







写在前面
之前学过完整的C++,但是学了之后一直没去用它,忘的也差不多了。掌握C++也是我的计划之中的事,最近在看MIT mini-cheeath的源代码,用C++实现的,刚好趁这个时候捡捡C++的知识。以下我不打算很完整的做这个小结。单纯是为了做笔记(其实没笔记本了),C++的一个特点就是属性很多,所以要简化笔记。
小结
1.模板template
有函数模板、类模板、成员模板三种类型。成员模板比较少见。
类模板
类模板里面有:全特化,偏特化,泛化。偏特化有个数上的偏特化,还有范围上的偏特化。具体用到时,再加以补充吧。
template <typename T>
class complex
{
.....
}
{
complex<double>c1(2.5,1.5);
complex<int>c2(2,6); //模板类中要用<>,不然编译器找不到他,而函数模板则不需要(在调用的时候),编译器根据形参就可以定位到了
}
尖括号中用typename 或者class,都可以,用typename比较形象,而早期是比较常用class的。
函数模板:
template <class 形参名,class 形参名,......>
返回类型 函数名(参数列表)
{
函数体
}template <class T>
inline
const T& min(const T& a,const T& b)//用引用的方式比起使用value的方式更好,不需要赋值什么的
{
return b<a?b:a; //不需要把实参的值复制到函数中,引用的效率比较高
}//使用这个模板类的时候,会看看T这个类中有没有操作符重载,因为函数中有操作符,所以会先检查的知识点:<>内是模板形参,class 是关键字。<>内不可为空(特化时,template <>是为空的,针对某一类数据而言),一但声明了模板函数就可以用模板函数的形参名声明类中的成员变量和成员函数,作用就是用这个模板可以对适应各种数据类型,不用重复声明函数。例子如下:
template <class T> void swap(T& a, T& b){},a、b可以是double,也可以是int…这样就实现了函数的实现与类型无关的代码。
类模板:
template<class 形参名,class 形参名,…>
class 类名{ ... };同样<>里面是模板形参,不能空。可以在类中使用内置类型的地方都可以使用模板形参名来声明。例子:
template<class T> class A
{
public:
T a;
T b;
T hy(T c, T &d);
};在类A中声明了两个类型为T的成员变量a和b,还声明了一个返回类型为T带两个参数类型为T的函数hy。
类模板对象的创建:比如一个模板类A,则使用类模板创建对象的方法为A m;在类A后面跟上一个<>尖括号并在里面填上相应的类型,这样的话类A中凡是用到模板形参的地方都会被int 所代替。当类模板有两个模板形参时创建对象的方法为A<int, double> m;类型之间用逗号隔开。
对于类模板,模板形参的类型必须在类名后的尖括号中明确指定。
提醒注意:模板的声明或定义只能在全局,命名空间或类范围内进行。即不能在局部范围,函数内进行,比如不能在main函数中声明或定义一个模板。
模板的继承:
模板类的继承包括四种:
1.(普通类继承模板类)
1 template<class T>
2 class TBase{
3 T data;
4 ……
5 };
6 class Derived:public TBase<int>{
7 ……
8 };2.(模板类继承了普通类(非常常见))
1 class TBase{
2 ……
3 };
4 template<class T>
5 class TDerived:public TBase{
6 T data;
7 ……
8 };3.(类模板继承类模板)
1 template<class T>
2 class TBase{
3 T data1;
4 ……
5 };
6 template<class T1,class T2>
7 class TDerived:public TBase<T1>{
8 T2 data2;
9 ……
10 };
4.承类模板,即继承模板参数给出的基类)
——继承哪个基类由模板参数决定
2.auto关键字
