







【Python】分析图标可视化visualization - 详解 1期
一、引言
- 在大数据时代,优秀的数据可视化图表分析能帮助开发者、业务决策者快速洞察数据规律,了解业务全貌
- 📈本文详细介绍可视化图表的常见案例和分析操作
- 由于图表案例较多,会分两期来写
- 2期地址点这里
二、环境和包准备
# 环境:Jupyter 3.6+
%matplotlib inline # 启用Jupyter内嵌绘图模式
import numpy as np
import pandas as pd
import matplotlib as mpl # 绘图系统底层配置,如字体、样式等
import matplotlib.pyplot as plt # 基础绘图库,支持折线图/柱状图等可视化
import seaborn as sns # 基于matplotlib的高级统计可视化库
import datetime as dt
import statsmodels.api as sm # 统计建模库,如线性模型/时间序列等
import statsmodels.formula.api as smf # 公式化建模接口
from patsy import dmatrices # 模型公式解析器
import scipy # 科学计算库,优化/积分/信号处理等
import scipy.stats as stats # 统计分布与假设检验工具
import rpy2 # Python与R语言交互接口
import rpy2.robjects as robjects # R对象转换与执行环境
三、图表和代码可视化visualization
3.1 LAYOUT 矩阵图
3.1.1 示例-1
# matplotlib的图像都位于Figure对象
fig = plt.figure(num = 1,figsize=[8,4.5]) # num means figure_id
# subplot用于绘图
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
3.1.2 示例-2
# 另一种声明var的方式
fig, axes = plt.subplots(2,3,sharex= True,sharey=True)
plt.subplots_adjust(wspace = 0, hspace = 0)# will lead to overlapping of aix label
axes[0,0].set_xticks([0,0.2,0.4,0.6,0.8,1])
axes[1,0].set_xlabel('Stages')
3.1.3 示例-3
from matplotlib.ticker import NullFormatter
# 固定随机状态
np.random.seed(19680801)
# # 随机定义数据
# x = np.random.randn(1000)
# y = np.random.randn(1000)
nullfmt = NullFormatter() # no labels
# 定义X,Y轴
left, width = 0.1, 0.65
bottom, height = 0.1, 0.65
bottom_h = left_h = left + width + 0.02
rect_scatter = [left, bottom, width, height]
rect_histx = [left, bottom_h, width, 0.2]
rect_histy = [left_h, bottom, 0.2, height]
# 矩形图
plt.figure(1, figsize=(8, 8))
axScatter = plt.axes(rect_scatter)
axHistx = plt.axes(rect_histx)
axHisty = plt.axes(rect_histy)
# no labels
axHistx.xaxis.set_major_formatter(nullfmt)
axHisty.yaxis.set_major_formatter(nullfmt)
plt.show()
