




 本文提出AOPE任务,利用SDRN模型解决aspect-opinion对的抽取与关系检测难题。模型通过OpinionEntityExtractionUnit和RelationDetectionUnit协同工作,结合ESM和RSM机制,有效融合了两个子任务。实验结果显示,SDRN在SemEval等数据集上优于传统pipeline方法和独立抽取策略。
本文提出AOPE任务,利用SDRN模型解决aspect-opinion对的抽取与关系检测难题。模型通过OpinionEntityExtractionUnit和RelationDetectionUnit协同工作,结合ESM和RSM机制,有效融合了两个子任务。实验结果显示,SDRN在SemEval等数据集上优于传统pipeline方法和独立抽取策略。
一、摘要
- 过往的方面级情感分析抽取任务中,往往只会抽取aspect and/or opinions,忽略了它们之间的关系。
- 本文提出的任务是 Aspect-Opinion Pair Extraction(AOPE) 任务,旨在成对抽取aspects和opinions。
- 本文提出的模型是Synchronous Double-channel Recurrent Network(SDRN 同步的双通道循环神经网络)。主要的思想是构建opinion entity extraction unit(观点实体抽取单元) 和 relation detection unit(关系检测单元) 两个通道去分别抽取观点实体和实体之间的关系。此外,模型还构建了synchronization unit(同步单元),包含Entity Synchronization Mechanism(ESM 实体同步机制) 和 Relation Synchronization Mechanism(RSM 关系同步机制) 去实现两个通道之间的联系。
二、介绍
-
AOPE任务的效果图如下:

-
作者认为AOPE任务主要存在下面三个挑战:
- 在一个句子中,aspect和opinion的关系十分复杂,需要十分好的模型才能发现它们之间的关系。
- aspect-opinion extraction和relation extraction 是两个子任务,要如何进行融合。
- 如果使得aspect-opinion extraction 和 relation extraction 两个子任务相互促进。
三、相关工作
- 最开始的工作是先抽取aspect或opinion,然后再基于抽取出来的去抽取另一个方面。但是这种方式,会造成error propagation(错误传播)。
- 后来的工作避免了错误传播和手工创建特征,但是没有学习抽取对象之间的关系。
四、模型整体架构
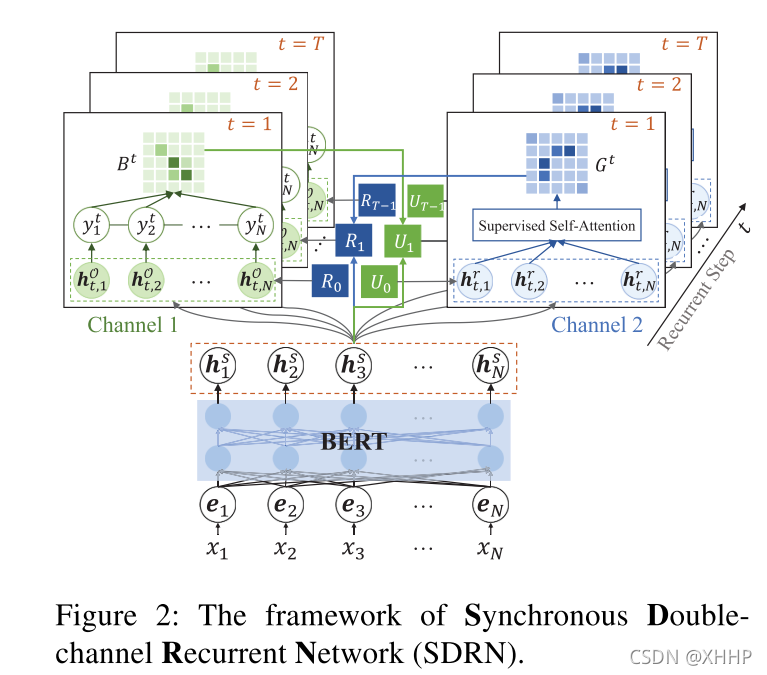
- 模型架构主要由以下几个方面组成:
- 首先,使用BERT作为encoding layer去学习文本的上下文特征。
- 接着,Channel 1(opinion entity extraction)和 Channel 2 (relation detection unit)分别进行aspect-opinion extraction和relations detection。
- 与此同时,在两个之间的是同步单元,完成两个channel之间的交互。
- 为了捕捉更高维度的特征,两个通道都使用了循环机制,最后得到aspect-opinion pairs.
