






服务器:登录注册魔塔社区服务器后,免费赠送36小时的GPU(8核 32GB 显存24G的环境 )和64小时的GPU(8核 32GB 显存16G)
预训练模型:qwen2.5-7B-Instruct
微调数据集:ruozhiba_qa(魔塔社区的数据格式需要修改,最好从huggingface上下载数据集,可直接使用)
微调框架:LLama-factory
第一步:打开魔塔社区-我的Notebook
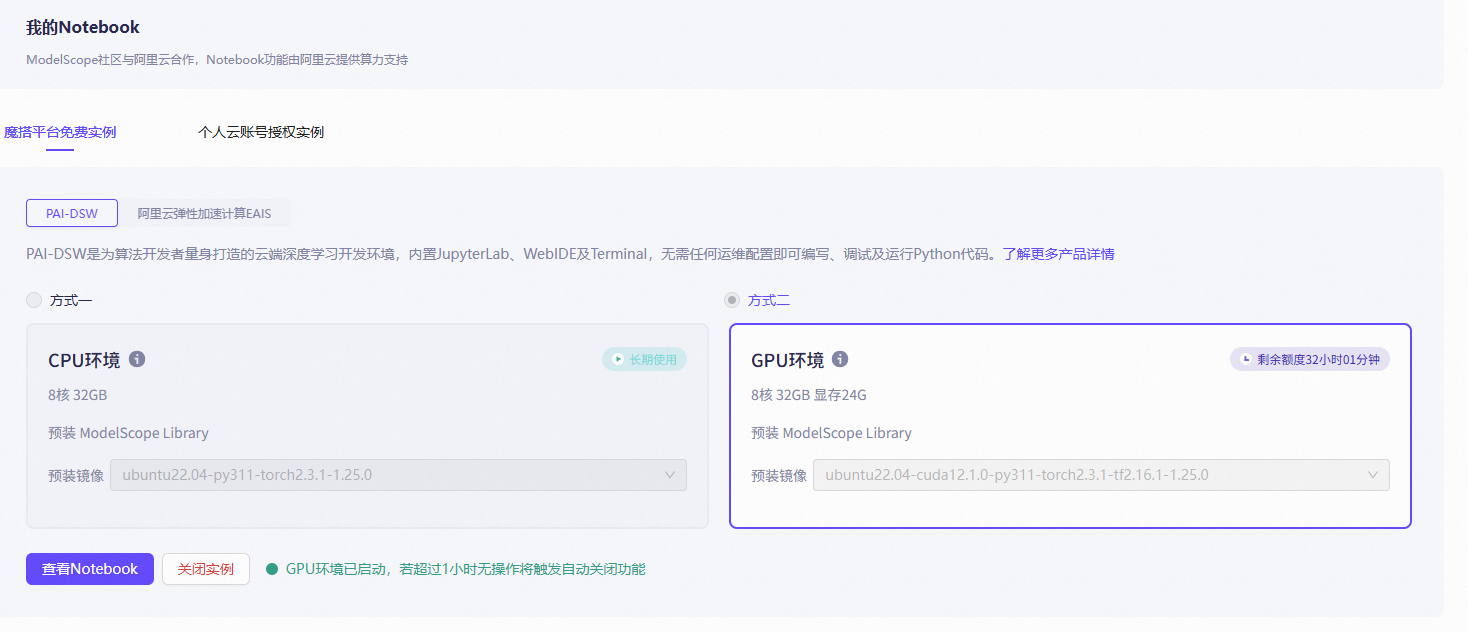
第二步:安装环境
先打开一个新tab页,点击左上角的+号,选择terminal
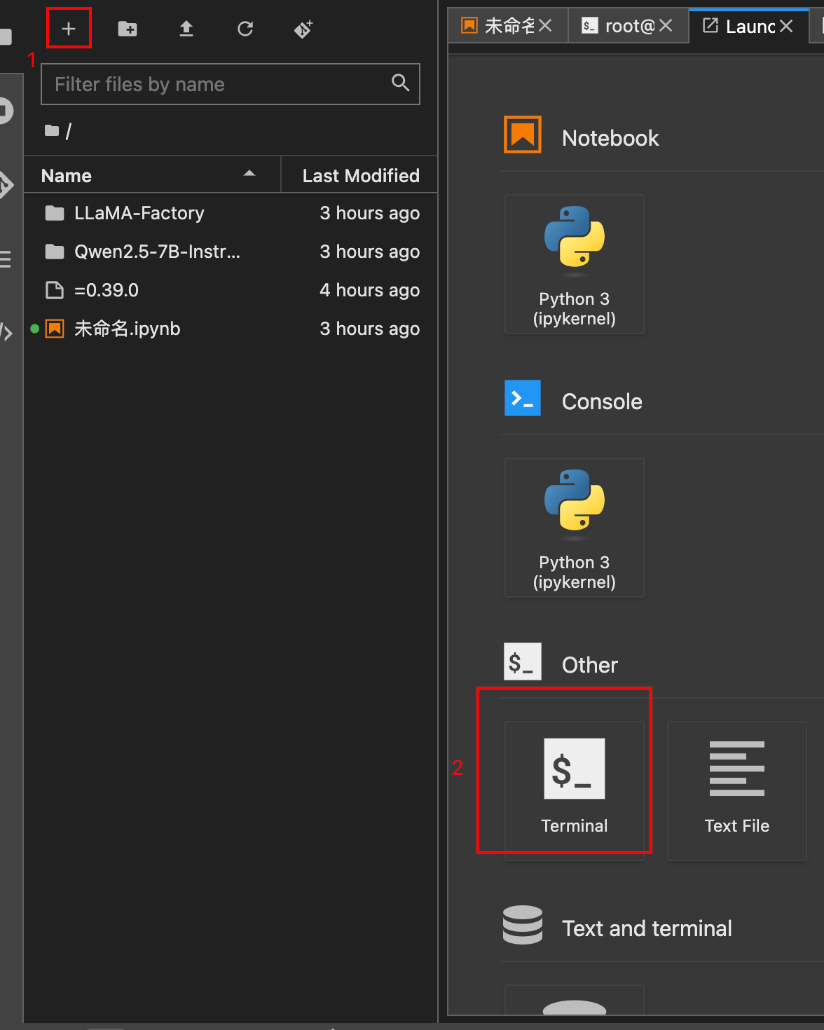
安装依赖库
pip3 install --upgrade pip