3.1.4 示例-4 色彩处理
# 使用Seaborn获得多种颜色分布
current_palette = sns.color_palette('hls',8)
sns.palplot(current_palette)
palette_2 = sns.color_palette('magma',8)
sns.palplot(palette_2)
palette_2[3]

3.2 LINES 线形图
3.2.1 示例-1
mpl.style.use('seaborn')
fig = plt.figure(num = 1,figsize=[8,4.5])
ax1 = fig.add_subplot(1,1,1)
ax1.plot([1.5,3.5,-2,1.6],color = (0.620005, 0.18384, 0.497524))
3.2.2 示例-2
mpl.style.use('seaborn')
fig = plt.figure(num = 1,figsize=[8,4.5])
ax1 = fig.add_subplot(1,1,1)
ax1.plot([1.5,3.5,2,1.6])
ax1.plot([1,2,3,4],'k--') # k表示黑色,-表示虚线
ax1.plot([1.1,2.1,3.1,4.1],'ko-') # k表示黑色,-表示虚线或linestyle = ’虚线’
3.2.3 示例-3 复杂线形图 含标记
# 使用样式和回滚
# mpl.style.use("违约") # 标注
mpl.style.use('seaborn')
# 原理说明:设置一个阈值将一个系列分成两个。 然后标记不同的颜色。
# 这是另一个点,plot(x,y)是标准形式。如果没有索引,则可以忽略x。
fig = plt.figure(figsize=[3,3])
ax1 = fig.add_subplot(1,1,1)
a = {x:round(x/100 +1,2) for x in range(0,100,1)}
data_1 = pd.Series(a)
data_2 = data_1[:51]
data_3 = data_1[50:]
x = [50]*4
y = [1,2,3,4]
# 一步步按操作来就行了
ax1.plot(data_2,'r')
ax1.plot(data_3,'b')
plt.plot(x,y)
3.2.4 示例-4
# def sgn(value):
# if value < 4:
# return 20
# else:
# return 15
# y = np.array([])
# for v in x:
# y = np.append(y,np.linspace(sgn(v),sgn(v),1))
f = lambda i : 20 if i < 4 else 15
plt.figure(figsize=(6,4))
x = np.linspace(0, 8, num = 100)
y = list(map(f,x))
l=plt.plot(x,y,'b',label='type')
plt.legend()
plt.show()
3.2.5 示例-5 高阶专业操作
import datetime as dt
# 原始数据
input_data = r'https://raw.githubusercontent.com/wesm/pydata-book/2nd-edition/examples/spx.csv'
data_i = pd.read_csv(
input_data,
index_col=0, # 将第一列设为索引
parse_dates=True # 自动解析日期格式
)
# 提取SPX500指数数据列
spx = data_i['SPX']
# 创建图形对象,设置画布尺寸
fig = plt.figure(figsize=[7.25, 4.0])
# 添加子图(1行1列第1个位置)
ax1 = fig.add_subplot(1, 1, 1)
# 绘制SPX指数曲线,黑色实线样式
spx.plot(ax=ax1, style='k-')
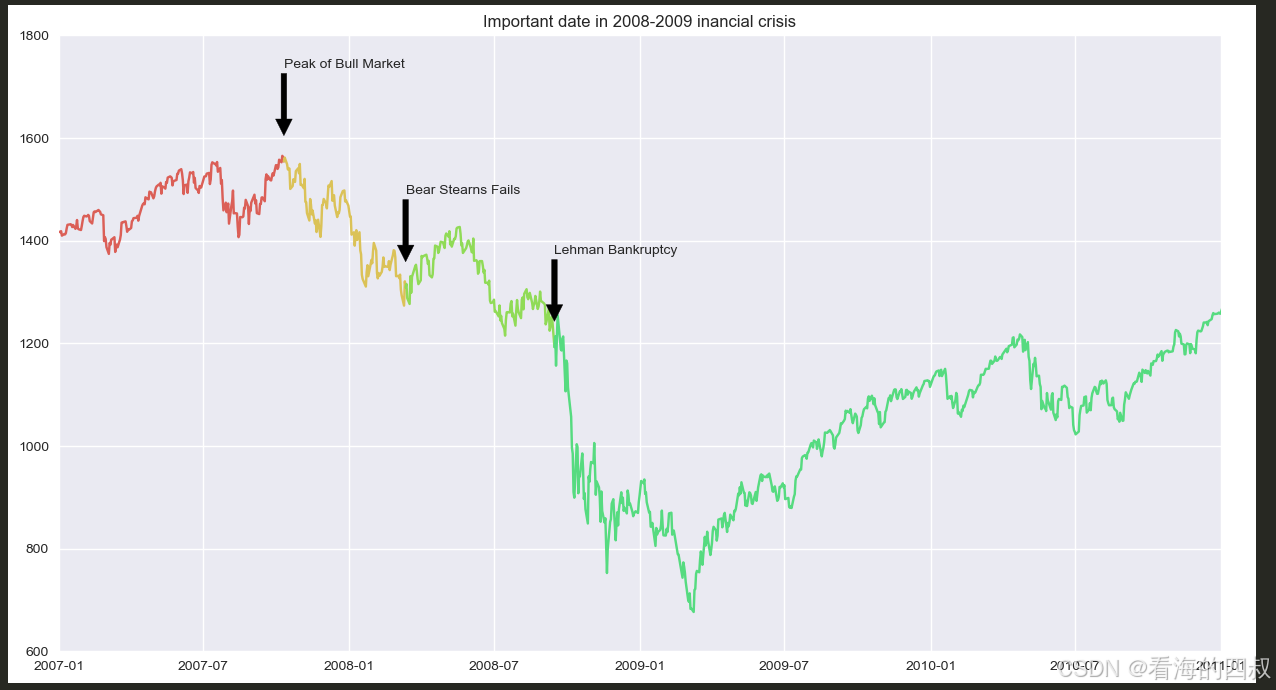
