






HIVE
Apache Hive是构建在Apache Hadoop之上的数据仓库,有助于对大型的数据集进行读写和管理。
HIVE和传统数据库的区别在于:
时效性高,延时性比较高,可扩展性高;
Hive优势在于处理大数据集;
大数据场景下大多是select;
对于离线来说事务没有什么实际意义;
RDBMS支持分布式,节点有限,成本高,处理数据量小;
Hadoop集群规模大,部署在廉价机器上,处理数据量大;
数据库存储于localFS,Hive存储于HDFS;
Hive加载过程中不会对数据本身进行修改,不需要进行格式转化,只是将数据复制或者移动到HDFS中;
数据库中,不同数据库有不同存储引擎,定义了自己的数据存储格式,所有数据都会按照一定组织存储,加载过程会比较耗时。
Hive执行MapReduce;数据库执行Executor。
1.读时模式和写时模式
在传统数据库中,表的模式是在数据加载时强制确定的。如果在加载时发现数据不符合模式,则拒绝加载数据。
因为数据是写入数据库时对照模式进行检查,因此这一设计有时被称为 “写时模式” 。
Hive对数据的验证并不在加载数据时进行,而是在查询时进行,这称为 “读时模式” 。
读时模式使数据加载非常迅速,因为不需要读取数据进行解析。
写时模式有利于提升查询性能。
2.更新、事务、索引
为传统数据库最重要的特性。
HDFS不提供就地文件更新,因此插入、更新和删除操作引起的一切变化都被保存在一个较小的增量文件中。由metastore在后台运行的MapReduce作业会定期将这些增量文件合并到“基表”文件中。
正在使用的表必须启用事务,才能使上述功能奏效,以保证对这些表进行读操作的查询可以看到表的一致性快照。
Hive索引分成两类:紧凑索引和位图索引。
紧凑索引:存储每个值的HDFS块号,而不是存储文件内偏移量,存储不会占用过多的磁盘空间。
位图索引:使用压缩的位集合来高效存储具有某个特殊值的行,这种索引一般适合具有较少取值可能的列(性别或国别)。
HIVE特征:
1.可以通过Sql轻松访问数据的工具,从而实现数据仓库任务,如提取/转换 /加载(ETL),报告和数据分析;
2.可以使已经存储的数据结构化;
3.可以直接访问存储在HDFS或其他数据存储系统中的文件;
4.Hive除了支持MR计算引擎,还支持Spark和Tez这两种分布式引擎;
5.提供类似sql的查询语句HiveQL对数据进行分析处理;
6.数据存储格式有多种;
用户定义的函数(UDF),用户定义的聚合(UDAF)和用户定义的表函数(UDTF)
逗号,制表分隔值(CSV/TSV)文本文件,还有Sequence File,RC,ORC,Parquet
Metastore
metastore是Hive元数据的集中存放地。
metastore包括服务和后台数据的存储。
1.内嵌metastore配置:默认情况,metastore服务和Hive服务运行在同一个JVM,包含一个内嵌的以本地磁盘作为存储的Derby数据库实例。(意味着一次只能为每个metastore打开一个Hive会话)
2.本地metastore配置:metastore服务和Hive服务在同一个进程中,连接另外一个进程运行的数据库。
3.远程metastore配置:一个或多个metastore服务和Hive服务运行在不同的进程。
HIVE数据存储结构:
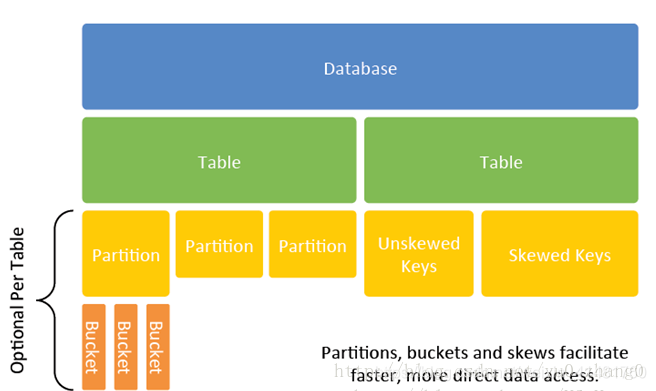
Database:HIVE有多个数据库,默认的是default,对应于HDFS目录/user/hadoop/hive/warehouse,通过hive.metastore.warehouse.dir配置;
Table:分为外表和内表,每张表对应一个目录/user/hadoop/hive/warehouse/[databasename.db]/table;
Partition:分区,每张表中可以加入一个或多个分区,方便查询,提高效率;
Bucket:
HIVE的HQL可以通过用户定义的函数(UDF),用户定义的聚合(UDAF),用户定义的表函数(UDTF)进行扩展。
当内置函数无法满足业务需求时,可以考虑UDF;
UDF(User-Defined-Function)一进一出
UDAF(User-Defined Aggregation Function)聚集函数,多进一出
UDTF(User-Defined Table-Generating Functions)一进多出
HIVE的优点
1 简单易上手
2 扩展能力好
3 统一的元数据管理 metastore包括了数据库,表,字段分区等详细信息
4 由于统一元数据管理所以和Spark等Sql引擎通用(即在拥有了统一的metastore,在hive创建一张表,在spark中能用,反之亦行)
5 使用Sql语法,提供快速开发能力,支持自定义函数UDF
6 避免了写MapReduce,减小开发人员成本
7 数据离线处理
Sql转化为MapReduce的过程
整个过程分为六个阶段:
1)Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree;
2)遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
3)遍历QueryBlock,翻译为执行操作数OperatorTree;
4)逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