pip3 install bitsandbytes>=0.39.0说明:bitsandbytes 是一个由 Facebook Research 开发的轻量级开源库(基于 MIT 协议),专注于通过低比特精度量化技术优化深度学习模型的训练和推理效率。即:使一个专注于优化计算效率的库。
创建并激活虚拟环境
默认的镜像是不支持conda命令的,若想使用conda命令,则需要手动安装
使用python命令创建虚拟环境
# 创建虚拟环境的时候可以先查询python版本,使用特定的版本创建虚拟环境
python --version
# 3.11.11
# python3.11 -m env <虚拟环境名称>:若服务器内同事安装多个版本的python的话,创建虚拟环境的时候需
# 要明确指定python3.11命令
python3.11 -m env myenv
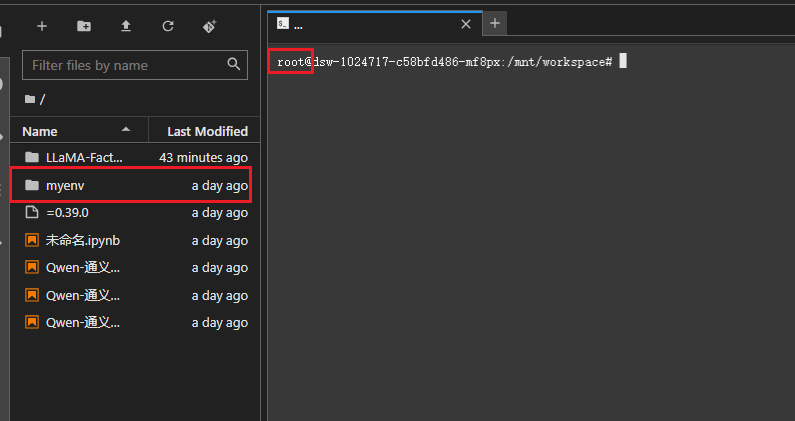
