








用心做好文章,用心做好教育
一篇好文章,能带给人启迪!
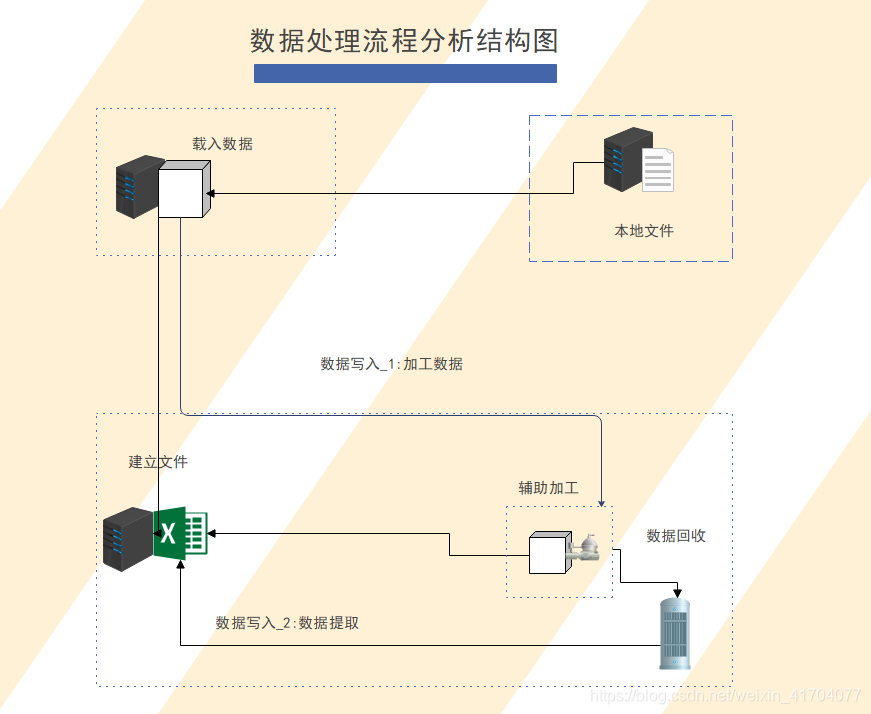
代码结构示意图:
文件部分
本地TXT文件:

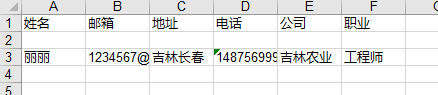
保存EXCEL文件:
代码分析结构图
源代码:
#定义一个读取数据的函数,参数为file_name----结构图:载入数据
def read_data(file_name):
#定义读取文件的函数
def read_file():
#调取外部文件名称,映射到内存中,命名为f
with open(file_name,encoding='utf-8') as f:
#循环条件为True,执行读取数据,并临时存入line变量,
while True:
line = f.readline()
#生成了一个存储字典信息的生成器,内容存入了line内
yield line
#返回函数调用
return read_file()
#函数get_world是一个功能函数,
#----结构图:辅助加工
#嵌套在write_excel函数内while循环语句内,是一个辅助函数。
def get_world(d):
#对参数d取索引去掉头和尾
s = d[1:-2]
#把空格去掉,同时用逗号分隔
s = s.replace(' ','').split(',')
#定义一个空的列表,定义为result
result = []
#对列表s进行遍历
for i in s:
try:
#把s中遍历变量i,提取value值后,把\用replace方式删除,并把结果添加到result中,同时对按分号分隔,并把斜线用删除。
result.append(i.split(':')[1].replace('\'',''))
except:
#如果有问题,输出i
print(i.split(':'))
#最后函数保留result,----结构图:数据回收
return result
#定义函数write_excel,参数传入read_gen,excel_name
#函数内首先导入xlwt模块
#建立映射文件名称workbook,表名称worksheet,定义表的硬盘名称sheet1
def write_excel(read_gen,excel_name):
import xlwt
workbook=xlwt.Workbook(encoding='gbk2312')
worksheet=workbook.add_sheet('sheet1')
#定义一个表头列表,同时对表头进行遍历,把序号和内容存入d和t中
sheet_title = ['姓名','邮箱','地址','电话','公司','职业']
for d,t in enumerate(sheet_title):
#表单中0行,横向在列的方式写入内容t
worksheet.write(0,d,t)
#设置循环变量i,初值为1,当获取字典的信息为空时,退出循环。
i = 1
#当条件为真时,next指针跳转到下一条记录信息
while True:
#参数d是生成器中调用到的文件内的每一行信息
d = next(read_gen)
if d == '':
break
#生成器中存储的文件信息d,通过功能函数get_world加工后保存到l中,
l = get_world(d)
#数据提取----结构图:数据写入2:数据提取
for j,t in enumerate(l):
worksheet.write(i,j,t)
i += 1
#写入文档----结构图:写入文档excel中
workbook.save(excel_name)
if __name__=='__main__':
#read_gen是函数read_data的实例调用,保存了文件"data,txt"生成器数据
read_gen = read_data(file_name = 'data.txt')
write_excel(read_gen,'data.xls')
补充知识:
生成器设计生成豆油案例:
def ksf():
for i in range(1,10):
yield '正在生产第{}桶豆油'.format(i)
g = ksf()
import time
while True:
try:
print(next(g))
time.sleep(1)
except StopIteration:
print("豆油生产结束了!")
break
带你进入一个更加奇妙的编程世界,德天老师和你一起精通学习Python编程!创作不易,敬请评论点赞谢谢!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