# 定义金融危机关键事件列表(日期+事件描述)
crisis_date = [
(dt.datetime(2007, 10, 11), 'Peak of Bull Market'),
(dt.datetime(2008, 3, 12), 'Bear Stearns Fails'),
(dt.datetime(2008, 9, 15), 'Lehman Bankruptcy')
]
# 遍历关键事件添加标注
for date, label in crisis_date:
ax1.annotate(
label,
xy=(date, spx.asof(date) + 50), # 箭头终点坐标(事件发生时的指数值+50)
xytext=(date, spx.asof(date) + 200), # 文本起始坐标(指数值+200)
arrowprops=dict(facecolor='black'), # 黑色箭头样式
horizontalalignment='left', # 文本左对齐
verticalalignment='top' # 文本顶部对齐
)
# 设置坐标轴范围
ax1.set_xlim(['1/1/2007', '1/1/2011']) # X轴显示2007-2011年
ax1.set_ylim([600, 1800]) # Y轴显示600-1800点区间
# 设置图表标题
ax1.set_title('Important dates in 2008-2009 financial crisis')
# 保存高清图片
plt.savefig('sample_1.png',
dpi=300, # 输出分辨率(300dpi适合印刷)
bbox_inches='tight' # 自动裁剪空白边缘
)
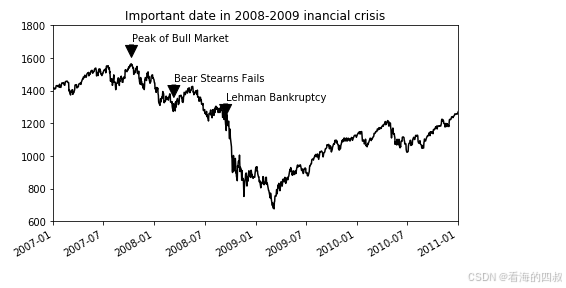
3.2.6 示例-6 顶级专业操作
# -*- coding: utf-8 -*-
"""
金融危机可视化分析模块
功能:绘制2007-2011年标普指数走势及关键事件标注
"""
# 模块导入区
import datetime as dt # 时间处理模块
import pandas as pd # 数据处理库
import matplotlib.pyplot as plt # 可视化核心模块
import seaborn as sns # 颜色主题扩展库
# 数据准备区
input_data = r'D:/spx.csv' # 原始数据路径
data_i = pd.read_csv(
input_data,
index_col=0, # 将第一列设为日期索引
parse_dates=True # 自动解析日期格式
)
spx = data_i['SPX'] # 提取标普500指数序列
# 可视化初始化
fig = plt.figure(figsize=[15, 8]) # 创建15x8英寸画布
ax1 = fig.add_subplot(1, 1, 1) # 创建单子图布局
# 时间分段处理
# 根据金融危机四个阶段划分数据区间:
# 阶段1:牛市顶峰前(2007-01-01 至 2007-10-11)
# 阶段2:贝尔斯登事件前(2007-10-12 至 2008-03-12)
# 阶段3:雷曼破产前(2008-03-13 至 2008-09-15)
# 阶段4:危机后期(2008-09-16 至 2011-01-01)
spx1 = spx[spx.index <= dt.datetime(2007, 10, 11)]
spx2 = spx[(spx.index <= dt.datetime(2008, 3, 12)) & (spx.index >= dt.datetime(2007, 10, 11))]
spx3 = spx[(spx.index <= dt.datetime(2008, 9, 15)) & (spx.index >= dt.datetime(2008, 3, 12))]
spx4 = spx[(spx.index >= dt.datetime(2008, 9, 15))]
# 颜色配置
CRISIS_PALETTE = sns.color_palette('hls', 8) # 使用8色调色板
