




文章目录
1. 简单介绍一下Flink
Flink 是一个面向流处理和批处理的分布式数据计算引擎,能够基于同一个Flink运行,可以提供流处理和批处理两种类型的功能。 在 Flink 的世界观中,一切都是由流组成的,离线数据是有界的流;实时数据是一个没有界限的流:这就是所谓的有界流和无界流。
2. Flink 的运行必须依赖Hadoop组件吗?
Flink 可以完全独立于Hadoop,在不依赖Hadoop组件下运行。但是做为大数据的基础设施,Hadoop体系是任何大数据框架都绕不过去的。Flink可以集成众多Hadooop 组件,例如Yarn、Hbase、HDFS等等。例如,Flink可以和Yarn集成做资源调度,也可以读写HDFS,或者利用HDFS做检查点。
3. Flink 和 Spark Streaming 的区别?
- Spark以批处理为根本
- Spark数据模型:Spark 采用RDD 模型,Spark Streaming 的DStream实际上也就是一组组小批数据RDD 的集合
- Spark运行时架构:Spark 是批计算,将DAG 划分为不同的stage,一个完成后才可以计算下一个
- Flink以流处理为根本
- Flink数据模型:Flink 基本数据模型是数据流,以及事件(Event)序列
- Flink运行时架构:Flink 是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
- 架构模型不同
- Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor
- Flink 在运行时主要包含:Jobmanager、Taskmanager 和 Slot
- 时间机制
- Spark Streaming 支持的时间机制有限,只支持处理时间。
- Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。
4. Flink集群角色
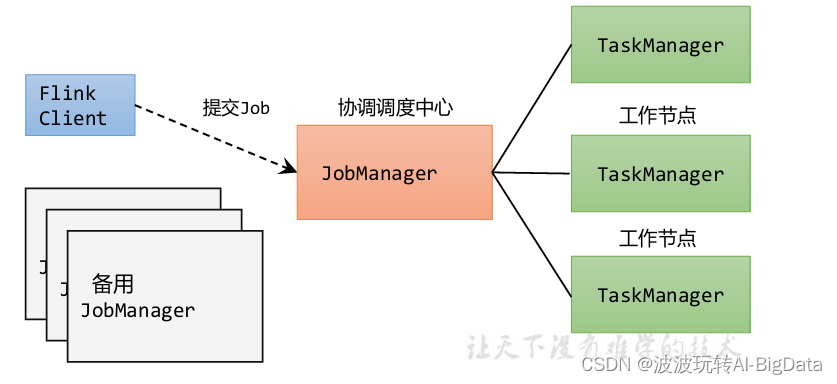
- 客户端(Client):代码由客户端获取并做转换,之后提交给JobManager
- JobManager:就是Flink集群里的“管事人”,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的TaskManager。
- TaskManager:就是真正“干活的人”,数据的处理操作都是它们来做的。
5. Flink核心概念
5.1 并行度
- 并行子任务和并行度
一个算子任务就被拆分成了多个并行的“子任务”(subtasks),再将它们分发到不同节点,就真正实现了并行计算。
在 Flink 执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。
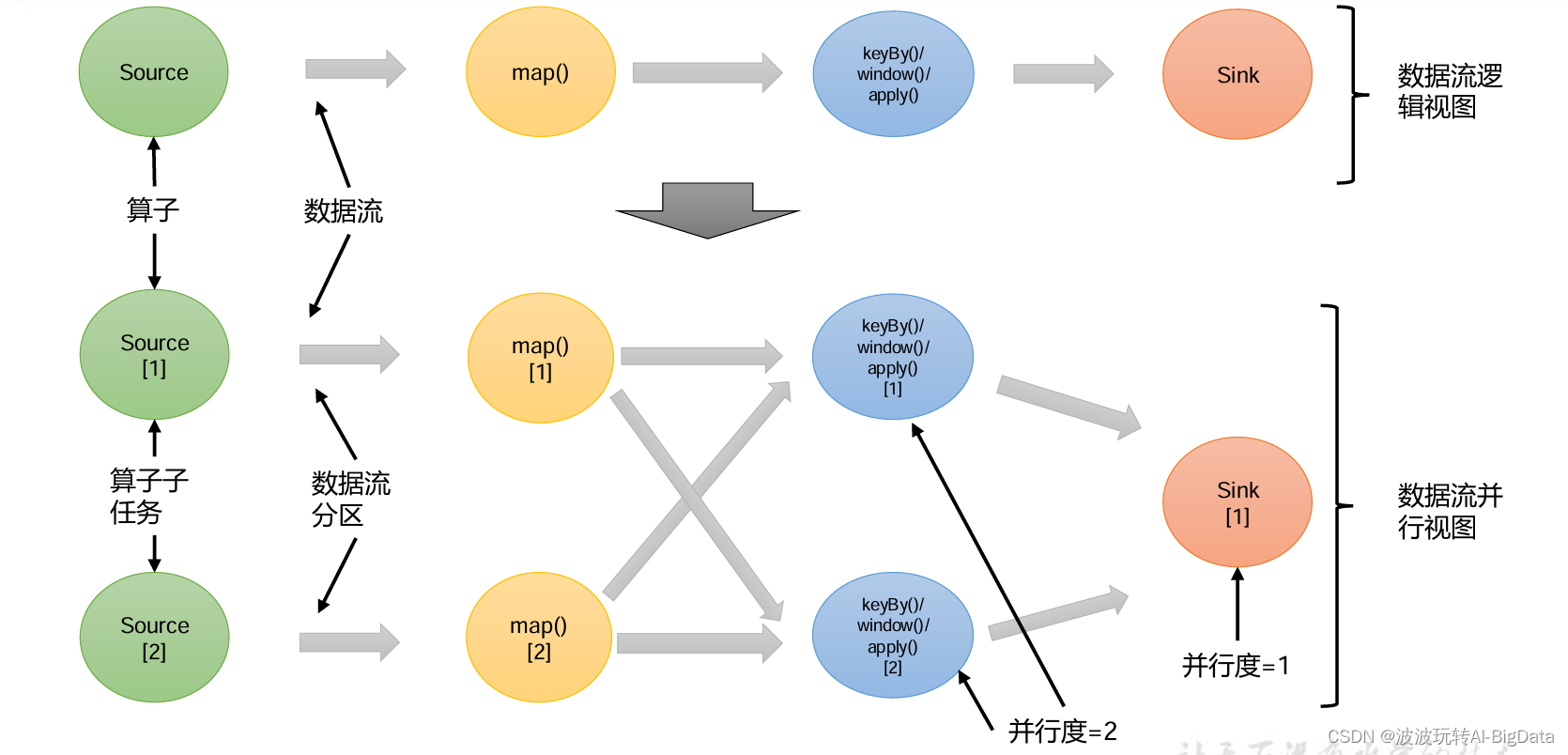
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
例如:如上图所
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8927
8927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









