







决策树算法全解析:原理、实现与对比
一、算法概述
1. 原理
决策树是一种基于树结构的监督学习算法,通过递归划分数据实现分类或回归。
其【核心思想】是通过特征属性的判断逐步将数据分配到不同的子节点,最终在叶节点输出分类或回归结果。
- 结构组成:包含根节点(起始特征)、内部节点(特征判断分支)和叶节点(最终分类/回归结果)。
- 应用领域:金融风控(如贷款风险评估)、医疗诊断、客户分类等。
- 核心特点:支持离散型和连续型数据混合处理;规则可视化强,易于解释。
- 其三大经典算法包括:
- ID3:1986年提出的基础算法,使用信息增益选择特征
- C4.5:ID3改进版,引入信息增益率和剪枝技术,能处理离散数据也可处理连续描述数据
- CART:支持分类与回归的二叉树算法(通过构建树,修剪树,评估树来构建二叉树),采用基尼系数
二、核心准测和构建过程
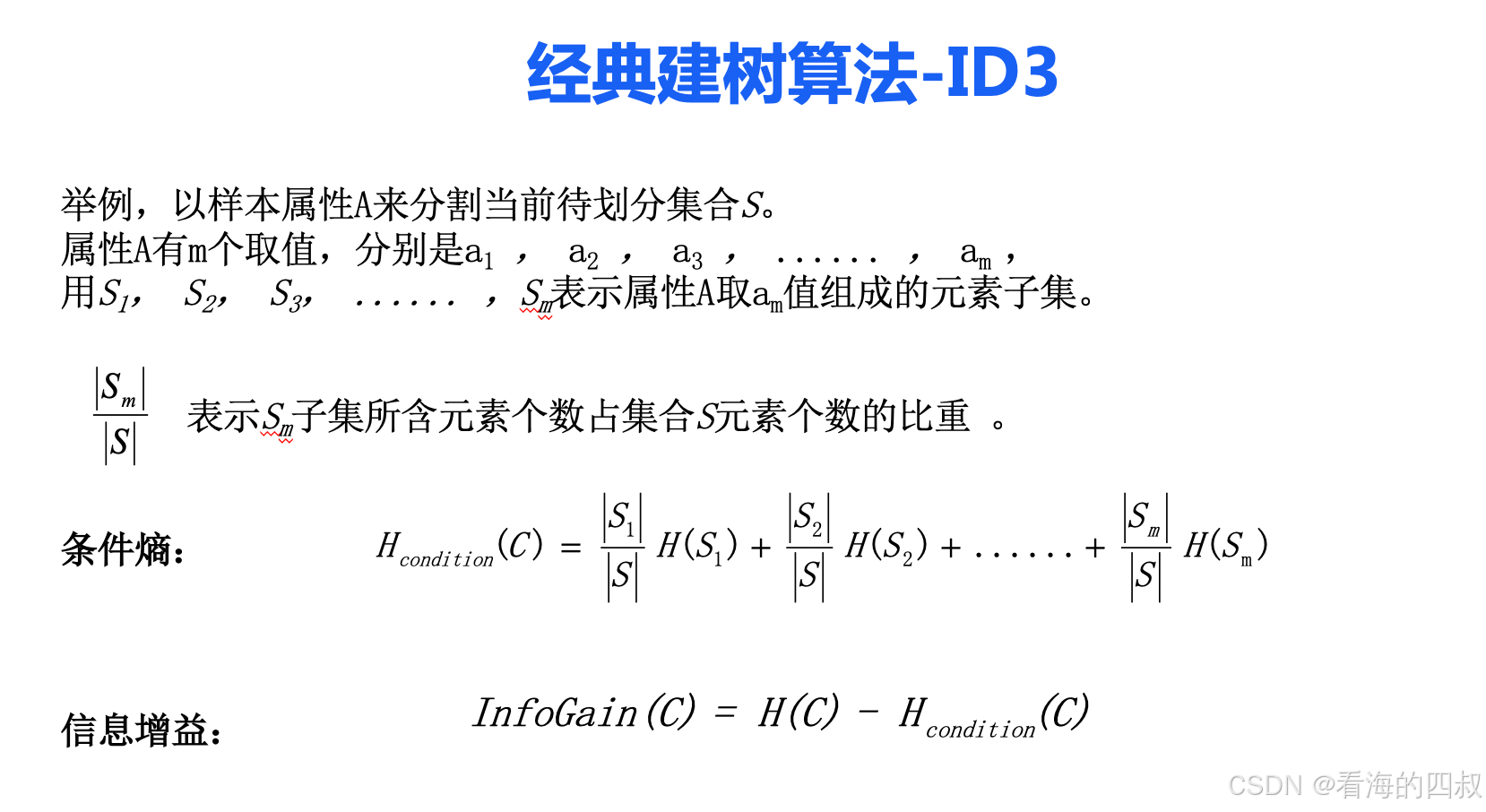
2.1 特征选择准则
| 算法 | 分裂准则 | 公式 | 使用范围 |
|---|---|---|---|
| ID3 | 信息增益 | 略 | 基于信息熵减少量,偏向选择取值多的特征 |
| C4.5 | 信息增益率 | GainRatio = Gain(D,A)/SplitInfo(D,A) | 修正信息增益的偏差,适用于处理连续值和缺失值 |
| CART | 基尼系数 | Gini(D) = 1 - Σ(p_i²) | 衡量数据不纯度,适用于分类和回归任务 |
2.2 核心差异
- 树结构:ID3/C4.5生成多叉树,CART生成二叉树
- 任务支持:CART支持回归任务(MSE最小化)
- 缺失处理:C4.5/CART支持缺失值自动处理
2.3 构建流程
- 特征选择:根据算法选择最优划分特征,即分裂得分
- 递归分割:选择最优特征划分数据集,从根节点开始,按特征取值划分子节点,直至满足停止条件
- 停止条件:节点纯度达标或达到最大深度
- 剪枝优化:预剪枝限制树深度或设置最小样本数,后剪枝法降低过拟合
三、算法实现与可视化
3.1 数据与环境预处理
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris # 加载鸢尾花数据集
from sklearn.model_selection import train_test_split # 数据集划分工具
from sklearn.tree import DecisionTreeClassifier,export_graphviz # CART分类树模型,决策树可视化导出工具
from sklearn.metrics import accuracy_score # 准确率评估工具
import graphviz # Graphviz图形渲染库
import matplotlib.pyplot as plt # 绘图库,用于特征重要性可视化
3.1 算法实现与可视化 - ID3
def calc_entropy(y):
"""
计算信息熵,用于评估数据纯度
参数: y - 目标变量数组(类别标签)
返回: entropy - 信息熵值