五、Encoding Layer
- 对于给定的句子S,采用Word Piece算法进行分词操作,并加上[CLS]和[SEP]标签。
- 模型采用最原始的BERT模型进行编码,embedding由token embedding、segment embedding、position embedding构成。
- 经过BERT模型之后,取最后一个隐藏状态Hs={h1s 、h2s 、,…,hNs }作为模型接下来的输入。
六、Opinion Entity Extraction Unit
-
对于Entity Extraction,模型使用CRF来完成。CRF需要使用到==state score matrix(发射矩阵)==P∈RN*K去建模token和label之间的关系、==transition score matrix(转移矩阵)==Q∈RK*K去建模相邻label之间的 关系。其中K代表label的大小。
-
CRF采用的==标注集合是BIO,包含五个label==,BA (beginning of aspect), IA (inside of aspect), BP (beginning of opinion expression), IP (inside of opinion expression), and O (others)。
-
对于第t重循环预测的句子Yt={y1t,y2t,…,yNt},CRF计算得分的公式如下:
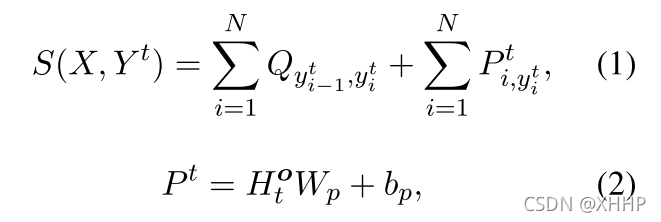
-
上式中的Hto={ht,1o,ht,2o,…,ht,No}代表的是Opinion Entity Extraction Unit第t步循环中的输入特征表示,它是通过context representation Hs和relation synchroization semantics Rt-1计算得到的。
-
接着,==预测句子的概率==可以通过下面的公式计算得到:
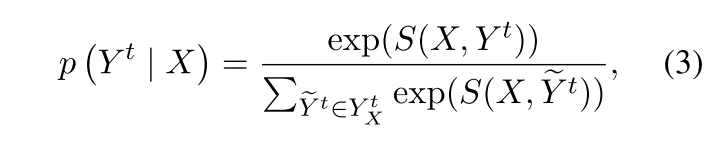
-
在训练的最后一步,模型会最大化答案序列的似然可能性P(Y|X)。在进行推断的时候则会使用维特比算法。
七、Relation Detection Unit
-
Relation Detection Unit使用的supervised self-attention mechanism(监督的自注意力机制)。
-