# 分阶段绘制曲线
ax1.plot(spx1, color=CRISIS_PALETTE[0], label='Pre-Crisis')
ax1.plot(spx2, color=CRISIS_PALETTE[1], label='Bear Stearns Period')
ax1.plot(spx3, color=CRISIS_PALETTE[2], label='Lehman Pre-Collapse')
ax1.plot(spx4, color=CRISIS_PALETTE[3], label='Post-Lehman Era')
# 关键事件标注
crisis_date = [
(dt.datetime(2007, 10, 11), 'Peak of Bull Market'),
(dt.datetime(2008, 3, 12), 'Bear Stearns Fails'),
(dt.datetime(2008, 9, 15), 'Lehman Bankruptcy')
]
for date, label in crisis_date:
# 获取事件发生时点的最新有效价格
event_price = spx.asof(date)
# 创建箭头标注
ax1.annotate(
label,
xy=(date, event_price + 50), # 箭头终点坐标
xytext=(date, event_price + 200), # 文本起始位置
arrowprops=dict(
facecolor='black',
arrowstyle='->',
connectionstyle='arc3'
),
horizontalalignment='left', # 文本左对齐
verticalalignment='top' # 文本顶部对齐
)
# 坐标轴设置
ax1.set_xlim(['1/1/2007', '1/1/2011']) # X轴范围设置
ax1.set_ylim([600, 1800]) # Y轴范围设置
ax1.set_title('Important Dates in 2008-2009 Financial Crisis',
fontsize=14) # 修正标题拼写错误
# 输出配置
plt.savefig(
'sample_1.png',
dpi=300, # 印刷级分辨率
bbox_inches='tight', # 自动裁剪白边
facecolor='white' # 设置背景为白色
)
# 显示图形
plt.show()
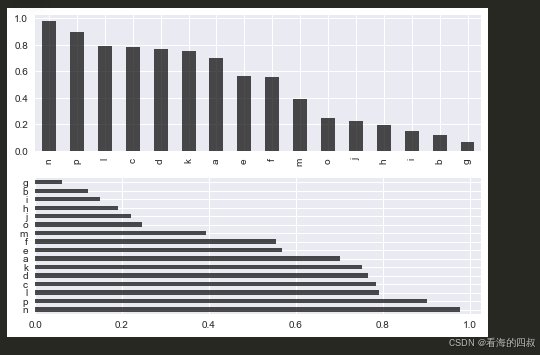
3.3 BAR 柱状图
3.3.1 示例-1
# 创建 2x1 子图布局,返回图形对象和坐标轴数组
fig, axes = plt.subplots(2,1)
# 生成随机数据序列,索引为字母a-p
data = pd.Series(np.random.rand(16), index=list('abcdefghijklmnop'))
# 降序排序数据,便于条形图按数值大小顺序显示
data = data.sort_values(ascending=False)
# 在上方子图绘制垂直条形图
# kind: 指定图表类型为垂直条形图
# color='k' 设置黑色,alpha=0.7 调整透明度增强可读性
data.plot(kind='bar', ax=axes[0], color='k', alpha=0.7)
# 在下方子图绘制水平条形图
# barh 类型更适合展示长标签数据,与垂直条形图形成对比分析
data.plot(kind='barh', ax=axes[1], color='k', alpha=0.7)
# 最佳实践建议:添加以下配置代码(原代码未包含)
plt.tight_layout() # 自动调整子图间距
plt.show() # 显示图形MJupyter中可省略
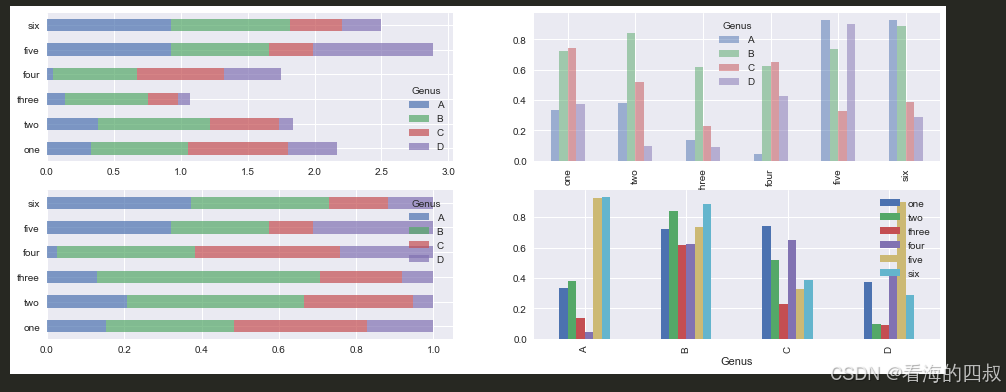
3.3.2 示例-2 多布局
# 创建6行4列的随机DataFrame,索引为英文单词,列名为"Genus"分类
# 使用pd.Index设置列名层级(适用于多级索引场景)
df = pd.DataFrame(