"""
classes, counts = np.unique(y, return_counts=True) # 统计类别唯一值和出现次数
probabilities = counts / len(y) # 计算每个类别的概率
return -np.sum(probabilities * np.log2(probabilities)) # 信息熵公式
def id3(X, y, features):
"""
ID3算法递归构建决策树
参数:
X - 特征矩阵(numpy数组)
y - 目标变量(类别数组)
features - 当前可用特征列表
返回: 树结构字典
"""
if len(np.unique(y)) == 1: # 终止条件1:节点纯度达标(所有样本同一类别)
return y[0](@ref)
if len(features) == 0: # 终止条件2:无可用特征(返回多数类别)
return np.argmax(np.bincount(y))
# 计算各特征信息增益
best_gain = -1
best_feature_idx = None
for i in range(X.shape[1](@ref)): # 遍历每个特征列
feature_values = X[:, i]
unique_values = np.unique(feature_values)
entropy_sum = 0
for value in unique_values: # 按特征值划分子集
subset_mask = (feature_values == value)
subset_y = y[subset_mask]
entropy_sum += (len(subset_y)/len(y)) * calc_entropy(subset_y)
gain = calc_entropy(y) - entropy_sum # 信息增益计算
if gain > best_gain:
best_gain = gain
best_feature_idx = i
# 递归构建子树
best_feature = features[best_feature_idx]
tree = {best_feature: {}} # 创建以最佳特征为根节点的子树
remaining_features = [f for f in features if f != best_feature]
for value in np.unique(X[:, best_feature_idx]):
subset_mask = (X[:, best_feature_idx] == value)
subset_X = X[subset_mask]
subset_y = y[subset_mask]
tree[best_feature][value] = id3(subset_X, subset_y, remaining_features) # 递归调用
return tree
3.2 算法实现与可视化 - CART


# 数据准备
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练CART分类树(基尼指数) 37分
