







 本文深入剖析了MapReduce体系结构,详细介绍了其工作流程,包括Shuffle过程原理,以及通过WordCount任务实例展示了MapReduce如何处理大规模数据集。适用于理解大数据处理框架。
本文深入剖析了MapReduce体系结构,详细介绍了其工作流程,包括Shuffle过程原理,以及通过WordCount任务实例展示了MapReduce如何处理大规模数据集。适用于理解大数据处理框架。
一、MapReduce体系结构
- 体系结构概述
MapReduce体系主要包括四个模块,Client、JobTracker、TaskTracker和Task。

- Client模块(客户端)
① 用户通过Client将应用程序交给JobTracker端
② 用户可以通过Client提供的接口取查询当前提交作业的运行状态。 - JobTracker(作业跟踪器)
① 负责资源的监控和作业的调度,跟踪任务执行进度及资源使用
② 监控底层的其他的TaskTracker以及当前运行的Job的状态
③ 一旦Job不正常,就把这个任务转移到其他节点继续执行 - TaskScheduler(任务调度器)
① JobTracker将任务信息发送给TaskScheduler,由TaskScheduler将任务分发给具体的TaskTracker去执行。
② TaskScheduler是可插拔的,预先用户自己实现任务调度策略。 - TaskTracker(任务跟踪器)
① 执行具体任务,接收JobTracker传过来的命令,比如启动和结束任务。
② 将节点资源使用情况及任务的执行情况通过心跳的方式 (heartbeat) 发送给JobTracker。
③ 以slot(槽)为资源分配的单位
Tips:机器上CPU和饥内存资源打包并等分为slot,分为map类slot和reduce类slot,两种slot不互通且只能分配给相应类型Task - Task(任务)
① 分为Map类Task和Reduce类Task,分别执行map任务及reduce任务。
② 一个Job由一个或多个Task组成。
二、MapReduce工作流程
- 流程图

- 流程描述
MapReduce任务启动后:
① 通过InputFormat模块从HDFS文件系统加载文件并将文件切分为多个分片(split,即将大文件按用户定义地大小分为几份,最合理的分片值应该等于HDFS块大小)
② 接下来记录阅读器(RR)根据分片长度信息,将相关分片读出来并输出为K-V形式。
③ Map接收来自(记录阅读器)RR的输入后,根据用户编写的Map方法逻辑处理输入,并输出中间结果(也是K-V形式),有多少个分片就有多少个Map。
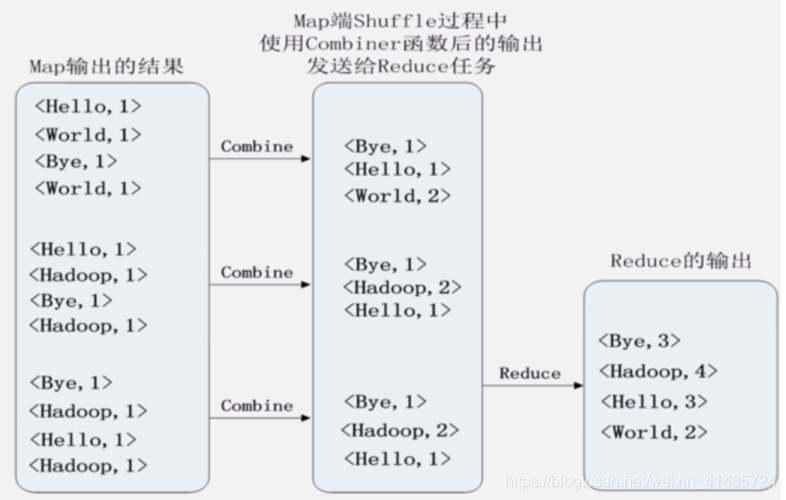
④ 中间结果进入Shuffle过程,Shuffle过程主要是分区、排序、合并和归并等任务的处理,经过Shuffle过程的数据才能正确分发给Reduce任务处理(其实就是将对应Reduce处理的任务)。
⑤ Shuffle完毕后数据分发给Reduce任务,Reduce任务执行用户编写的处理逻辑,最终结果仍以K-V形式输出。
Reduce任务数量不定,最优的情况是比一个TaskTracker上reduce类slot的数量少一点,少的部分用于处理可能出现的异常。
⑥ 最终结果输入到OutputFormat检查输出格式及输出路径正确性,最终结果存入HDFS文件系统。
Tips:Map输出结果不存入HDFS,而是存在执行任务机器的本地磁盘上。
三、 Shuffle过程原理
- Shuffle过程是介于Map过程及Reduce过程中间的数据处理过程,可以分为Map端的Shuffle过程及Reduce端的Shuffle过程。
- Map端Shuffle过程
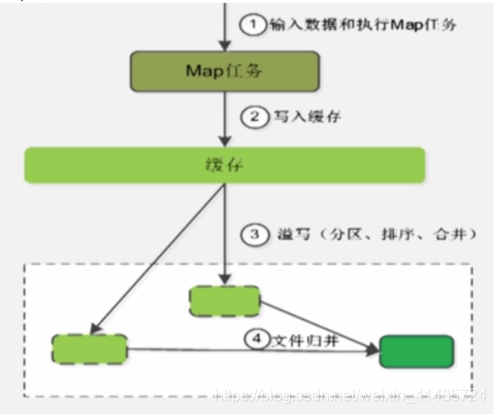
① 第一步:输入数据和执行Map任务
② 第二步:写入缓存,缓存主要是为减少由于经常写磁盘而造成的寻址开销。
③ 第三步:当缓存存储量到达限定值(一般为缓冲区大小80%,多出来的是为使Map任务能够继续输出结果)时启动溢写。在写入前还会对数据进行分区、排序和合并操作。分区以便分给对应的Reduce任务,按key的字典序进行排序使得数据有序,接着进行合并(不一定执行)以减少写入磁盘的数据量。
④ 第四步:将所有溢写文件归并为一个大文件并放入本地磁盘,此时文件中键值对都是分区且排序的。
⑤ 第五步:这个过程中JobTracker会一直监测Map任务执行情况,如果监测到Map完成,JobTracker就会通知相应Reduce任务取走数据。 - Reduce端Shuffle过程
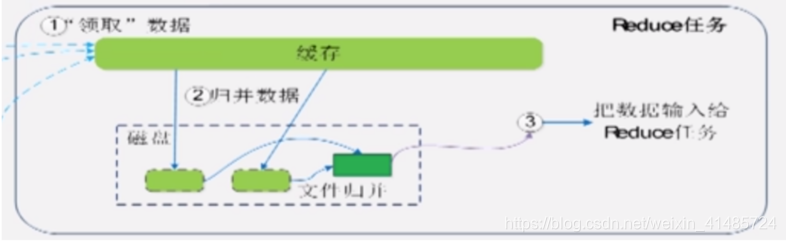
① 第一步:询问JobTracker数据是否已经可拉取,当收到可取 消息时将数据从多个Map机磁盘上拉到本地Reduce机磁盘上。
② 第二步:由于接收到的是来自多个Map任务的数据,因此需要归并数据———将值构成一个Key-列表valuelist(<a,1>和<a,1>归并为<a,<1,1>>)。归并产生的文件存在磁盘中且数量可能不止一个。
③ 第三步:Reduce任务获取来自归并文件的数据。
Tips:如果数据量小到Reduce缓存能够存下,那就不生成文件直接输入给Reduce任务
四、实例解析——WordCount任务
- 设计思想
WordCount(词频统计)任务读取文件并进行单词分割及统计,可以对文件进行分割,分别处理每一段的词频统计结果,最后汇总结果即可。处理过程满足分治的思想,可使用MapReduce。 - 输入和输出格式
输入数据是一段可长可短的文字,输出结果每个单词及其出现频次以K-V形式展示。 - MapReduce过程
① Map过程
文件被分为三个分片,每个分片分别执行Map任务并输出在该分片数据中的词频统计结果。

