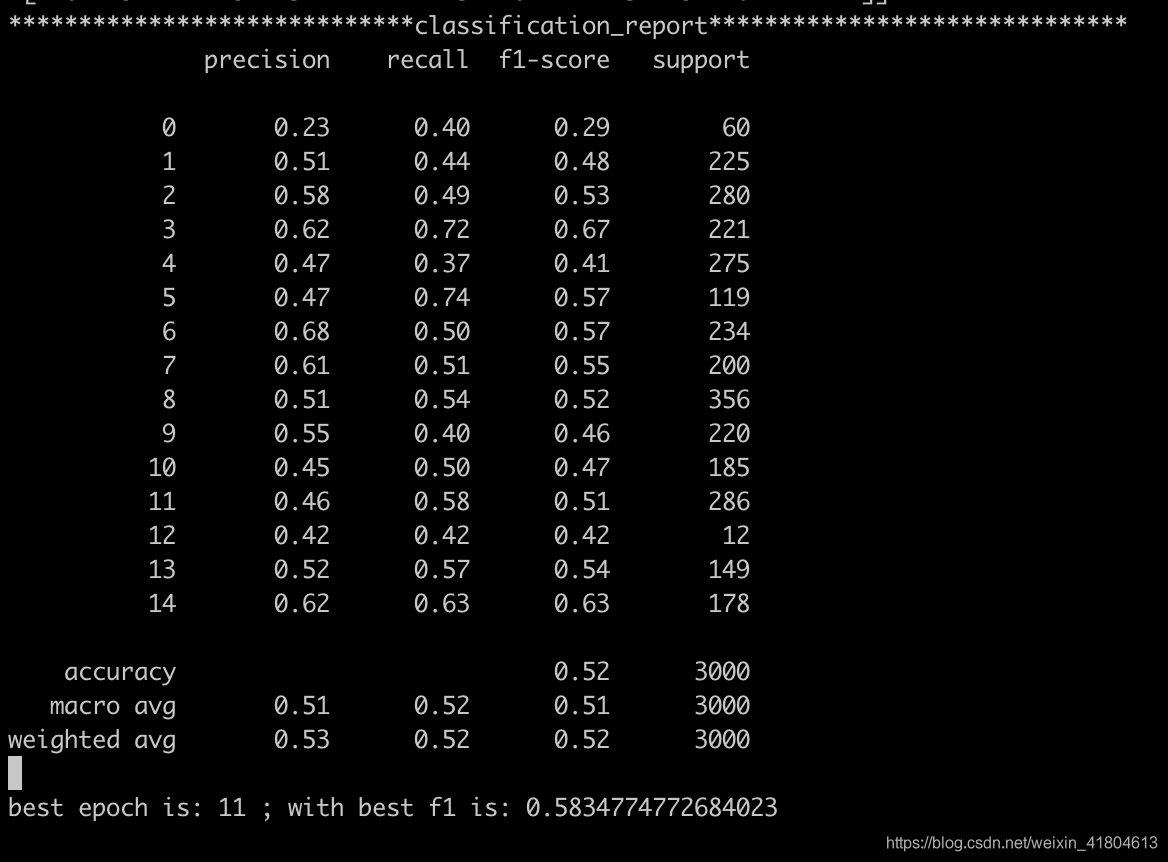
(ง •_•)ง 如果您能到这一步,大概就恭喜你,渡劫渡了一半 -
结果打包
运行结果预测的脚本,以及到结果的页面进行打包
python inference.py
zip -r ./result.zip ./*.json
MAC平台(docker提交部分)
由于先前是没有接触过docker部分,才算比较是渡劫(头裂)
相关的参考资料
mac的docker资料
天池的docker资料
mac中docker的安装
根据上述资料的话,是需要在阿里云上申请镜像的,然后会有一个个人主页,可以在个人主页中找到一些后续的需要使用到的信息
我的构建后长如下这个X样

-
准备
最终提交的文件夹中,有上述的这些内容(那个DS的忽略) -
构建镜像后的登陆
sudo docker login --username=xxx@mail.com registry.cn-hangzhou.aliyuncs.com
3.** 使用本地Dockefile进行构建**
进入到submission文件夹中,根据镜像构筑对应的项目
docker build -t registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0 .
构筑后,会有如此一行
Successfully built ed0c4b0e545f
这是待会需要用到的一个id
(根据群友的提示,也可以使用如下的指令查看到这一部分的id值)
docker images
- 结果提交
使用docker tag 指向对应的id号
sudo docker tag ed0c4b0e545f registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0
使用docker push 进行结果的提交
docker push registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0
各处的id以及版本号,需要根据个人进行修改,至此就可以完成提交(了吧?)
后续的进度会继续在本篇进行更新

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