clf = DecisionTreeClassifier(criterion='gini', max_depth=3)
clf.fit(X_train, y_train)
# 模型评估
print(f"测试集准确率: {clf.score(X_test, y_test):.2f}") # 输出示例:0.97
# 决策树可视化(Graphviz)
dot_data = export_graphviz(
clf,
out_file=None,
feature_names=iris.feature_names, # 特征名称标注
class_names=iris.target_names, # 类别名称标注
filled=True, # 填充颜色表示类别
rounded=True # 圆角节点
)
graph = graphviz.Source(dot_data)
graph.render("iris_cart_tree") # 生成PDF文件(需安装Graphviz环境)
# 特征重要性可视化(Matplotlib)
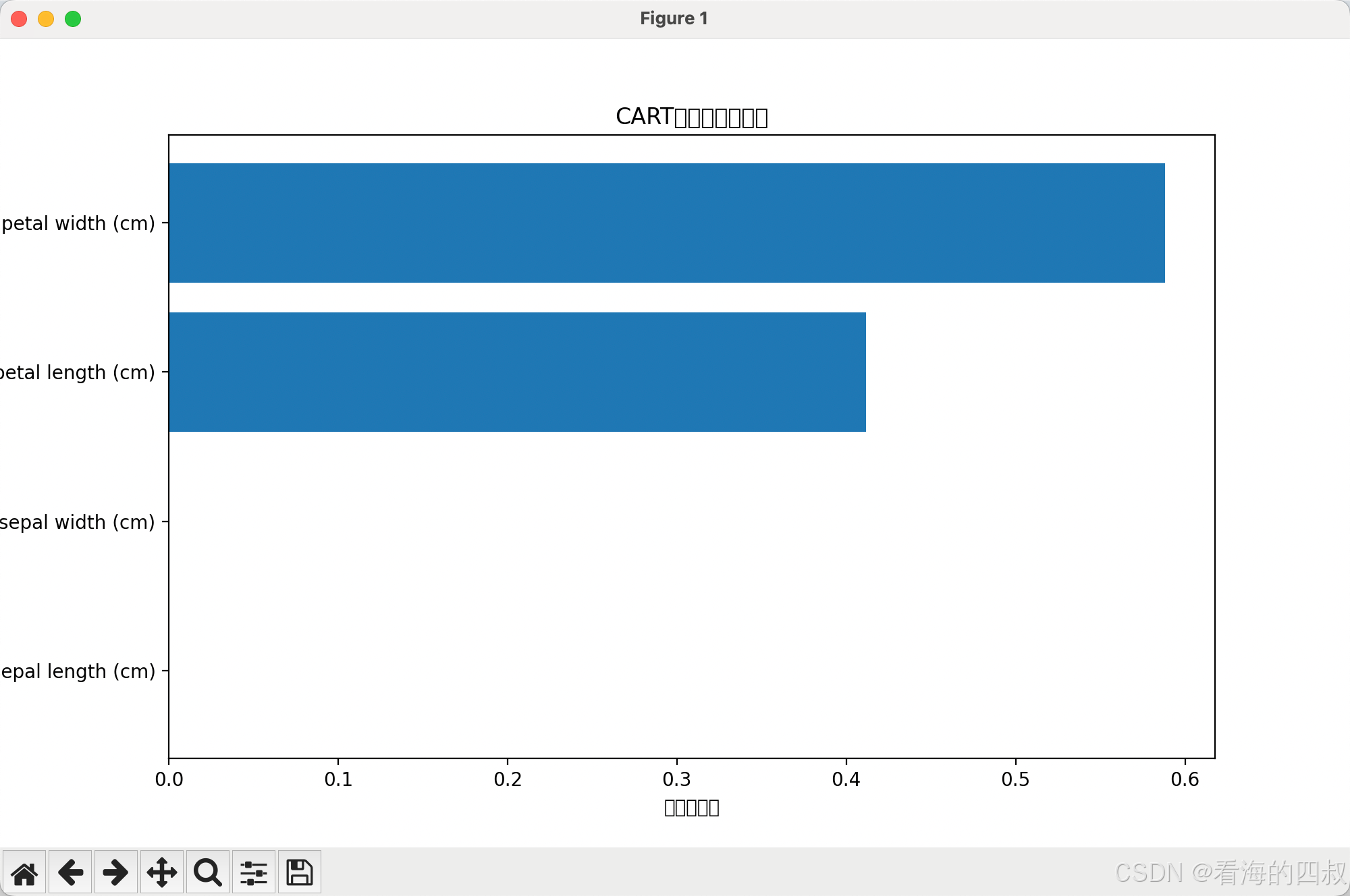
plt.figure(figsize=(10,6))
plt.barh(iris.feature_names, clf.feature_importances_)
plt.xlabel("特征重要性")
plt.title("CART特征重要性分析")
plt.show()
# 可视化效果说明,如下图:
# 节点颜色深浅表示类别纯度(颜色越深纯度越高)
# 分裂条件如petal length <= 2.45展示决策路径
# 特征重要性条形图显示花瓣长度(petal length)是分类关键特征
四、模型优缺点对比
| 维度 | ID3 | C4.5 | CART |
|---|---|---|---|
| 特征选择 | 信息增益 | 信息增益率 | 基尼系数/MSE |
| 树结构 | 多叉树 | 多叉树 | 二叉树 |
| 任务支持 | 分类 | 分类 | 分类+回归 |
| 缺失值处理 | 不支持 | 支持 | 支持 |
| 优点 | 原理简单,适合小规模数据 | 支持连续属性和缺失值处理 | 基尼指数计算效率高 |
| 主要缺陷 | 偏向多值属性,无法处理连续值和缺失值 | 计算复杂度高,需多次扫描数据 | 二叉树结构可能增加树深度 |
选型建议:
- 小规模分类优先C4.5,规则可解释性强;
- 大规模/回归任务必选CART,计算效率高;
五、总结与展望
决策树作为机器学习基础模型,凭借其可解释性和灵活性,成为随机森林、GBDT等集成算法的基石。
不同算法适用场景各异:
- ID3:适合教学和小规模离散数据;
- C4.5:需处理连续值或缺失值时优选;
- CART:工业级应用(如风控评分卡)的首选。
实际应用中需通过剪枝和参数调优(如网格搜索)提升泛化能力,避免过拟合问题


















 84
84

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









