







 本文详细阐述了MapReduce的整个流程,包括Map和Reduce阶段,重点讲解了shuffle机制、join原理以及reduce阶段排序的目的。讨论了分区内的数据特性和分区间数据的特性,展现了MapReduce如何处理大规模数据的高效性。
本文详细阐述了MapReduce的整个流程,包括Map和Reduce阶段,重点讲解了shuffle机制、join原理以及reduce阶段排序的目的。讨论了分区内的数据特性和分区间数据的特性,展现了MapReduce如何处理大规模数据的高效性。
文章目录
1. 简述MapReduce整个流程 *
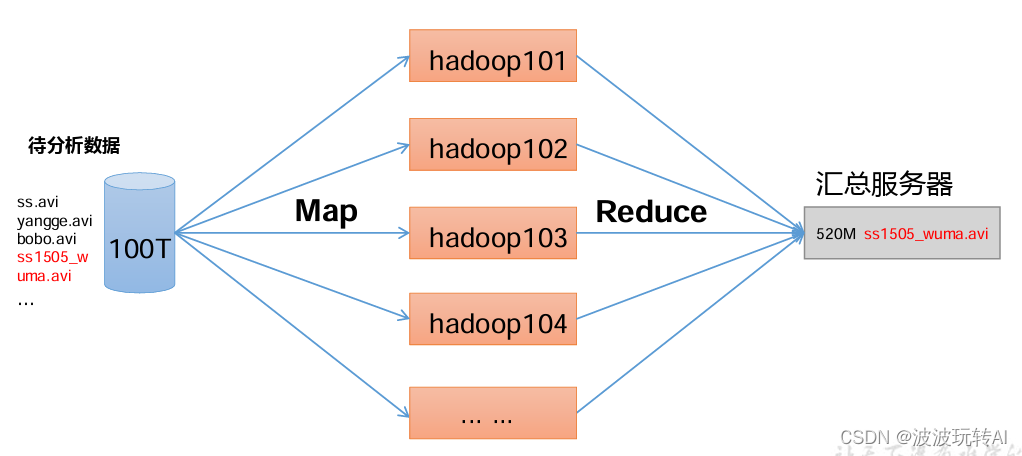
MapReduce 将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce 阶段对Map结果进行汇总
具体操作流程:
-
数据划分(Input Splitting):开始时,输入数据被分割成逻辑上的小块,每个块被称为Input Split。
-
映射(Map):每个Input Split 由一个或多个Map任务处理,这些任务通过映射函数(Map函数)将数据处理成中间键值对。
-
合并(Shuffle and Sort):中间键值对被分发到不同节点,以便相同键的值能被发送到同一个Reduce任务,同时对键进行排序,确保相同的键在Reduce阶段按顺序到达。
-
归约(Reduce):Reduce任务接收来自Map阶段的中间键值对,并根据归约函数(Reduce函数)将它们合并成更小的一组值。
-
输出(Output):Reduce阶段生成的结果被写入输出目标,如文件系统中的文件或数据库中的表格,作为MapReduce过程的最终结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









