




 本文详细介绍了如何在Windows环境下配置Spark本地运行,并通过IDEA编写Spark Scala程序,使用Maven打包成jar包,最后将jar包上传到本地Spark集群进行运行。步骤包括下载安装Spark、配置环境、编写Spark程序、添加Maven打包依赖、打包程序以及在集群上运行jar包。
本文详细介绍了如何在Windows环境下配置Spark本地运行,并通过IDEA编写Spark Scala程序,使用Maven打包成jar包,最后将jar包上传到本地Spark集群进行运行。步骤包括下载安装Spark、配置环境、编写Spark程序、添加Maven打包依赖、打包程序以及在集群上运行jar包。
配置spark在本地上运行
1、配置本地环境(我的本地系统为win10)
(1)在官网下载spark安装包:spark-3.0.0-bin-hadoop3.2.tgz,下载页面见下图:
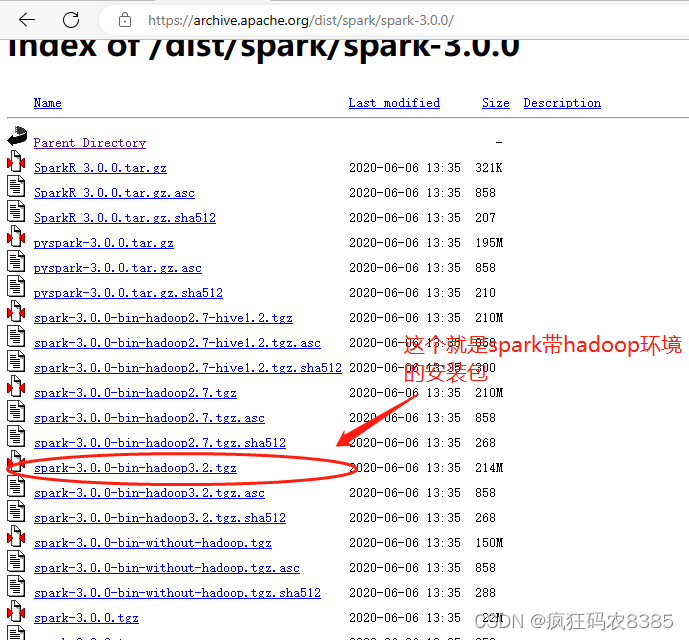
(2)解压spark安装包到本地磁盘,这里我的路径为D:\java,如图:

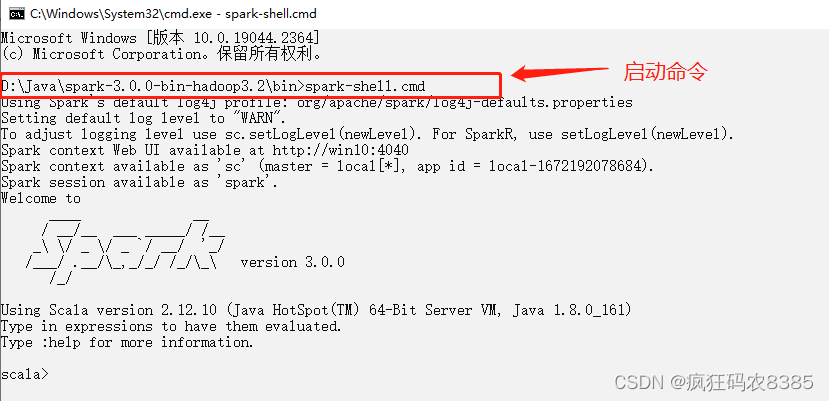
(3)打开cmd界面,进入安装目录下的bin目录,执行spark-shell.cmd命令,启动spark本地环境,看到如下界面说明启动成功。
2、将spark程序打成jar包,在本地集群环境运行。
(1)使用IDEA编写spark代码示例如下。
package chapter01
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object HelloWorld {
def main(args: Array 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









