




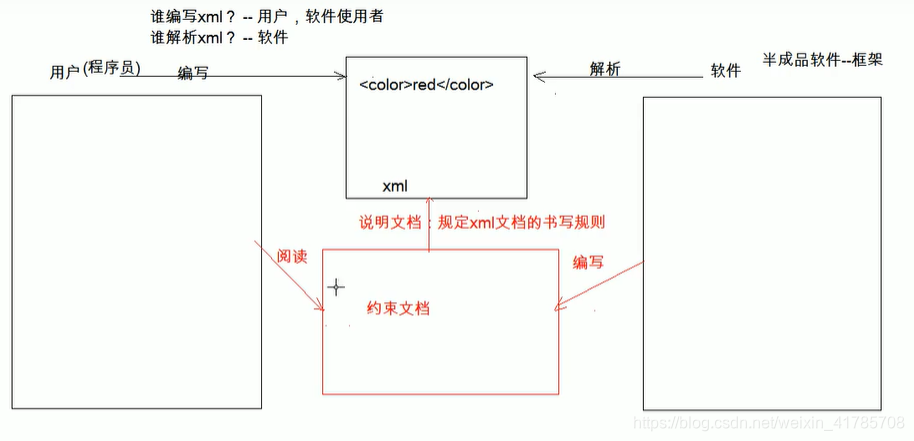
 本文详细介绍了XML约束、DTD、schema及其实例,展示了如何使用DOM和SAX解析器处理student.xml,并探讨了Jsoup在不同场景的应用,包括快速入门、选择器查询和Document/Element对象操作。
本文详细介绍了XML约束、DTD、schema及其实例,展示了如何使用DOM和SAX解析器处理student.xml,并探讨了Jsoup在不同场景的应用,包括快速入门、选择器查询和Document/Element对象操作。
xml






xml_dtd_约束

student.dtd 约束文件
<!ELEMENT students (student+) >
<!ELEMENT student (name,age,sex)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!ATTLIST student number ID #REQUIRED>
student.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!--引用外部约束文件-->
<!--<!DOCTYPE students SYSTEM "student.dtd">-->
<!--内部约束文件-->
<!DOCTYPE students [
<!ELEMENT students (student+) >
<!ELEMENT student (name,age,sex)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!ATTLIST student number ID #REQUIRED>
]>
<students>
<student number="s001">
<name>zhangsan</name>
<age>23</age>
<sex>hehe</sex>
</student>
<student number="s002">
<name>lisi</name>
<age>24</age>
<sex>female</sex>
</student>
</students>
解读:
<!ELEMENT students (student+) > //元素sudents 出现一次或者多次 根标签为students
<!ELEMENT student (name,age,sex)>//student标签必须包含 name,age,sex
<!ELEMENT name (#PCDATA)>//name的属性必须为字符串
<!ELEMENT age (#PCDATA)>//name的属性必须为字符串
<!ELEMENT sex (#PCDATA)>//name的属性必须为字符串
<!ATTLIST student number ID #REQUIRED> //student中id的number的属性必须唯一
schema
student.xsd文件
<?xml version="1.0"?>
<xsd:schema xmlns="http://www.itcast.cn/xml"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itcast.cn/xml" elementFormDefault="qualified">
<xsd:element name="students" type="studentsType"/>
<xsd:complexType name="studentsType">
<xsd:sequence>
<xsd:element name="student" type="studentType" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="studentType">
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="age" type="ageType" />
<xsd:element name="sex" type="sexType" />
</xsd:sequence>
<xsd:attribute name="number" type="numberType" use="required"/>
</xsd:complexType>
<xsd:simpleType name="sexType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="male"/>
<xsd:enumeration value="female"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="ageType">
<xsd:restriction base="xsd:integer">
<xsd:minInclusive value="0"/>
<xsd:maxInclusive value="256"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="numberType">
<xsd:restriction base="xsd:string">
<xsd:pattern value="heima_\d{4}"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:schema>
students.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!--
1.填写xml文档的根元素
2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3.引入xsd文件命名空间. xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
4.为每一个xsd约束声明一个前缀,作为标识 xmlns="http://www.itcast.cn/xml"
-->
<students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itcast.cn/xml"
xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
>
<student number="heima_0001">
<name>tom</name>
<age>18</age>
<sex>male</sex>
</student>
</students>
解读
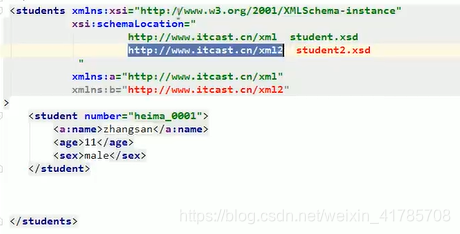
<a:students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.itcast.cn/xml1 student.xsd
http://www.itcast.cn/xml2 student2.xsd
"
xmlns:a="http://www.itcast.cn/xml"
xmlns:b="http://www.itcast.cn/xml"
>
<a:student number="heima_0001">
<a:name>tom</a:name>
<a:age>18</a:age>
<a:sex>male</a:sex>
</a:student>
</a:students>
- 在students前面添加“a:”,后面的所有标签都要加上前缀"a:";
- xsi:schemaLocation中添加约束文档的地址;
- xmlns="http://www.itcast.cn/xml"默认无前缀.
- xmlns:a="http://www.itcast.cn/xml"默认有前缀。当有多个约束文档的时候,为了区分,可以添加上前缀。
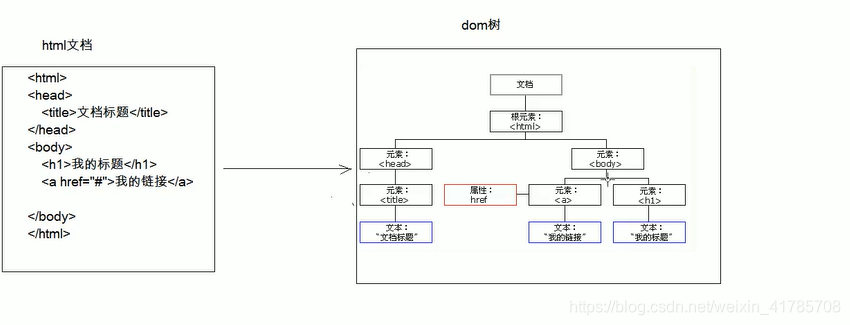

