







简单介绍
1,介绍
Hadoop存在如下一些缺点:表达能力有限、磁盘IO开销大、延迟高、任务之间的衔接涉及IO开销、在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务
Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题。
相比于Hadoop MapReduce,Spark主要具有如下优点:
Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活
Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
核心模块
Spark Core:Spark Core中提供了Spark最基础与最核心的功能。Spark其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib都是在Spark Core的基础上进行扩展的
Spark SQL:Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
Spark Streaming:Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
Spark Mllib:MLlib是Spark提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
Spark GraphX:GraphX是Spark面向图计算提供的框架与算法库。
Spark Core - 基本概念
RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task
应用(Application):用户编写的Spark应用程序
任务( Task ):运行在Executor上的工作单元
作业( Job ):一个作业包含多个RDD及作用于相应RDD上的各种操作
阶段( Stage ):是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为阶段,或者也被称为任务集合,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集
Spark计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
- RDD : 弹性分布式数据集
- 累加器:分布式共享只写变量
- 广播变量:分布式共享只读变量
Spark Core - 运行流程
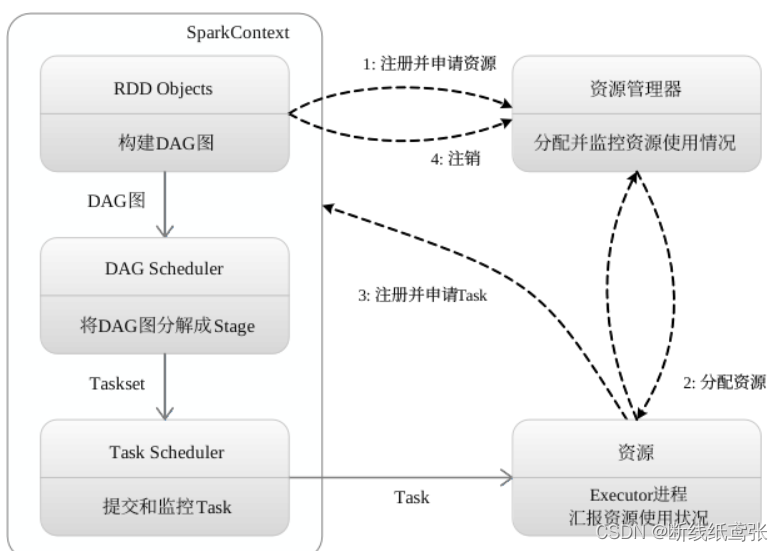
(1)首先为应用构建起基本的运行环境,即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控
(2)资源管理器为Executor分配资源,并启动Executor进程
(3)SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,并提供应用程序代码
(4)Task在Executor上运行,把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源
Spark Core - RDD
RDD 设计背景
许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具,共同之处是,不同计算阶段之间会重用中间结果
目前的MapReduce框架都是把中间结果写入到稳定存储(比如磁盘)中,带来了大量的数据复制、磁盘IO和序列化开销
RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储
-
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算
-
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和group by)而创建得到新的RDD
-
RDD提供了一组丰富的操作以支持常见的数据运算,分为“动作”(Action)和“转换”(Transformation)两种类型
-
RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改(不适合网页爬虫)
-
表面上RDD的功能很受限、不够强大,实际上RDD已经被实践证明可以高效地表达许多框架的编程模型(比如MapReduce、SQL、Pregel)
-
Spark提供了RDD的API,程序员可以通过调用API实现对RDD的各种操作
1、转换操作
| 操作 | 含义 |
|---|---|
| filter(func) | 筛选出满足函数func的元素,并返回一个新的数据集 |
| map(func) | 将每个元素传递到函数func中,并将结果返回为一个新的数据集 |
| flatMap(func) | 与map()相似,但每个输入元素都可以映射到0或多个输出结果 |
| groupByKey() | 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集 |
| reduceByKey(func) | 应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果 |
2、行动操作
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。
| 操作 | 含义 |
|---|---|
| count() | 返回数据集中的元素个数 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| first() | 返回数据集中的第一个元素 |
| take(n) | 以数组的形式返回数据集中的前n个元素 |
| reduce(func) | 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 |
| foreach(func) | 将数据集中的每个元素传递到函数func中运行 |
3、惰性机制
所谓的“惰性机制”是指,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算。这里给出一段简单的语句来解释Spark的惰性机制:
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
lineLengths = lines.map(lambda s:len(s))
totalLength = lineLengths.reduce(lambda a,b:a+b)
print(totalLength)
4、持久化
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据
>>> list = ["Hadoop","Spark","Hive"]
>>> rdd = sc.parallelize(list)
>>> print(rdd.count()) //行动操作,触发一次真正从头到尾的计算
3
>>> print(','.join(rdd.collect())) //行动操作,触发一次真正从头到尾的计算
Hadoop,Spark,Hive
可以通过持久化(缓存)机制避免这种重复计算的开销
可以使用persist()方法对一个RDD标记为持久化
之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化
持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用
Spark Core - RDD 分区
RDD分区的一个原则是使得分区的个数尽量等于集群中的CPU核心(core)数目。
对于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism这个参数的值,来配置默认的分区数目,一般而言:
本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N
Apache Mesos:默认的分区数为8
Standalone或YARN:在“集群中所有CPU核心数目总和”和“2”二者中取较大值作为默认值
创建RDD时手动指定分区个数
使用reparititon方法重新设置分区个数
从文件中加载
>>> lines = sc.textFile("file:///usr/local/spark/mycode/pairrdd/word.txt")
>>> pairRDD = lines.flatMap(lambda line:line.split(" ")).map(lambda word:(word,1))
>>> pairRDD.foreach(print)
('I', 1)
('love', 1)
('Hadoop', 1)
……
通过并行集合(列表)创建
>>> list = ["Hadoop","Spark","Hive","Spark"]
>>> rdd = sc.parallelize(list)
>>> pairRDD = rdd.map(lambda word 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









