




本质是不同实验间的总体成功率差别很大,而趋向于成功的分组总会更大概率获得成功
例子1:


例子2:
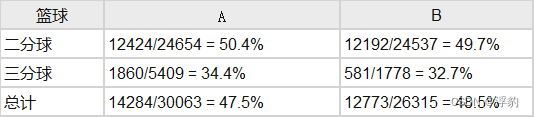

逆概率加权:
可以把两种不同的实验样本均为同样本表现
相当于权重归为100个人的表现

本质是不同实验间的总体成功率差别很大,而趋向于成功的分组总会更大概率获得成功
例子1:
例子2:
逆概率加权:
可以把两种不同的实验样本均为同样本表现
相当于权重归为100个人的表现
 3110
7522
3110
7522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























