





 窄依赖在Spark中指每个父RDD分区最多被一个子RDD分区使用,涉及的算子如map、filter等。而宽依赖则是多个子RDD分区可能依赖同一父RDD分区,如groupByKey和未哈希分区的join操作。这种区分影响了Spark的任务调度和数据分区策略。
窄依赖在Spark中指每个父RDD分区最多被一个子RDD分区使用,涉及的算子如map、filter等。而宽依赖则是多个子RDD分区可能依赖同一父RDD分区,如groupByKey和未哈希分区的join操作。这种区分影响了Spark的任务调度和数据分区策略。
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用。
窄依赖的算子有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues。
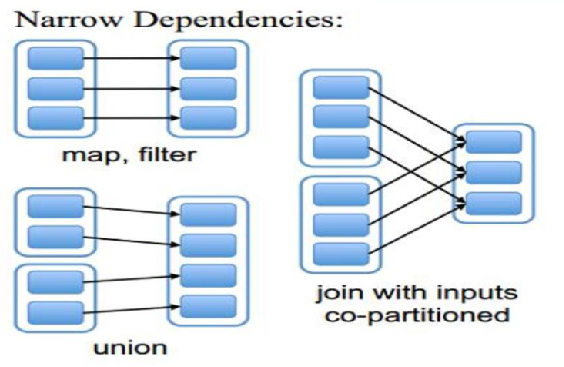
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition。
宽依赖的算子有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy。
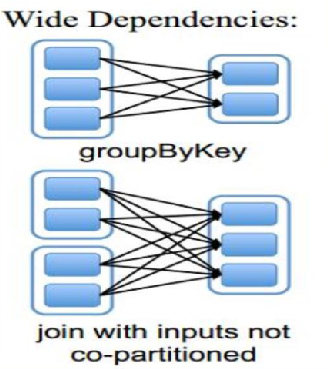

窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用。
窄依赖的算子有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues。
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition。
宽依赖的算子有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy。
 2975
2975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