- DOM运用在服务器端,SAX运用在移动端。
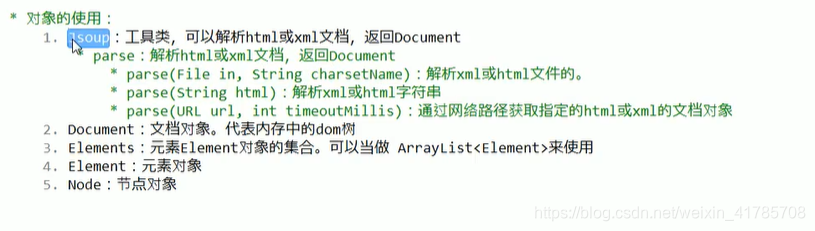
常见的解析器Jsoup

快速入门
<?xml version="1.0" encoding="utf-8" ?>
<students>
<student number="heima_0001">
<name>Tom</name>
<age>12</age>
<sex>male</sex>
</student>
<student number="heima_0002">
<name>Tom2</name>
<age>123</age>
<sex>female</sex>
</student>
</students>
package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
/*
Jsoup快速入门
*/
public class JsoupDemo01 {
public static void main(String[] args) throws IOException {
//2.获取Document对象,根据xml文档获取
//2.1获取student.xml的path
String path=JsoupDemo01.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document= Jsoup.parse(new File(path),"utf-8");
//3.获取元素对象 Element
Elements elements=document.getElementsByTag("name");
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element=elements.get(0);
//3.2获取数据
String name=element.text();
System.out.println(name);
}
}
xml_解析_Jsoup对象
package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.File;
import java.io.IOException;
import java.net.URL;
public class JsoupDemo02 {
public static void main(String[] args) throws IOException {
//2.获取Document对象,根据xml文档获取
//2.1获取student.xml的path
String path=JsoupDemo01.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document= Jsoup.parse(new File(path),"utf-8");
//System.out.println(document);//html文档
//3.parse(String html):解析xml或HTML字符串 ;
//str中的字符串就是从xml中复制的xml文件的内容;
String str="<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n" +
"<students>\n" +
"<student number=\"heima_0001\">\n" +
"\t<name>Tom</name>\n" +
"\t<age>12</age>\n" +
"\t<sex>male</sex>\n" +
"</student>\n" +
"\n" +
"<student number=\"heima_0002\">\n" +
"\t<name>Tom2</name>\n" +
"\t<age>123</age>\n" +
"\t<sex>female</sex>\n" +
"</student>\n" +
"</students>";
Document document1=Jsoup.parse(str);
System.out.println(document);//将xml文件解析成HTML文档
//3.parse(URL url,int timeoutMillis):通过网络路径获取指定的HTML或者xml的文档对象
URL url=new URL("https://baike.baidu.com/item/%E7%A8%8B%E5%BA%8F%E5%91%98/62748?fr=aladdin");
Document document2=Jsoup.parse(url,10000);
System.out.println(document2);
}
}
- 第一种是常见的运用;第二种了解即可;第三种运用在网络爬虫程序上。
Document对象

