






实验一:分析tomcat的访问日志,求访问量最高的两个网页
题目:
Tomcat的访问日志文件为localhost_access_log.2017-07-30,格式如下:

求出访问量最高的两个网页。要求输出以下格式:
网页名称、访问量
代码:
from pyspark import SparkConf, SparkContext
# 192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/ HTTP/1.1" 200 259
# 求出访问量最高的两个网页。要求输出以下格式:
# 网页名称、访问量
conf = SparkConf().setAppName("WordCount").setMaster("local")
sc = SparkContext(conf=conf)
inputFile = '/home/swy/input/localhost_access_log.2017-07-30.txt'
textFile = sc.textFile(inputFile)
wordCount = textFile.map(lambda line: line.split("MyDemoWeb/")[1])\
.map(lambda line: line.split(" HTTP")[0]).map(lambda word: (word, 1))\
.reduceByKey(lambda x, y: x + y).sortBy(lambda x: x[1], False).take(2)
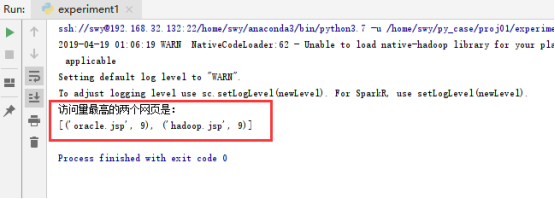
print('访问量最高的两个网页是:\n{}'.format(wordCount))
运行结果:
实验二:使用Spark程序进行数据的清洗
题目:
数据源userclicklogProblem文件记录了用户点击的日志记录,但日志中存在不合规范的数据。请用Spark程序进程数据清洗,完成以下操作:
- 过滤不满足6个字段的数据
- 过滤URL为空的数据
代码:
from pyspark import SparkConf, SparkContext
# 1,201.105.101.102,http://mystore.jsp/?productid=1,2017020020,1,1
# 2,201.105.101.103,http://mystore.jsp/?productid=2,2017020022,1,1
# 3,201.105.101.105,http://mystore.jsp/?productid=3,2017020023,1,2
# 4,201.105.101.107,http://mystore.jsp/?productid=1,2017020025,1,1
# 1,201.105.101.102,http://mystore.jsp/?productid=4,2017020021,3,1
# 1,201.105.101.102,http://mystore.jsp/?productid=1,2017020029,2,1
# 1,201.105.101.102, ,2017020029,2,1
# 1,201.105.101.102, ,2017020029,2
# (1)过滤不满足6个字段的数据
# (2)过滤URL为空的数据
conf = SparkConf().setAppName("WordCount").setMaster("local")
sc = SparkContext(conf=conf)
inputFile = '/home/swy/input/userclicklogProblem.txt'
textFile = sc.textFile(inputFile)
# wordCount = textFile.map(lambda line: line.split(","))\
# .filter(lambda x: len(x) == 6).filter(lambda x: x[2] != " ")
# print('过滤后的数据如下:\n{}'.format(wordCount))
wordCount = textFile.map(lambda line: line.split(","))\
.filter(lambda x: len(x) == 6).filter(lambda x:x[2]!=" ")
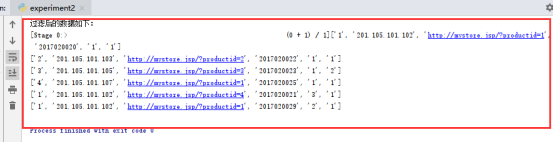
print("过滤后的数据如下:")
wordCount.foreach(print)
运行结果:
实验三:人口身高数据分析
题目:
假设我们需要对某个省的人口 (1 亿) 性别还有身高进行统计,需要计算出男女人数,男性中的最高和最低身高,以及女性中的最高和最低身高。本案例中用到的源文件有以下格式,三列分别是 ID,性别,身高 (cm)。

代码:
from pyspark import SparkConf, SparkContext
# 假设我们需要对某个省的人口 (1 亿) 性别还有身高进行统计,需要计算出男女人数,男性中的最高和最低身高,
# 以及女性中的最高和最低身高。本案例中用到的源文件有以下格式,三列分别是 ID,性别,身高 (cm)。
# 1 M 103
# 2 F 215
# 3 M 169
# 4 F 190
# 5 F 132
conf = SparkConf().setAppName("WordCount").setMaster("local")
sc = SparkContext(conf=conf)
inputFile = '/home/swy/input/sample_people_info.txt'
textFile = sc.textFile(inputFile)
# 男人数
wordCount1 = textFile.map(lambda line: line.split(" ")).filter(lambda x: x[1] == 'M').count()
# 女人数
wordCount2 = textFile.map(lambda line: line.split(" ")).filter(lambda x: x[1] == 'F').count()
# 男人中最高身高
wordCount3 = \
textFile.map(lambda line: line.split(" ")).filter(lambda x: x[1] == 'M').sortBy(lambda x: x[2], False).take(1)[0][2]
# 男人中最矮身高
wordCount4 = \
textFile.map(lambda line: line.split(" ")).filter(lambda x: x[1] == 'M').sortBy(lambda x: x[2], True).take(1)[0][2]
# 女人中最高身高
wordCount5 = \
textFile.map(lambda line: line.split(" ")).filter(lambda x: x[1] == 'F').sortBy(lambda x: x[2], False).take(1)[0][2]
# 女人中最矮身高
wordCount6 = \
textFile.map(lambda line: line.split(" ")).filter(lambda x: x[1] == 'F').sortBy(lambda x: x[2], True).take(1)[0][2]
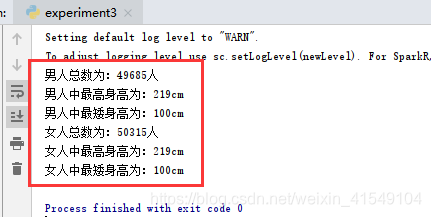
print('男人总数为:{}人'.format(wordCount1))
print('男人中最高身高为:{}cm'.format(wordCount3))
print('男人中最矮身高为:{}cm'.format(wordCount4))
print('女人总数为:{}人'.format(wordCount2))
print('女人中最高身高为:{}cm'.format(wordCount5))
print('女人中最矮身高为:{}cm'.format(wordCount6))
运行结果:


















 3269
3269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