# 激活虚拟环境:source <虚拟环境名称>/bin/active激活虚拟环境前:
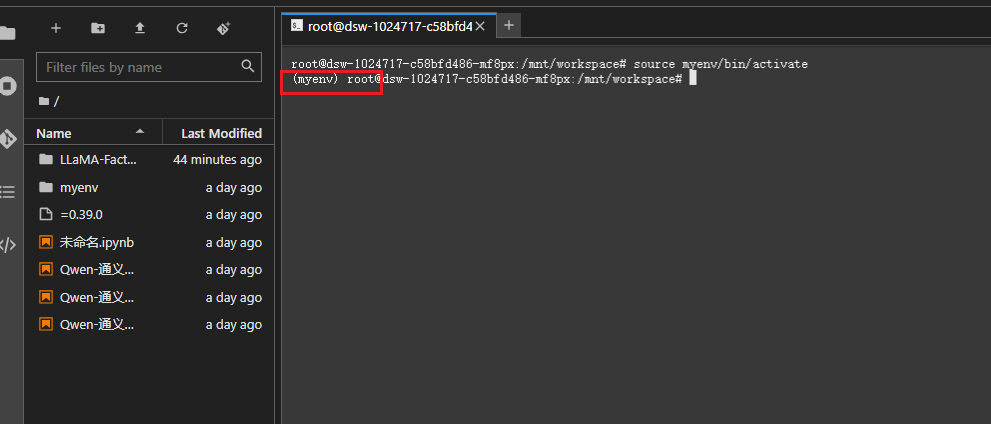
激活虚拟环境后:
安装LLaMAFactory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"第三步:下载模型和数据集
在魔搭的模型库中找到通义千问2.5-7B-Instruct
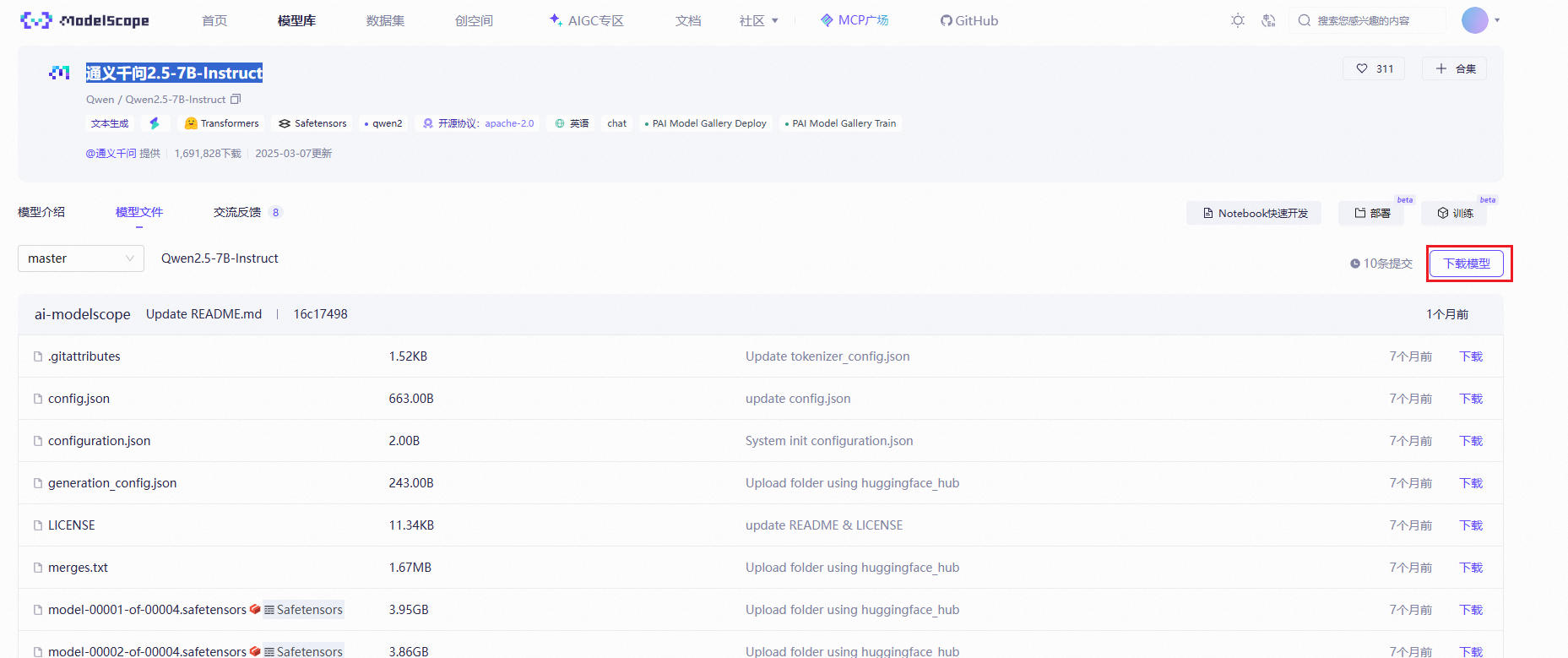
我们选择git下载:
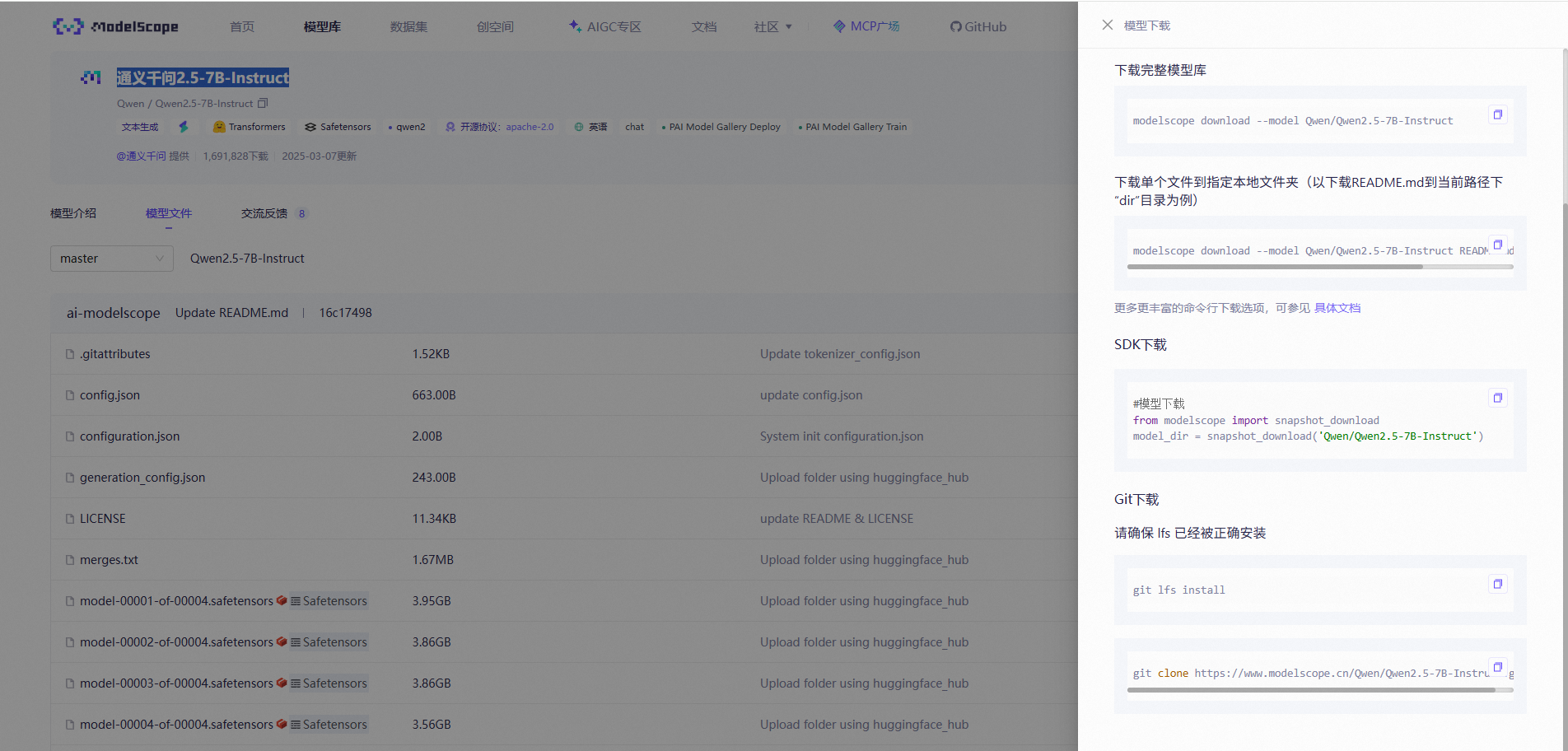
首先复制安装lfs的命令(若已安装,则忽略)
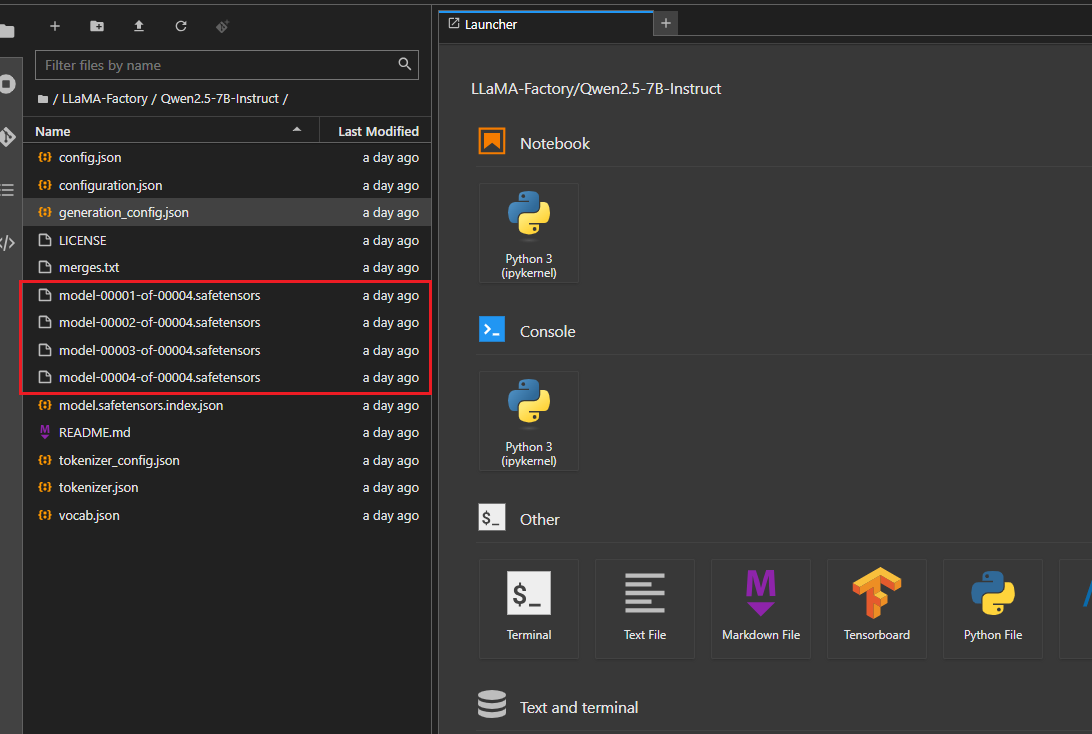
然后复制模型下载的git命令直接在Notebook中的Terminal中执行命令即可下载模型,下载号之后,我们可以看到相应的文件