② Shuffle及Reduce过程
无合并过程,Shuffle生成的是Key-ValueList。
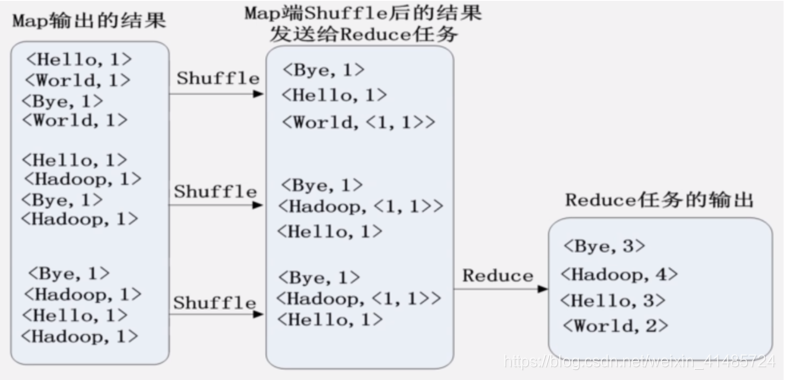
有合并过程,Shuffle生成的是K-V。
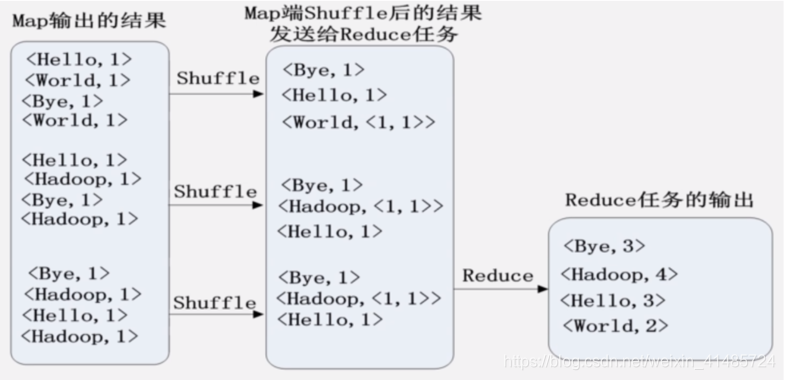
Reduce过程合并相同的键,最终输出结果即为总的词频统计结果。
资料来源:
大数据技术原理与应用慕课视频——厦门大学林子雨老师

















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