在第t步循环中,会计算注意力矩阵Gt∈RN*N,其中gi,jt代表第i个token和第j个token之间的关系,计算公式如下:
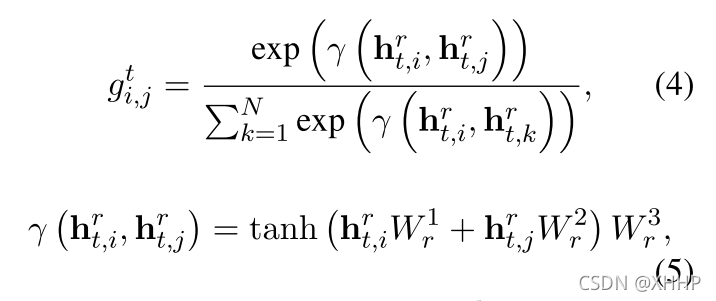
-
上式中的Htr={ht,1r,ht,2r,…,ht,Nr}代表的是Relation Detection Unit第t步循环中的输入特征表示,它是通过context representation Hs和entity synchroization semantics Ut-1计算得到的。
-
在Relation Detection Unit的最后一步循环T中,引入了监督信息到注意力矩阵GT中,通过最大化下面的似然函数:
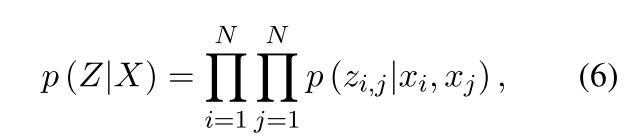
-
其中Z∈RN*N包含zi,j,关系概率计算公式如下:(zi,j = 1 代表第i个token和第j个token之间存在关系)
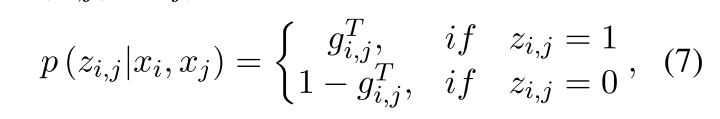
八、Entity Synchronization Mechanism
-
首先声明ESM抽取的是aspect或opinion实体内部的信息,而不是说apsect和opinion之间的relation 信息。
-
基于第t步预测的序列Yt和句子出现的概率,ut,i能够通过下面公式进行计算:
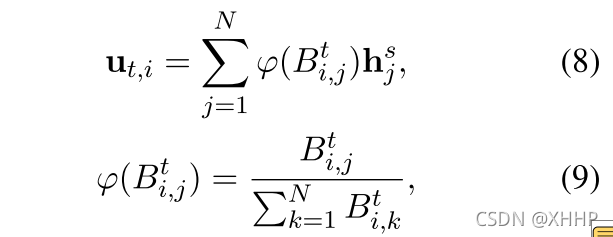
- 如果第i个token和第j个token属于同一个实体,Bi,jt代表第j个token对应label的概率,否则Bi,jt=0。
-
然后再将**ut,i和context representation his**整合起来,就能得到Relation Detection Unit中的隐藏状态序列:
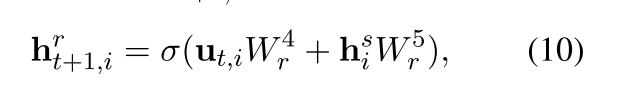
-
u0,i用零向量进行初始化。
九、Relation Synchronization Mechanism
-
首先声明这里乍一看他这里注意力机制其实只是关注到了token级别,没有关注到entity级别,因为他这里注意力其实是使用的token之间的注意力。
但是这里其实应该是有融合entity级别的信息的,因为另一个channel有传递过来entity的信息。
RSM抽取的是aspect和opinion之间的relation信息。
-
基于第t步循环的注意力矩阵,rt,i能够通过下面公式进行计算:(β是一个阈值,ϕ(·)是归一化函数)
