



 本文深入探讨了使用BeautifulSoup库解析HTML元素的方法,通过实例演示如何提取列表中特定元素的文本内容,包括直接获取文本、字符串内容及元素的全部内容。
本文深入探讨了使用BeautifulSoup库解析HTML元素的方法,通过实例演示如何提取列表中特定元素的文本内容,包括直接获取文本、字符串内容及元素的全部内容。
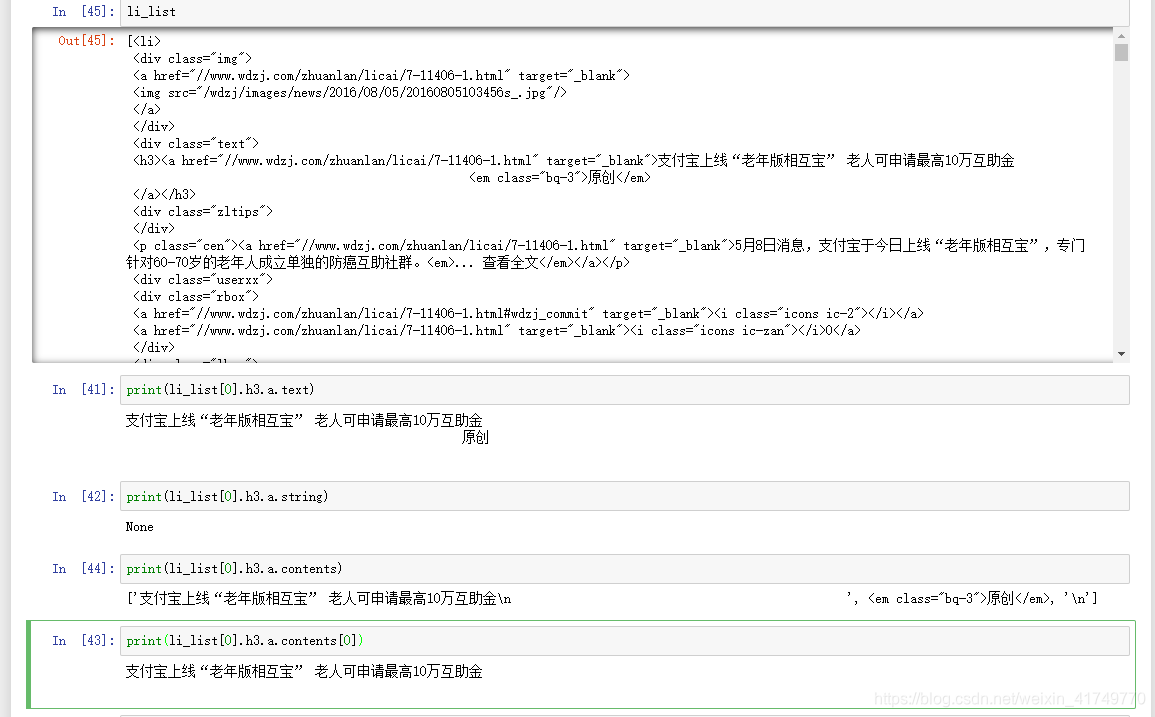 print(li_list[0].h3.a.text)
print(li_list[0].h3.a.text)
print(li_list[0].h3.a.string)
print(li_list[0].h3.a.contents)
print(li_list[0].h3.a.contents[0])
python 爬虫Tag方法
最新推荐文章于 2023-02-28 20:33:32 发布
print(li_list[0].h3.a.text)
print(li_list[0].h3.a.string)
print(li_list[0].h3.a.contents)
print(li_list[0].h3.a.contents[0])

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 3万+
3万+





