







 这篇博客是机器学习实战系列的第二篇,重点介绍了决策树。文章讲解了matplotlib的annotate()、figure()、clf()和subplot()等模块的用法,以及pickle的dump()和load()函数。此外,还探讨了math模块中的log()函数,以及一些常用的Python列表和字典操作,如extend()、append()、iter()、dict.keys()、index()和count()。在学习过程中,作者遇到了'list index out of range'的问题并分享了解决方案。
这篇博客是机器学习实战系列的第二篇,重点介绍了决策树。文章讲解了matplotlib的annotate()、figure()、clf()和subplot()等模块的用法,以及pickle的dump()和load()函数。此外,还探讨了math模块中的log()函数,以及一些常用的Python列表和字典操作,如extend()、append()、iter()、dict.keys()、index()和count()。在学习过程中,作者遇到了'list index out of range'的问题并分享了解决方案。
目录
绪言
我最近开始入门机器学习,使用的书是《机器学习实战》(Peter Harrington 著),为了巩固学习成果,决定写一系列日志,内容是总结性的,会做一些思维导图,写一些我学习时不懂的模块,函数语法等,但不涉及具体算法的实现(不具备教程性质)。
本文是系列日志的第二篇 – 决策树。
Xmind
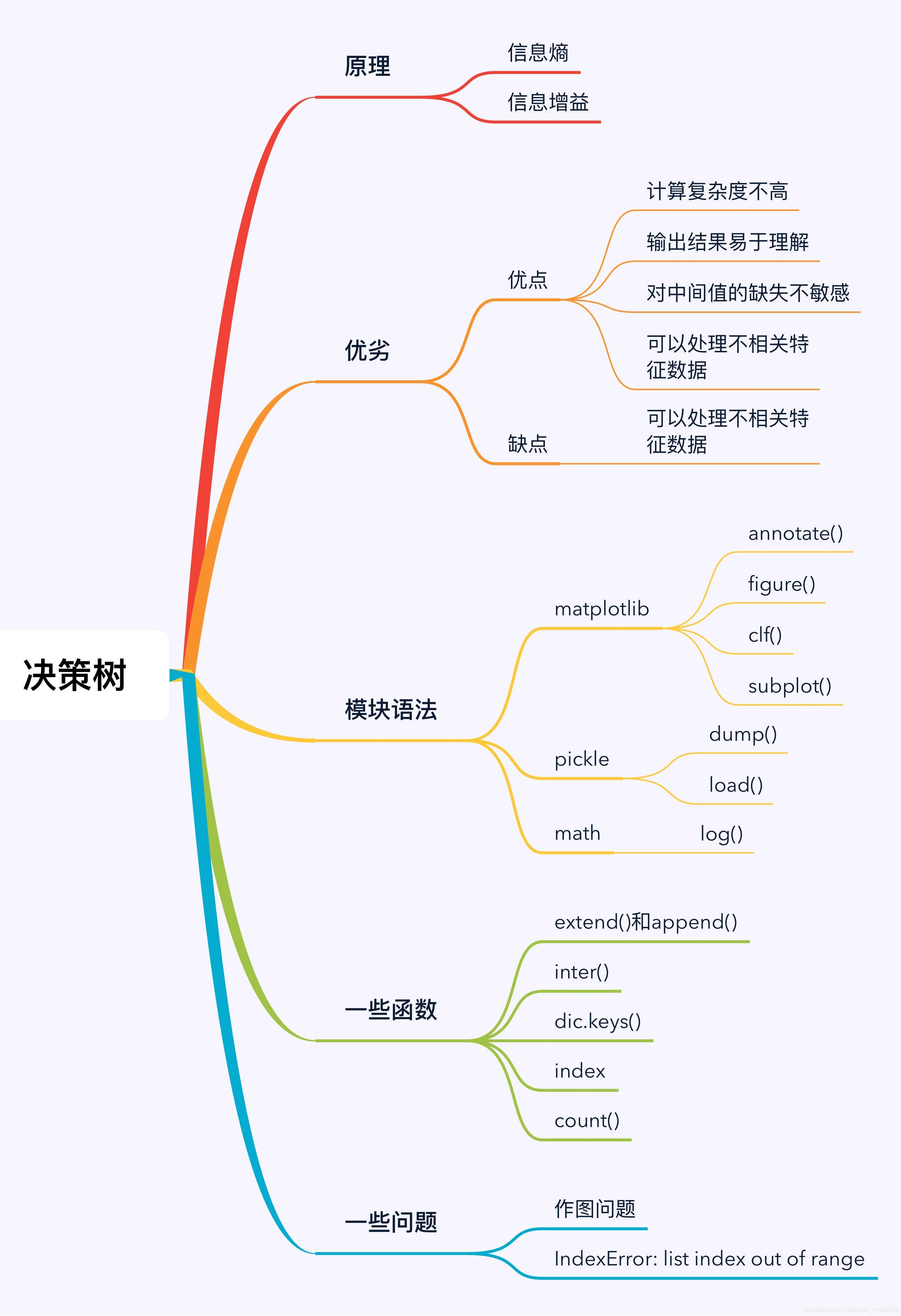
模块语法
motplotlib
annotate()
annotate用于在图形上给数据添加文本注解,而且支持带箭头的划线工具,方便我们在合适的位置添加描述信息。调用方法:
axes.annotate(s, xy, *args, **kwargs)
s:注释文本的内容
xy:被注释的坐标点,二维元组形如(x,y)
xytext:注释文本的坐标点,也是二维元组,默认与xy相同
xycoords:被注释点的坐标系属性,允许输入的值如下:
| 属性值,含义 | |
|---|---|
| ‘figure points’ | 以绘图区左下角为参考,单位是点数 |
| figure pixels | pixels from the lower left of the figure 图左下角的像素 |
| figure fraction | fraction of figure from lower left 左下角数字部分 |
| axes points | points from lower left corner of axes 从左下角点的坐标 |
| axes pixels | pixels from lower left corner of axes 从左下角的像素坐标 |
| axes fraction | fraction of axes from lower left 左下角部分 |
| data | use the coordinate system of the object being annotated(default) 使用的坐标系统被注释的对象(默认) |
| polar(theta,r) | if not native ‘data’ coordinates t |
textcoords :注释文本的坐标系属性,默认与xycoords属性值相同,也可设为不同的值。除了允许输入xycoords的属性值,还允许输入以下两种:
| 属性值 | 含义 |
|---|---|
| ‘offset points’ | 相对于被注释点xy的偏移量(单位是点) |
| ‘offset pixels’ | 相对于被注释点xy的偏移量(单位是像素) |
arrowprops:箭头的样式,dict(字典)型数据,如果该属性非空,则会在注释文本和被注释点之间画一个箭头。如果不设置’arrowstyle’ 关键字,则允许包含以下关键字:
| 关键字 | 说明 |
|---|---|
| width | 箭头的宽度(单位是点) |
| headwidth | 箭头头部的宽度(点) |
| headlength | 箭头头部的长度(点) |
| shrink | 箭头两端收缩的百分比(占总长) |
