







 本文介绍了使用Python进行机器学习数据预处理的实用方法,包括计算属性间的相关性、查看数据描述统计信息以及处理缺失值的三种策略:删除包含缺失值的记录、删除整个属性或用中位数填充缺失值。
本文介绍了使用Python进行机器学习数据预处理的实用方法,包括计算属性间的相关性、查看数据描述统计信息以及处理缺失值的三种策略:删除包含缺失值的记录、删除整个属性或用中位数填充缺失值。
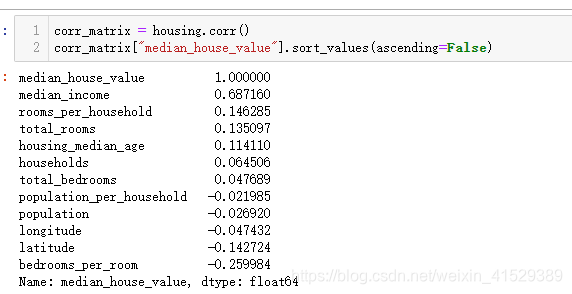
1 使用corr()方法计算每对属性间的标准相关系数(standard correlation coefficient)
corr_matrix = housing.corr()
2 housing.describe()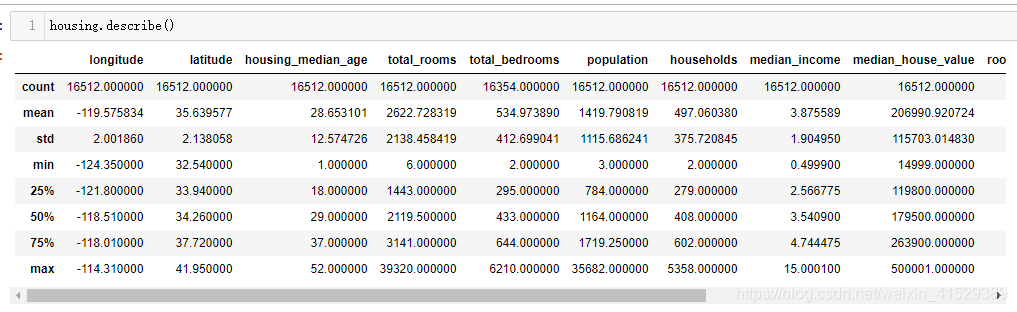
3 数据清洗
大多数机器学习算法不能处理缺失值,因此先创建一些函数来处理特征缺失的问题。前面属性total_bedrooms有一些缺失值。有三个解决选项:
- 去掉对应的街区
- 去掉整个属性
- 进行赋值(0、平均值、中位数等等)
用DataFrame的dropna(),drop(),和fillna()方法,可以很方便地实现:
housing.dropna(subset=["total_bedrooms"]) # 选项1
housing.drop("total_bedrooms", axis=1) # 选项2
median = housing["total_dedrooms"].median()
housing["total_bedrooms"].fillna(median) # 选项3

















 3769
3769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