package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
/*
Document/Element对象功能
*/
public class JsoupDemo03 {
public static void main(String[] args) throws IOException {
//2.获取Document对象,根据xml文档获取
//2.1获取student.xml的path
String path=JsoupDemo01.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document= Jsoup.parse(new File(path),"utf-8");
//System.out.println(document);//html文档
//3.获取元素对象
//3.1获取所有student对象
Elements elements=document.getElementsByTag("student");
System.out.println(elements);//将所有的标签打印了出来
System.out.println("------------------------");
//3.获取元素的对象了
//3.1获取所有student对象
Elements elements1=document.getElementsByAttribute("id");
System.out.println(elements1);
System.out.println("------------------------");
//3.2 获取number属性值为heima_0001元素对象
Elements elements2=document.getElementsByAttributeValue("number","heima_0001");
System.out.println(elements2);
System.out.println("------------------------");
//3.3获取id属性值的元素对象
Element itcast=document.getElementById("cast");
System.out.println(itcast);
}
}
Element对象

package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.w3c.dom.ls.LSOutput;
import java.io.File;
import java.io.IOException;
public class JsoupDemo4 {
public static void main(String[] args) throws IOException {
//2.获取Document对象,根据xml文档获取
//2.1获取student.xml的path
String path=JsoupDemo01.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document= Jsoup.parse(new File(path),"utf-8");
//System.out.println(document);//html文档
//通过Document对象获取那么标签,获取所有的name标签,可以获取到两个
Elements elements=document.getElementsByTag("name");
System.out.println(elements.size());
System.out.println("------------------------------");
//通过element对象获取子标签对象
Element element_student=document.getElementsByTag("student").get(0);
Elements ele_name= element_student.getElementsByTag("name");
System.out.println(ele_name.size());
//获取student对象的属性值
String number=element_student.attr("NUMBER");
System.out.println(number);
System.out.println("------------");
//获取文本内容
String text=ele_name.text();//获取所有字标签的纯文本内容
String html=ele_name.html();//获取标签体的所有内容(包括子标签和文本内容)
System.out.println(text);
System.out.println(html);
}
}
Jsoup根据选择器查询
- 快捷查询方式:
- 1.selector:选择器
**使用的方法:Elements select(String cssquery)
***语法:参考Selector类中定义的语法
package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
public class JsoupDemo5 {
public static void main(String[] args) throws IOException {
//2.获取Document对象,根据xml文档获取
//2.1获取student.xml的path
String path=JsoupDemo01.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document= Jsoup.parse(new File(path),"utf-8");
//3.查询name标签
Elements elements=document.select("name");
System.out.println(elements);
System.out.println("--------------------------------");
//4.查询id值为itcast的元素
Elements elements1=document.select("#itcast");
System.out.println(elements1);
System.out.println("--------------------------------");
//5.获取student标签并且number属性值为heima_0001的age子标签
//5.1获取student标签并且number属性值为heima_0001
Elements elements2=document.select("student[number=\"heima_0001\"]");
System.out.println(elements2);
System.out.println("--------------------------------");
//5.2获取student标签并且number属性值为heima_0001的age子标签
Elements elements3=document.select("student[number=\"heima_0001\"] > age" );
System.out.println(elements3);
}
}

















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