np.random.rand(6,4),
index=['one','two','three','four','five','six'],
columns=pd.Index(['A','B','C','D'], name='Genus')
)
# 初始化画布和4个子图,2*2 布局
fig = plt.figure(figsize=[16,6]) # 宽16,高6英寸的大尺寸画布
ax1 = fig.add_subplot(2,2,1) # 左上子图(第1位置)
ax2 = fig.add_subplot(2,2,2) # 右上子图(第2位置)
ax3 = fig.add_subplot(2,2,3) # 左下子图(第3位置)
ax4 = fig.add_subplot(2,2,4) # 右下子图(第4位置)
# 子图1:水平堆叠条形图(stacked=1实现堆叠效果) 要求和布局位置一一对应
# alpha=0.7增强堆叠部分的透明度区分度
df.plot(kind='barh', stacked=1, alpha=0.7, ax=ax1)
# 子图2:垂直并列条形图(默认stacked=0)
# alpha=0.5降低色块饱和度避免视觉压迫
df.plot(kind='bar', stacked=0, alpha=0.5, ax=ax2)
# 数据预处理:将原始数据转换为行方向百分比(行和为100%)
df_ptc = df.div(df.sum(1), axis=0) # 网页4:DataFrame行标准化操作
# 子图3:百分比水平堆叠条形图
df_ptc.plot(kind='barh', stacked=1, alpha=0.7, ax=ax3)
# 子图4:数据重塑后的垂直条形图
# stack().unstack(0) 实现行列转置:将列变为索引,索引变为列
# 原数据形状(6,4) → 重塑后形状(4,6),实现不同维度的数据对比
df.stack().unstack(0).plot(kind='bar', ax=ax4)
# 待优化项:坐标轴范围设置(示例)
# ax1.set_xlim(0, df.values.max()*1.2) # 扩展20%留白
# ax4.set_xticks(range(4)) # 明确显示每个分类
plt.show()
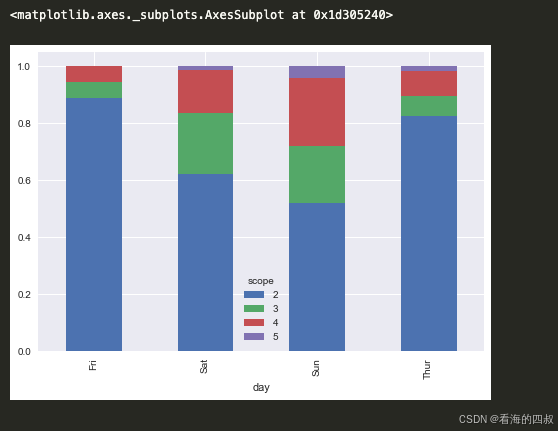
3.3.3 示例-3
# 读取数据 加载餐饮小费数据集
file_path = r'D:/tips.csv'
tips = pd.read_csv(file_path)
party_counts = pd.crosstab(tips.day, tips.size)
party_counts = party_counts.loc[:, 2:5]
# 计算各规模占比
party_pct = party_counts.div(party_counts.sum(1).astype(float), axis=0)
# 绘制堆叠百分比条形图
# - kind='bar':垂直条形图
# - stacked=1:堆叠显示不同规模占比
# - alpha=0.7 建议添加透明度增强可读性
party_pct.plot(kind='bar', stacked=True, alpha=0.7)
# 扩展建议
plt.title('不同日期用餐规模分布比例', fontsize=12) # 添加主标题
plt.ylabel('比例', fontsize=10) # Y轴标签
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left') # 右侧外置图例
plt.xticks(rotation=45) # 旋转日期标签防止重叠
plt.tight_layout() # 自动调整子图间距
四、总结
总共整理了2期,关于【Python】分析图标可视化visualization的内容(2期地址点这里),希望有帮助。


















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









