







 本文介绍如何使用MNIST数据集训练一个简单的全连接神经网络,实现手写数字识别,达到约91%的测试精度,并演示了模型的保存与加载过程。
本文介绍如何使用MNIST数据集训练一个简单的全连接神经网络,实现手写数字识别,达到约91%的测试精度,并演示了模型的保存与加载过程。
mnist数据集首先下载好,在根目录下建立一个文件夹(MNIST_data),把下载好的mnist数据集保存在MNIST_data中,注意下载的mnist不用解压,程序会自动解压

下面代码包含:
一:网络结构只有全连接,比较简单
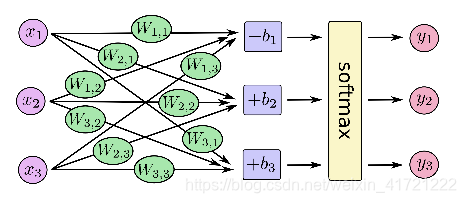
二:能得到测试集的精确度,大约为百分之91
三:能够保存模型
import tensorflow as tf
#加载数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#one_hot参数指将数据转成one_hot形式,如手写数字是0-9,若为0 ,则转为10维数据[1,0,0,0,0,0,0,0,0,0]。
#通过上两句代码,能够自动解压整理数据集
#例如把训练集的所有图像的像素点序列化,并与图像数量组成二维矩阵
#分为六类,分别是train(又分images和labels类),validation,test
print("训练集图像的尺寸:",mnist.train.images.shape) # (55000, 784)
print("训练集标签的尺寸:",mnist.train.labels.shape) # (55000, 10)
print("验证集图像的尺寸:",mnist.validation.images.shape) # (5000, 784)
print("验证集标签的尺寸:",mnist.validation.labels.shape) # (5000, 10)
print("测试集图像的尺寸:",mnist.test.images.shape) # (10000, 784)
print("测试集标签的尺寸:",mnist.test.labels.shape) # (10000, 10)
#设置参数
x = tf.placeholder("float", [None, 784])
# x 不是一个特定的值,而是一个占位符 placeholder ,我们在TensorFlow运行计算时输入这个值。
# 我们希望能够输入任意数量的MNIST图像,每一张图展平成784维的向量。我们用2维的浮点数张量来表示这些图,
# 这个张量的形状是 [None,784 ] 。(这里的 None 表示此张量的第一个维度可以是任何长度的。)
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
#我们的模型也需要权重值和偏置量,当然我们可以把它们当做是另外的输入(使用占位符),
#但TensorFlow有一个更好的方法来表示它们: Variable 。 一个 Variable 代表一个可修改的张量,
#存在在TensorFlow的用于描述交互性操作的图中。它们可以用于计算输入值,也可以在计算中被修改。
#W 的维度是[784,10],因为我们想要用784维的图片向量乘以它以得到一个10维的证据值向量,每一位对应不同数字类。
# b 的形状是[10],所以我们可以直接把它加到输出上面。
#softmax回归:softmax模型可以用来给不同的对象分配概率
y = tf.nn.softmax(tf.matmul(x,W) + b)
#交叉熵定义为损失函数
#为了计算交叉熵,我们首先需要添加一个新的占位符用于输入正确值:
#行数无限的,列数我们预先知道
y_ = tf.placeholder("float", [None,10])
#然后计算交叉熵:y是预测概率分布,y_是实际概率分布
# tf.reduce_sum 计算张量的所有元素的总和
cross_entropy = -tf.reduce_sum(y_*tf.log(y)) #reduce_sum损失值的和
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
#在这里,我们要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵
#因为TensorFlow拥有一张描述你各个计算单元的图,它可以自动地使用反向传播算法(backpropagation algorithm)来
#有效地确定你的变量是如何影响你想要最小化的那个成本值的
saver = tf.train.Saver()#保存或者读取模型
#现在我们可以在一个Session会议里面启动我们的模型:
with tf.Session() as sess:
#在运行计算之前,我们需要添加一个操作来初始化我们创建的变量
sess.run(tf.initialize_all_variables())
#然后开始训练模型,这里我们让模型循环训练1000次!
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
#随机取batch_xs为100个训练图片,batch_ys为100个对应的标签
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
#评估我们的模型
#首先让我们找出那些预测正确的标签.tf.argmax是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。
#由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,
#比如 tf.argmax(y,1) 返回的是模型对于任一输入x预测到的标签值,
#而 tf.argmax(y_,1) 代表正确的标签,
#我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
#这行代码会给我们一组布尔值。为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。
#例如, [True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75 .
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
#最后,我们计算所学习到的模型在测试数据集上面的正确率。
print ("准确率",sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
save_path = saver.save(sess,"save/model")

















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