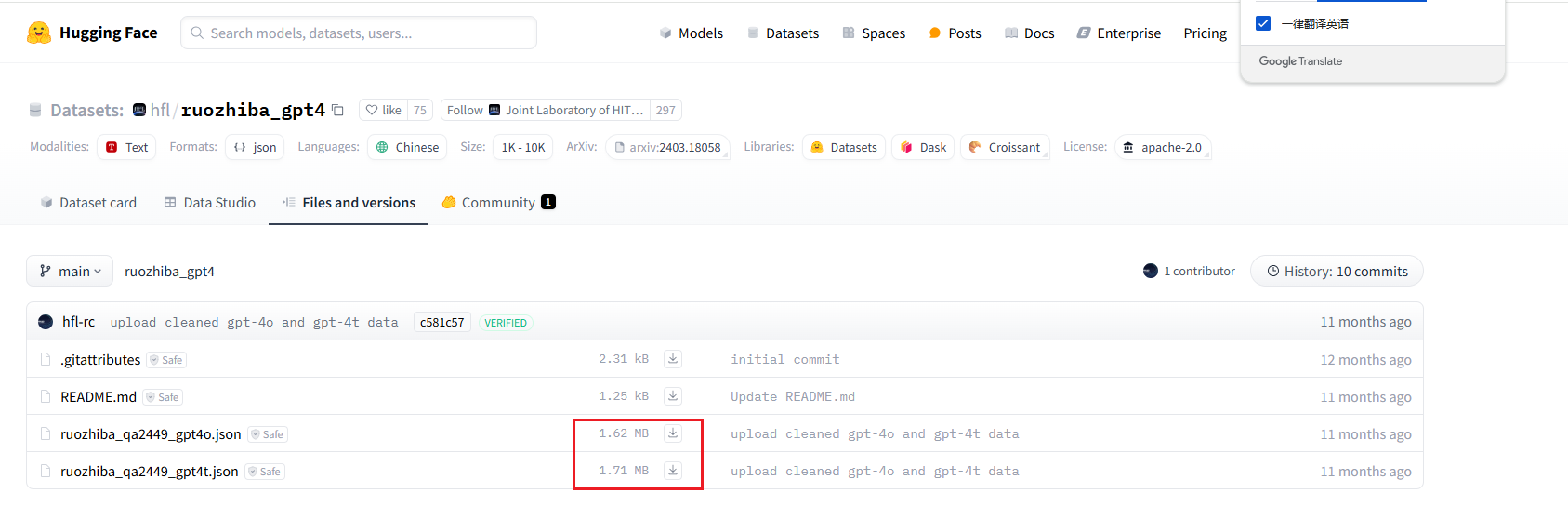
下载数据集:数据集使用ruozhiba
https://huggingface.co/datasets/hfl/ruozhiba_gpt4/tree/main
微调大模型
修改微调配置文件
在窗口的左侧的文件列表,进入到LLaMA-Factory/examples/train_lora中:
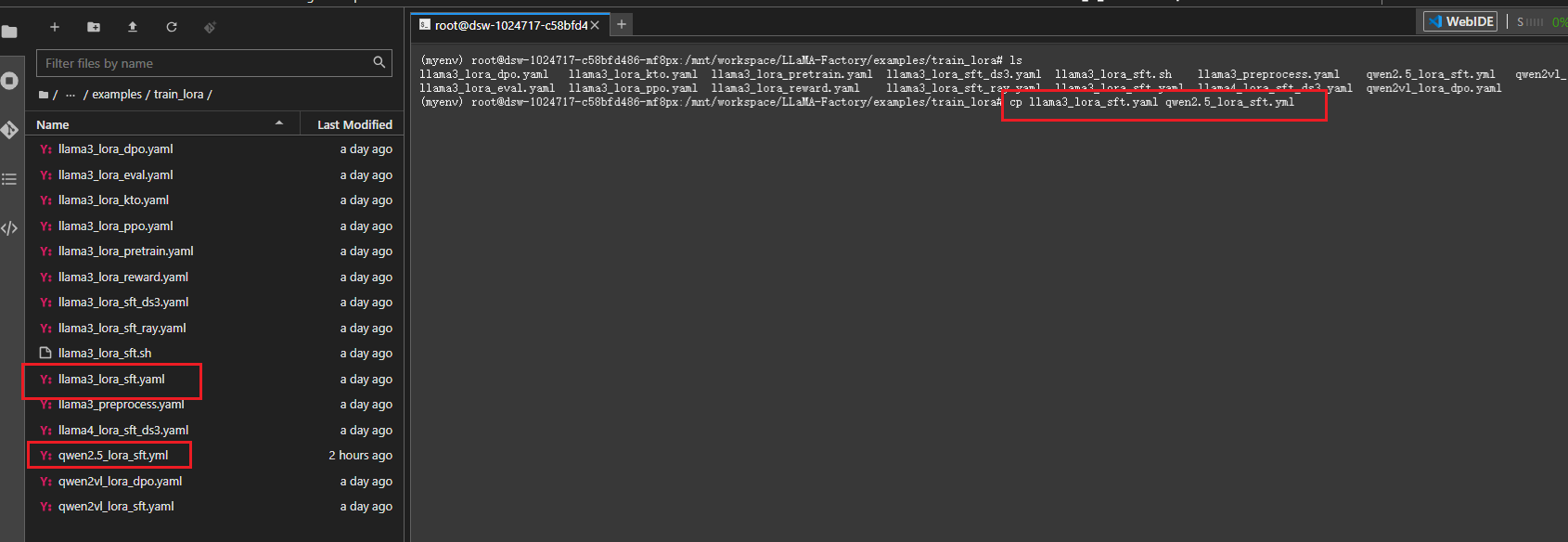
复制llama3_lora_sft.yaml文件创建一个新的配置文件qwen2.5_lora_sft.yml
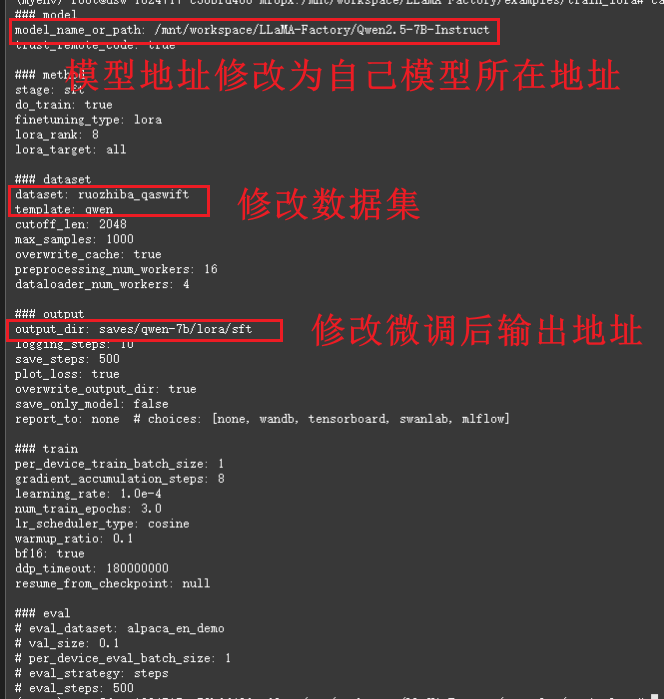
修改qwen2.5_lora_sft.yml文件:
这个文件就是微调配置文件。第一行model_name_or_path就是我们刚刚下载大模型的路径。
其他参数还有:
dataset: 表示的是数据集