它的作用就是,当有一些数据类型很冗长时,用auto声明自动变量,它会根据你后面赋值是数据什么数据类型,而给你声明的变量定义数据类型。
template <typename _Tx,typename _Ty>
void Multiply(_Tx x, _Ty y)
{
auto v = x*y;
std::cout << v;
}若不使用auto变量来声明v,那这个函数就难定义啦,不到编译的时候,谁知道x*y的真正类型是什么呢?刚好和上面模板知识点呼应上。没被真正使用时,x、y的数据类型时不确定的。
注意点:
auto 变量必须在定义时初始化,这类似于const关键字。
定义在一个auto序列的变量必须始终推导成同一类型。例如:
auto a4 = 10, a5 = 20, a6 = 30;//正确
auto b4 = 10, b5 = 20.0, b6 = 'a';//错误,没有推导为同一类型
如果初始化表达式是引用,则去除引用语义。
如果初始化表达式为const或volatile(或者两者兼有),则除去const/volatile语义。
如果auto关键字带上&号,则不去除const语意。
初始化表达式为数组时,auto关键字推导类型为指针。
若表达式为数组且auto带上&,则推导类型为数组类型。
函数或者模板参数不能被声明为auto。
时刻要注意auto并不是一个真正的类型。auto仅仅是一个占位符,它并不是一个真正的类型,不能使用一些以类型为操作数的操作符,如sizeof或者typeid。
与auto 功能相近的有dectltype ,两者的不同之处在于,auto是根据等式右边的的运算结果推断类型,而dectltype是根据等式右边表达式的类型推断
3.指针
数据类型的定义在内存中,是地址,加数据,比如说,int a = 20; 这段代码而言,我们知道a是我们定义的变量名,经过编译器,其实它对应内存上的某个地址,而这个地址对应的内容就是20。a这个变量名其实是为了让编程人员更容易记住。其实每个变量名都对应了一个地址。所以指针就引入了。
两个重要符号
| & | 取地址符号 |
|---|---|
| * | 有两个作用,一个是取数据,一个是定义指针变量(就是存放地址的变量)。 |
例子:
char a,*pa; //这里定义了两个变量,一个是字符串类型,一个是指针变量
a = 10; //给a 赋值
pa = &a; //pa是指针变量,用于存放地址的,这里的&a就是把a的地址取出来,赋值给pa
*pa = 20; //*pa就是取内容取数据,pa其实就是存放a 的地址,所以这里就是将a的数据重新赋值为20.上面的注释就解释得很清楚了,相信可以很好的理解指针了。。
二级指针:是一种指向指针的指针。我们可以通过它实现间接访问数据,和改变一级指针的指向问题。
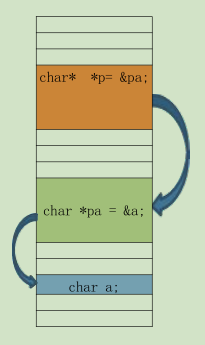
这里**p就是二级指针,最终 **p等于a 的值。
解释:**p=&pa ,pa =&a 所以pa就是放a的地址, **p可以看成 *(*p),所以这个时候 **p就是一个存放数据的变量了,&pa就是一个地址 值与指针变量p是一样的,二级指针就是取值了。结合上面的图理解。(有点乱,错了的话,请指点~)
可以通过一级指针,修改 0 级指针(变量)的内容。
- 可以通过二级指针,
- 修改一级指针的指向。
- 可以通过三级指针,修改二级指针的指向。
- ·····
- 可以通过 n 级指针,修改 n-1
所有类型的二级指针,由于均指向一级指针类型,一级指针类型大小是 4,所以二级指针的步长也是 4,这个信息很重要。
指针访问数组: 四种情况了解一下
//一
int i, a[] = {3,4,5,6,7,3,7,4,4,6};
for (i = 0; i <= 9; i++)
{
std::cout << a[i] std::endl;
}
//二
int i, a[] = {3,4,5,6,7,3,7,4,4,6};
for (i = 0; i <= 9; i++)
{
std::cout << *(a+i) << std<<endl;; // 要知道,a[],的第一个地址是a,后面的地址就在加上对应数据类型所占字节大小
}
//三
int i, *pa, a[] = {3,4,5,6,7,3,7,4,4,6};
pa = a; /*请注意数组名 a 直接赋值给指针 pa*/