| ? | 任何 matplotlib.patches.FancyArrowPatch中的关键字 |
如果设置了‘arrowstyle’关键字,以上关键字就不能使用。允许的值有:
| 箭头的样式 | 属性 |
|---|---|
| ‘-’ | None |
| ‘->’ | head_length=0.4,head_width=0.2 |
| ‘-[’ | widthB=1.0,lengthB=0.2,angleB=None |
| ‘|-|’ | widthA=1.0,widthB=1.0 |
| ‘-|>’ | head_length=0.4,head_width=0.2 |
| ‘<-’ | head_length=0.4,head_width=0.2 |
| ‘<->’ | head_length=0.4,head_width=0.2 |
| ‘<|-’ | head_length=0.4,head_width=0.2 |
| ‘<|-|>’ | head_length=0.4,head_width=0.2 |
| ‘fancy’ | head_length=0.4,head_width=0.4,tail_width=0.4 |
| ‘simple’ | head_length=0.5,head_width=0.5,tail_width=0.2 |
| ‘wedge’ | tail_width=0.3,shrink_factor=0.5 |
FancyArrowPatch的关键字包括:
| 值 | 属性 |
|---|---|
| arrowstyle | 箭头的样式 |
| connectionstyle | 连接线的样式 |
| relpos | 箭头起始点相对注释文本的位置,默认为 (0.5, 0.5),即文本的中心,(0,0)表示左下角,(1,1)表示右上角 |
| patchA | 箭头起点处的图形(matplotlib.patches对象),默认是注释文字框 |
| patchB | 箭头终点处的图形(matplotlib.patches对象),默认为空 |
| shrinkA | 箭头起点的缩进点数,默认为2 |
| shrinkB | 箭头终点的缩进点数,默认为2 |
| mutation_scale | default is text size (in points) |
| mutation_aspect | default is 1. |
| ? | any key for matplotlib.patches.PathPatch |
annotation_clip : 布尔值,可选参数,默认为空。设为True时,只有被注释点在子图区内时才绘制注释;设为False时,无论被注释点在哪里都绘制注释。仅当xycoords为‘data’时,默认值空相当于True。
bbox给标题增加外框 ,常用参数如下:
| 值 | 属性 |
|---|---|
| boxstyle | 方框外形 |
| facecolor(简写fc) | 背景颜色 |
| edgecolor(简写ec) | 边框线条颜色 |
| edgewidth | 边框线条大小 |
figure()
figure()创建一个画布。调用语法如下:
matplotlib.pyplot.figure(num=None, figsize=None, dpi=None,\
facecolor=None, edgecolor=None,frameon=True, \
FigureClass=<class 'matplotlib.figure.Figure'>, clear=False, **kwargs)
参数num:给画布定义一个id,如果这个num之前没有使用,则创建一个新的画布;如果之前使用了这个num,那么返回那个画布的引用,在之前的画布上继续作图。如果没有给出num, 则每次创建一块新的画布。
clf()
figure.clf()清除所有轴,但是窗口打开,这样它可以被重复使用。
subplot()
subplot()为当前图像添加一个子图。调用格式:
subplot(nrows, ncols, index, **kwargs)
subplot(pos, **kwargs)
subplot(ax)
nrows、ncols、index:指定添加的子图位置,表示在包含nrows行ncols的网格中占据第index个位置。index是从最左上角开始向右从1计数的。
