







Python3数据科学汇总: https://blog.youkuaiyun.com/weixin_41793113/article/details/99707225
import numpy as np
import pandas as pd
from pandas import Series, DataFrame# Series的排序
s1 = Series(np.random.randn(10))
s1 ##np.random.randn(10)生成10个正态分布(0,1)的随机数据 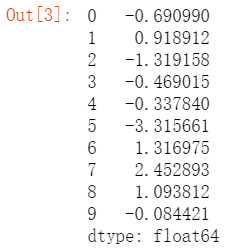
s1.values ##查看Series s1的值![]()
s1.index ## 查看s1的索引![]()
s2 = s1.sort_values(ascending=False) ##降序排序,默认是升序True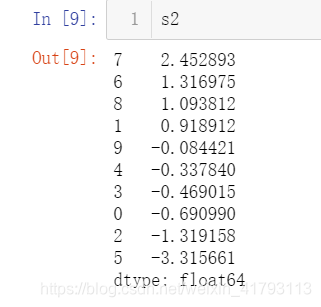
s2.sort_index() ##按索引升序排序
s2.sort_index(ascending=False) ##按索引降序排序
# Dataframe的排序
df1 = DataFrame(np.random.randn(40).reshape(8,5), columns=['A','B','C','D','E'])
df1 ##使用numpy生成40个随机的正态分布数据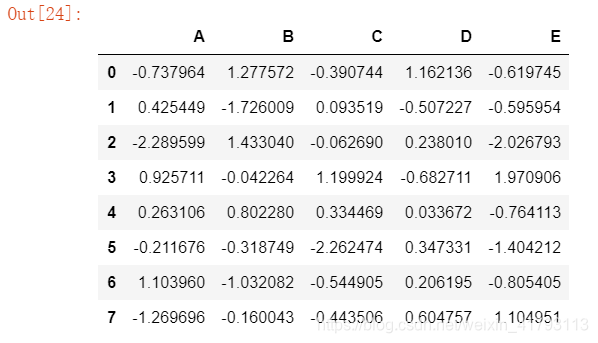
df1['A'].sort_values()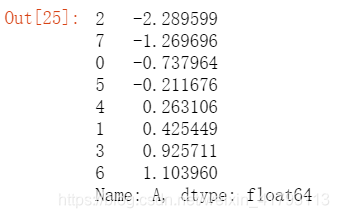
df2 = df1.sort_values('A') ##按属性'A'的大小排序,默认升序
df2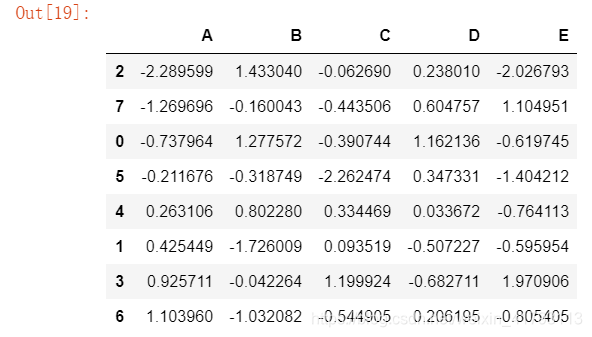
df2.sort_index() ##按索引升序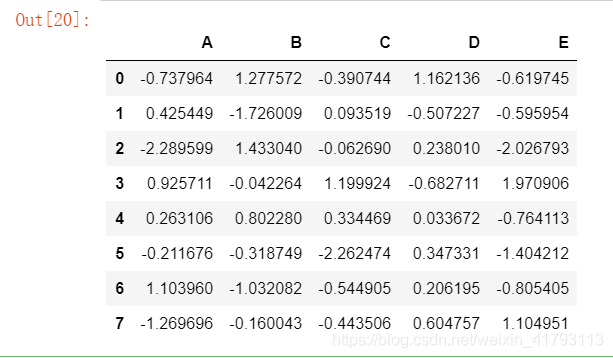
Last
# 一个简单的小例子,对movie_metadata.csv的imdb进行排序
f = open('../homework/movie_metadata.csv')
movie = pd.read_csv(f)
imdb = movie[["movie_title", "director_name","imdb_score"]].sort_values("imdb_score", ascending=False)
imdb.to_csv('imdb.csv')

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