for (i = 0; i <= 9; i++)
{
std::cout << pa[i] << std::endl;
}
//四
int i, *pa, a[] = {3,4,5,6,7,3,7,4,4,6};
pa = a;
for (i = 0; i <= 9; i++)
{
std::cout << *(pa+i) << std::endl;
}
//五
int i, *pa, a[] = {3,4,5,6,7,3,7,4,4,6};
pa = a;
for (i = 0; i <= 9; i++)
{
printf("%d\n", *pa);
pa++; /*注意这里,指针值被修改*/ //其实上面的指针是指针变量,而 数组名只是一个指针常量。不能用a++,a是数组名
}指针数组,一个全是指针变量:char * pArray[10]
这个数组里面全都是指针变量,全部都是存放地址的变量。
//
2020.6.28更新
指针函数和函数指针
函数指针:先是一个指针,然后指向一个函数
指针函数:先是一个函数,然后这个函数返回一个指针类型
int *func(int a ,int b)*的优先级低于(),所以先是一个函数,之后返回一个指针,所以他是一个函数指针。
int (*func)(int a ,int b)因为加了括号,所以这个时候的优先级发生了改变,它先是一个指针,指向了一个函数。
关于那个先,就看优先级,由此确定。
用typedef声明一个函数指针
typedef int (*PF)(int a,int b)
PF pfunc命名很多个函数指针的时候,用typedef
//2020.7.2更新/
操作符重载 operator overloading
有几个符号不能重载,分别是:
| :: | . |
|---|---|
| .* | ?* |
| ** | <> |
形式:
| operator*(){} | operator->(){} |
|---|---|
| operator++(){} | operator++(int){} |
前面有个关键字operator.{}中则是操作符新的功能。
2020.7.21更新
for(auto a:b)用法
for(auto a:b)中b为一个容器,效果是利用a遍历并获得b容器中的每一个值,但是a无法影响到b容器中的元素。
for(auto &a:b)中加了引用符号,可以对容器中的内容进行赋值,即可通过对a赋值来做到容器b的内容填充。
/2020.8.11更新
成员函数后面接override
void init() override;//override表示当前函数重写基类的虚函数
void run() override;
void cleanup() override;//override是一个关键字一般是有继承,并且在父类是纯虚函数,在子类中声明时加上这个关键字,表示这个成员函数是重写的。而且这个函数名如果不对(拼错的)的话,是会报错的。
override这个关键字也不能随便用,必须搭配虚函数、继承、重写成员函数是,才能使用。
虚函数和纯虚函数
虚函数:你希望子类重新定义父类的函数,而且这个函数,有了默认的定义了。
virtaul fun(); //纯虚函数:你希望子类一定要定义父类的某个成员函数,一定要重新定义它,为什么要重新定义它呢,因为这个函数在父类中没有默认的定义。
virtual fun()=0;//后面有=0,来表示它是一个纯虚函数父类出现虚函数,要在子类特别关注,虚函数,可能会重写,纯虚函数的话,在子类当中一定是会从写的。
类中多了vritual,表明这个类的内存中多了一个指针,虚指针,它的作用是指向一个虚函数表,这里说一下C++程序的内存分布
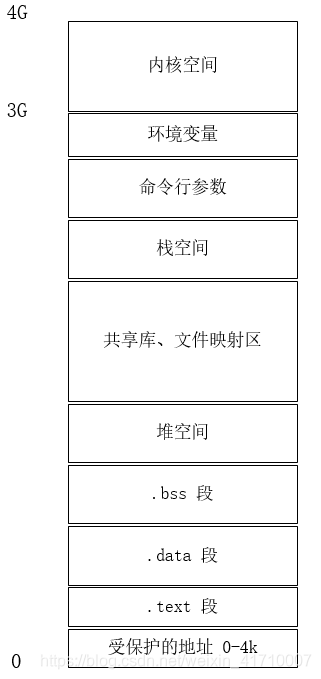
如上,这个虚指针存放在.data段中,而虚函数表,虚函数的具体实现都是在代码段中。通过虚指针可以找到虚函数表,在虚函数表就可以找到相应的虚函数,data段中可以分为全局区、常量区,像初始化了的全局变量、常量、static变量都是存放于此。.bss段中是存放未初始化的全局变量、static变量。

















 1636
1636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