pos:作用与nrows、ncols、index相同。pos是一个三位的整数,三位分别代表了行数nrows、列数ncols以及索引index。但要注意的是使用pos时,三个数字必须都是小于10的。subplot(2,3,1)与subplot(231)是等效的。
projection:可选的,子图的投影类型。可选值有:aitoff、hammer、lambert、mollweide、polar、rectilinear。默认值为None,使用的是rectilinear。此外可以在注册自定义的projection后,传入自定义的projection名称。
polar:可选的,布尔值。如果为True,等价于projection为polar。
sharex、sharey:可选的,Axes。和sharex、sharey共享x、y轴。具有与共享的轴相同的范围、刻度和比例。
label:坐标轴的标签。
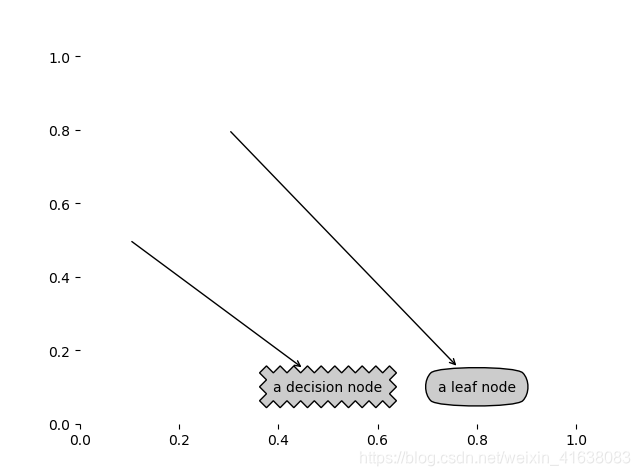
用上面几个函数举个栗子:
import matplotlib.pyplot as plt
# 使用文本注解绘制树节点
# 包含了边框的类型,边框线的粗细等
decisionNode = dict(boxstyle="sawtooth", fc="0.8",
pad=1) # boxstyle为文本框的类型,sawtooth是锯齿形,fc是边框线粗细 ,pad指的是外边框锯齿形(圆形等)的大小
leafNode = dict(boxstyle="round4", fc="0.8", pad=1) # 定义决策树的叶子结点的描述属性 round4表示圆形
arrow_args = dict(arrowstyle="<-") # 定义箭头属性
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
# annotate是关于一个数据点的文本
# nodeTxt为要显示的文本,centerPt为文本的中心点,箭头所在的点,parentPt为指向文本的点
# annotate的作用是添加注释,nodetxt是注释的内容,
# nodetype指的是输入的节点(边框)的形状
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', \
xytext=centerPt, textcoords='axes fraction', \
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def createPlot():
fig = plt.figure(1, facecolor='white')
fig.clf()
createPlot.ax1 = plt.subplot(111, frameon=False)
plotNode('a decision node', (0.5, 0.1), (0.1, 0.5), decisionNode)
plotNode('a leaf node', (0.8, 0.1), (0.3, 0.8), leafNode)
plt.show()
createPlot()
结果:
pickle
pickle 是一个 压缩,保存,提取文件的模块。
dump()
dump()用于储存文件。调用语法为:
pickle.dump(obj, file, [,protocol])
序列化对象,将对象obj保存到文件file中去。
file表示保存到的类文件对象,file必须有write()接口,file可以是一个以’w’打开的文件或者是一个StringIO对象,也可以是任何可以实现write()接口的对象。
参数protocol是序列化模式,默认是0(ASCII协议,表示以文本的形式进行序列化),protocol的值还可以是1和2(1和2表示以二进制的形式进行序列化。其中,1是老式的二进制协议;2是新二进制协议)。
例如:
import pickle
a = 'I am shuangpinai'
file = open('shuangpinai.txt', 'wb')
pickle.dump(a, file)
file.close()
将I am shuangpinai.存入文件shuangpinai.txt。
load()
load()反序列化对象,将文件中的数据解析为一个python对象。