template:这个是训练指令模板
output_dir:训练完成后,保存参数、配置、模型的路径
### train这个下面训练的超参数,一般都不需要该,唯一需要调整的可能是训练轮次num_train_epochs。一轮是指对整个数据集进行一次完整的遍历
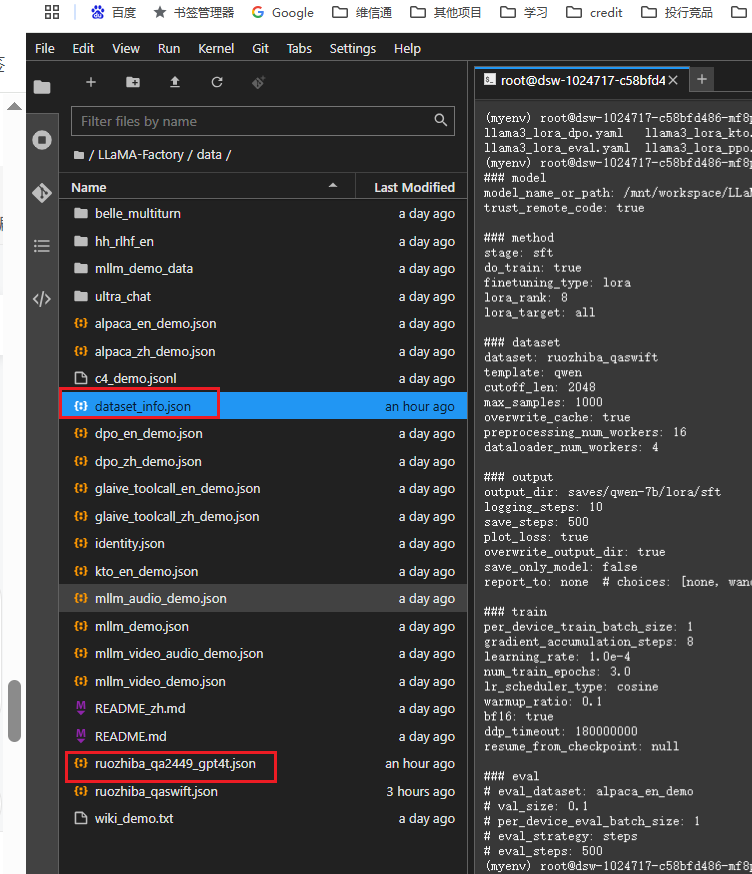
配置数据集dataset_info.json(当前文件存放的是LLama-factory框架使用的所有数据集):
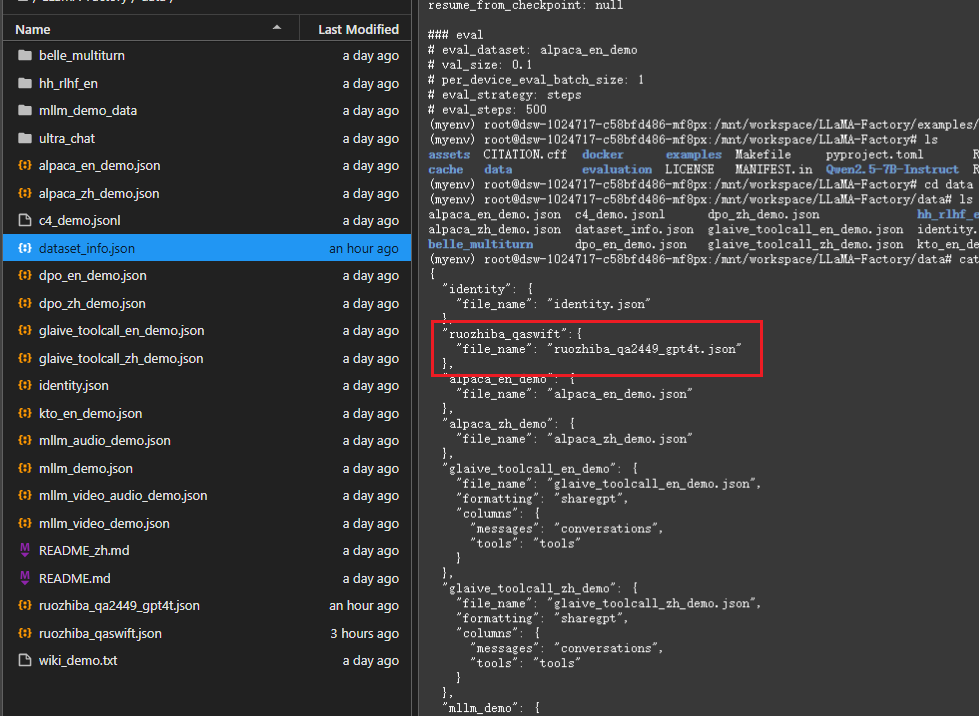
将数据集ruozhiba_qa2449_gpt4t.json上传到data目录下,然后配置dataset_info.json
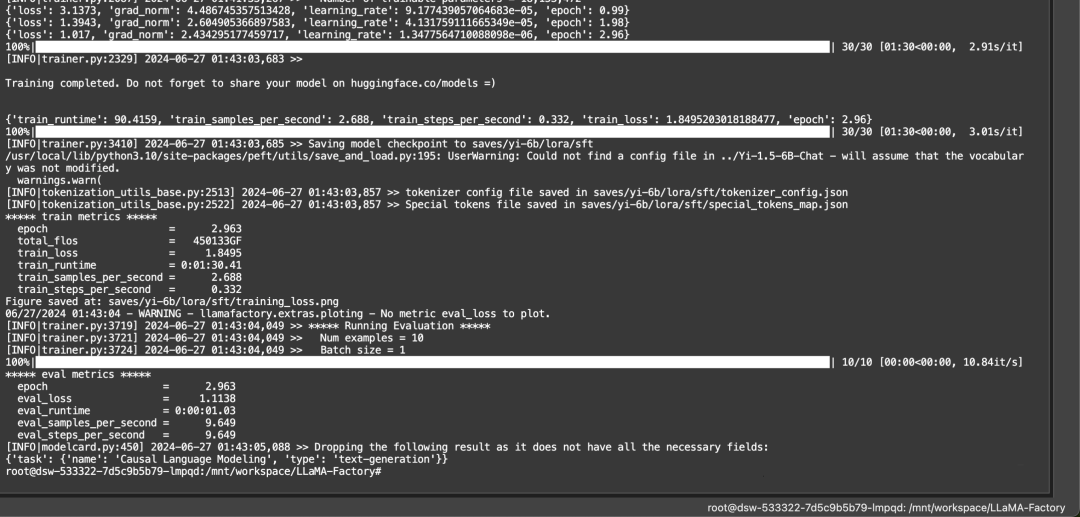
回到LLaMA-Factory目录下:启动微调