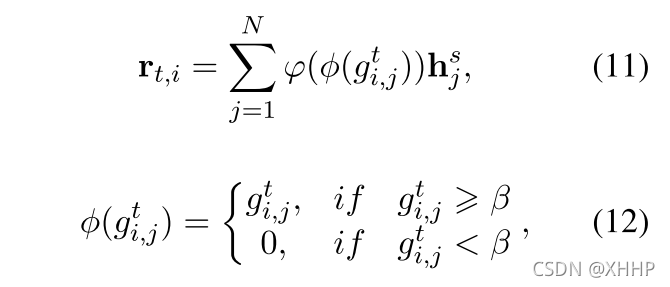
-
然后再将**rt,i和context representation his**整合起来,就能得到Entity Extraction Unit中的隐藏状态序列:
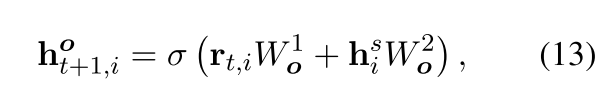
十、联合学习
-
对于Entity Extraction Unit,损失函数如下:
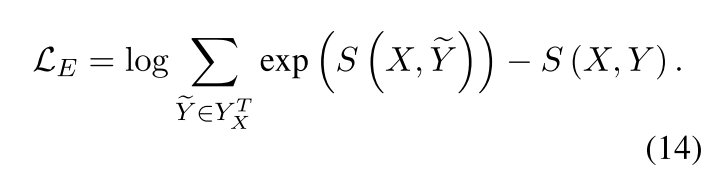
-
对于Relation Detetion Unit,损失函数如下:
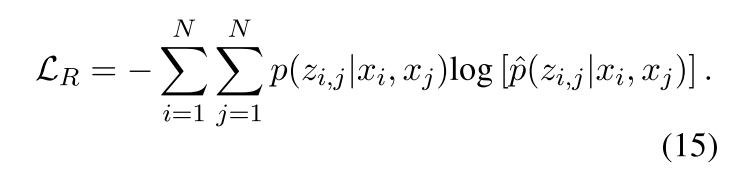
-
进行整合,对于整个模型就是要求下面的最小损失:
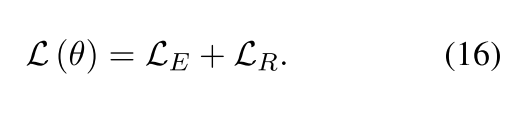
十一、推断
-
我们输入一个句子,然后通过Entity Extraction Unit可以得到抽取的aspect-opinion pairs。
-
然后,给定一对 aspect a和 opinion o,我们通过计算relation detection unit计算它们之间的相关性,只有当超过一定阈值,才认为是有效的aspect-opinion pairs。
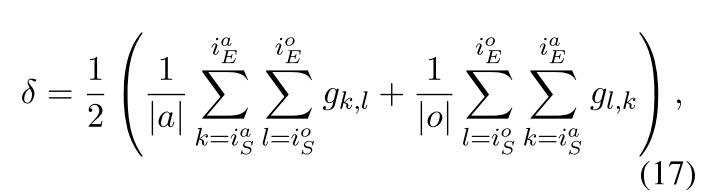
十二、实验
-
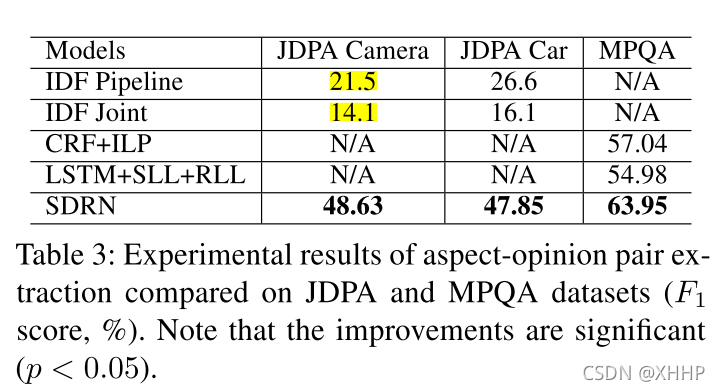
本文的实验使用的是SemEval 2014、SemEval 2015、MPQA version 2.0 corpus、J.D. Power and Associates Sentiment Corpora数据集。
-
实验表明循环次数超过2之后就无法获得更好的效果

-
实验表明SDRN效果会比pipeline(单独抽取aspect和opinion)+RD(关系抽取)的模型取得更好的效果。
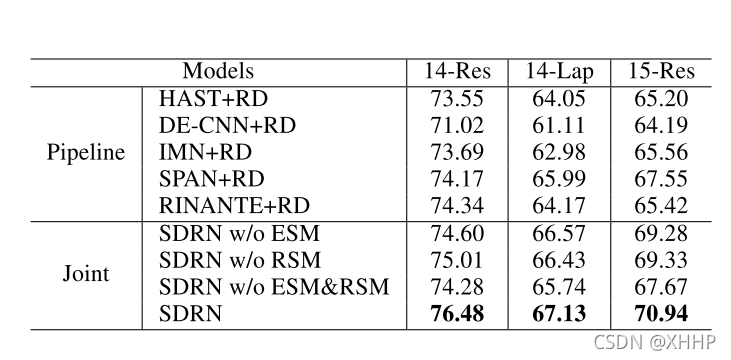
-
作者还将SDRN和joint model(共同抽取aspect和opinion和relation,但是没有建立实时的信息交互)进行比较,可以发现也有较好的提升。

















 1165
1165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









