







 本文解析了如何使用哈希算法和ASCII编码快速判断两个字符串s和t是否为字母异位词。通过创建一个记录数组,利用字符到ASCII值的映射进行加减操作,判断字符频率是否一致。时间复杂度为O(n),空间复杂度为O(1)。
本文解析了如何使用哈希算法和ASCII编码快速判断两个字符串s和t是否为字母异位词。通过创建一个记录数组,利用字符到ASCII值的映射进行加减操作,判断字符频率是否一致。时间复杂度为O(n),空间复杂度为O(1)。
数组的hash算法
你给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1: 输入: s = “anagram”, t = “nagaram” 输出: true
示例 2: 输入: s = “rat”, t = “car” 输出: false
说明: 你可以假设字符串只包含小写字母。
解释
也就是说 a、b二个字符串中的字符出现的次数是否一样,可以通过把每个字符减掉ASCLL中 ’a‘的值得到一个统一的数组下标,然后这个数组下标可以对应数字,具体的如下:
定义一个数组叫做record用来上记录字符串s里字符出现的次数。
需要把字符映射到数组也就是哈希表的索引下表上,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下表0,相应的字符z映射为下表25。
再遍历 字符串s的时候,只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。 这样就将字符串s中字符出现的次数,统计出来了。
那看一下如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
那么最后检查一下,record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
代码实现
public static void main(String[] args) {
String a = "as";
String b = "sa";
System.out.println(isAnagram(a,b));
}
public static boolean isAnagram(String s, String t) {
int [] record = new int[26];
for (char c : s.toCharArray()) {
record[c - 'a'] += 1;
}
for (char i : t.toCharArray()) {
record[i - 'a'] -= 1;
}
for (int i : record) {
if (i != 0) {
return false;
}
}
return true;
}
链接: link.
图片: 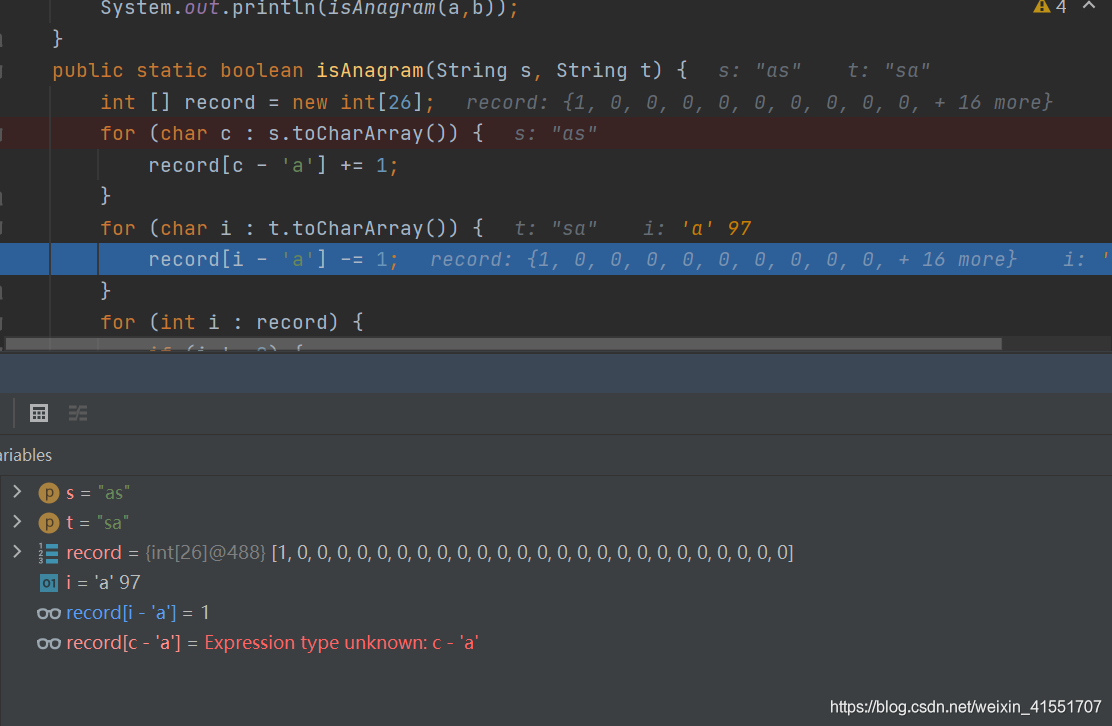
来源:
[1]: https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0242.%E6%9C%89%E6%95%88%E7%9A%84%E5%AD%97%E6%AF%8D%E5%BC%82%E4%BD%8D%E8%AF%8D.md

















 1892
1892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