# 下面三行命令分别对 Llama3-8B-Instruct 模型进行 LoRA 微调、推理和合并
# llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
# llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
# llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
llamafactory-cli train examples/train_lora/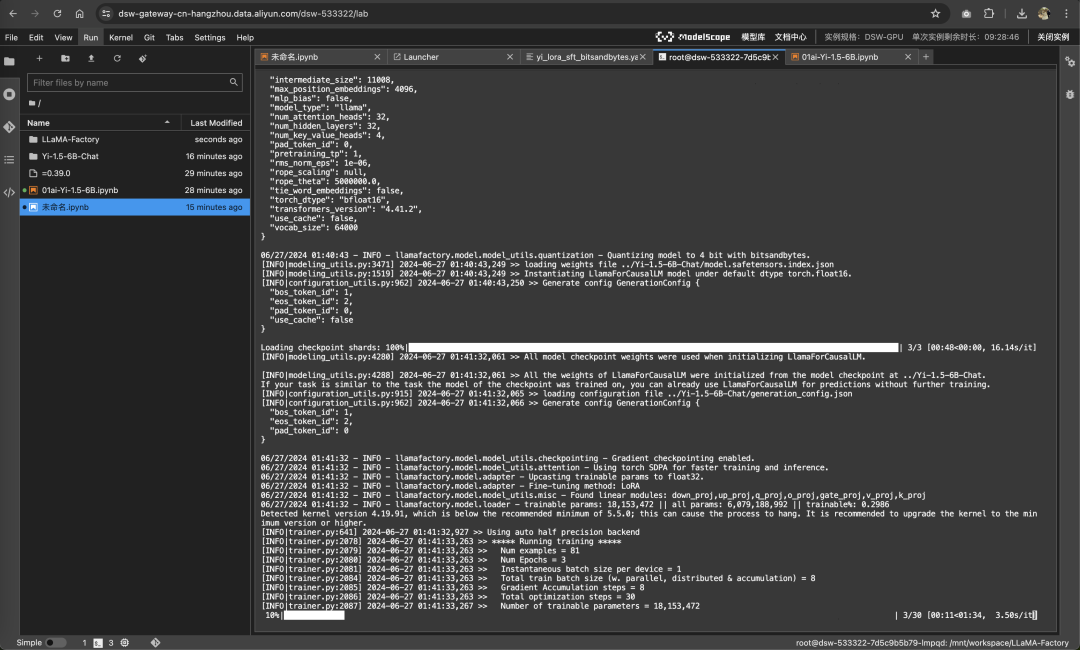
配置模型启动文件:(LLaMA-Factory/examples/inference/)
复制llama3.yaml生成qwen-loar.yaml文件
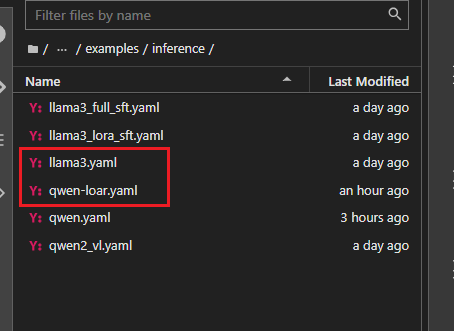