举个栗子:
import pickle
file = open('shuangpinai.txt', 'rb')
a = pickle.load(file)
file.close()
print(a)
结果:
I am shuangpinai
math
math模块实现了许多对浮点数的数学运算函数. 这些函数一般是对平台 C 库中同名函数的简单封装, 所以一般情况下, 不同平台下计算的结果可能稍微地有所不同, 有时候甚至有很大出入 。
log()
log()函数可以用来求对数,调用方法如下:
import math
math.log(m, n)
其中n为底数,m为真数。
举个栗子:
import math
a = math.log(8, 2)
print(a)
结果:
3
一些函数
extend()与append()
这两个方法功能类似,但是在处理多个列表时,这两个方法的处理结果是完全不同的。append() 方法向列表的尾部添加一个新的元素。extend()方法只接受一个列表作为参数,并将该参数的每个元素都添加到原有的列表中。
例如:
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
print(a)
结果:
[1, 2, 3, [4, 5, 6]]
若用extend:
a = [1, 2, 3]
b = [4, 5, 6]
a.extend(b)
print(a)
结果:
[1, 2, 3, 4, 5, 6]
iter()
iter()函数可以让一个dict成为迭代器。用next()可以依次得到key。
例如:
dict_1 = {'A': 1, 'B': 2, 'C': 3}
g = iter(dict_1)
print(next(g))
print(next(g))
print(next(g))
结果:
A
B
C
dict.keys()
dict.keys()生成一个dict_keys类型的数据。
例如:
dict_1 = {'A': 1, 'B': 2, 'C': 3}
a = dict_1.keys()
print(a)
结果:
dict_keys(['A', 'B', 'C'])
dict_keys可用于循环,例如:
dict_1 = {'A': 1, 'B': 2, 'C': 3}
a = dict_1.keys()
for val in a:
print(val)
结果:
A
B
C
也可用list()函数把dict_keys变成一个list,例如:
dict_1 = {'A': 1, 'B': 2, 'C': 3}
a = dict_1.keys()
b = list(a)
print(b)
结果:
['A', 'B', 'C']
index
index() 方法检测字符串中是否包含子字符串 str 。调用方法如下:
str.index(str, beg=0, end=len(string))
str – 指定检索的字符串
beg – 开始索引,默认为0。
end – 结束索引,默认为字符串的长度。
如果包含子字符串返回索引值,否则抛出异常。
例如:
str1 = 'I am shuangpinai!'
str2 = 'shuang'
print(str1.index(str2))
结果:
5
index()也可以用在list上。例如:
list = [1, 2, 3, 4]
print(list.index(4))
结果:
3
count()
count() 方法用于统计某个元素在列表中出现的次数。
举个栗子:
list1 = [1, 5, 6, 1, 5, 5, 4, 7, 1]
print(list1.count(list1[0]))
结果:
3
一些问题
IndexError: list index out of range
第三节“使用决策树预测隐形眼镜类型”在调用之前创建好的决策树生成函数时,会出现下面的错误:
IndexError: list index out of range
解决方法在这里解决方法
作图问题
作图时最难理解的点是plotTree()中x坐标的改变,有一篇文章我觉得写得比较好理解,放个链接在这里点这里

















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