修改qwen-loar.yaml文件
#指定预训练模型的路径。这是加载基础模型的路径,比如:Qwen2.5-7B 的权重文件。
model_name_or_path: /mnt/workspace/LLaMA-Factory/Qwen2.5-7B-Instruct
#指定 LoRA(Low-Rank Adaptation)适配器的路径,这里是微调后的模型权重的路径
adapter_name_or_path: /mnt/workspace/LLaMA-Factory/saves/qwen-7b/lora/sft
#指定输入数据的模板格式
template: qwen
#指定推理后端
infer_backend: huggingface # choices: [huggingface, vllm]
trust_remote_code: true配置微调前大模型的启动文件
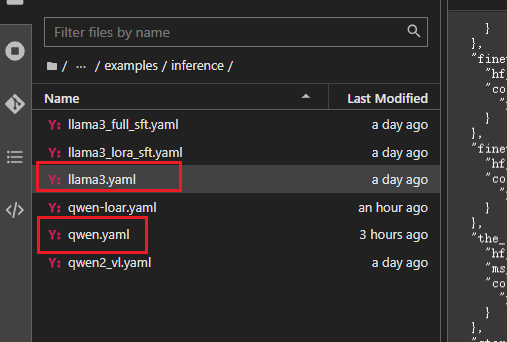
model_name_or_path: /mnt/workspace/LLaMA-Factory/Qwen2.5-7B-Instruct
# template改为chatml
template: chatml
infer_backend: huggingface # choices: [huggingface, vllm, sglang]
trust_remote_code: true启动大模型:
# 启动微调前:
llamafactory-cli chat examples/inference/qwen.yaml
# 启动微调后:
llamafactory-cli chat examples/inference/qwen-loar.yaml
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