5)遍历OperatorTree,翻译为MapReduce任务;
6)物理层优化器进行MapReduce任务的变换,生成最终的执行计划。
HIVE内部、外部表区别
内部表managed table,外部表external table;
内部表数据Hive管理,外部表数据HDFS管理;
内部表存储位置(默认:/user/hive/warehouse),外部表自己制定;
删除内部表会删除元数据(metastore)和存储的数据,删除外部表仅仅删除元数据;
行式数据和列式数据
行式数据在hdfs上按行进行存储,一个block存储一行或多行数据;列式数据在hdfs上按列存储,一个block有一列或多列数据。
行式数据压缩性能差,列式强于行式;因为按照行压缩,一行有多个字段,个字段数据类型不一致;
对于select id,name from table_emp;
列式数据库的效率高,因为只需要找到对应的列展现出来,查询数据量小;
行式数据库则需要遍历一整张表将每一行的id,name字段拼接展现,数据量大,效率低。
静态分区和动态分区
分区:hive是存储在hdfs上的抽象,hive的一个分区名对应hdfs上的一个目录名,子分区就是子目录名,并不是实际字段。
在表很多的情况下,查询会变得很慢,如果能将数据分区,那么就能够提高查询速度;即Partition(分区),每张表可以加入一个或多个分区,方便查询,提高效率;并且hdfs上会有对应的分区目录。
hive分区在创建表的时候用partition by关键字定义,其子句中定义的列是表中正是的列,但hive下的数据文件中并不包含这些列,因为他们是目录名,真正的数据在分区目录下。
动态分区和静态分区的区别就是动态分区不指定分区目录,由系统选择。
静态:加载数据的时候需要指定分区的值,每次插入数据都要指定分区值,创建多个分区则以逗号分开。
动态:根据查询到的数据动态的将数据分配到分区里。
动态分区功能:
hive> set hive.exec.dynamic.partition=true;
加载前设置参数:
hive (default)>set hive.exec.dynamic.partition.mode=nonstrict
1
加载:
insert into table emp_dynamic_partition partition(deptno)
select empno , ename , job , mgr , hiredate , sal , comm , deptno from emp;
删除分区:
alter table my_partition_test_table drop if exists partition(day = ‘2018-11-15’);
hive优化:
1.避免数据倾斜,找到可能产生数据倾斜的函数尤为关键,慎用count(distinct),容易产生数据倾斜。
2.设置合理的map reduce 的task数量
map阶段
调整数据最大最小分割单元大小:
mapred.min.split.size:默认1B
mapred.max.split.size:默认256MB
分区
Hive把表组织成分区。这是一种根据分区列(日期等)的值对表进行粗略划分的机制。使用分区可以加快数据分片的查询速度。
比如每条记录包含一个时间戳,我们根据日期来对它进行分区,那么同一天的记录就会被存放在同一个分区中。
优点:对于限制到某个或某些特定日期的查询,他们的处理可以变得非常高效。因为只需要扫描查询范围内分区中的文件。
同时使用分区不会影响大范围查询的执行,仍然可以查询跨多个分区的整个数据集。
一个表可以以多个维度来分区。
分区是在创建表的时候用Partitioned by子句来定义的。
CREATE TABLE logs(ts BIGINT, line STRING)
PARTITIONED BY (dt STRING, country STRING);
数据加载到分区表,需要显示指定分区值:
LOAD DATA LOCAL INPATH ‘input/hive/partitions/file1’
INTO TABLE logs
PARTITION (dt=‘2001-01-01’, country=‘GB’);
Partitioned by子句中的列定义是表中正式的列,称为分区列,但是数据文件不包含这些列的值,因为他们源于目录名。
可以在Select 语句中以通常的方法使用分区列。Hive会对输入进行修剪,从而只扫描相关的分区。
SELECT ts, dt, line
FROM logs
WHERE country=‘GB’;
桶
把表(或分区)组织成桶(bucket):
1.能够获得更高的查询处理效率。桶为表加上了额外的结构。
(例如:连接两个在(包含连接列的)相同列上划分了桶的表,可以使用map端连接(map-side join)高效地实现。)
2.能够使“取样”或者说“采样”更高效。
处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
我们使用CLUSTERED BY 子句来指定划分桶所用的列和要划分的桶的个数:
CREATE TABLE bucketed_users (id INT, name STRING)
CLUSTERED BY (id) INTO 4 BUCKETS;
Hive对值进行哈希并将结果除以桶的个数取余数来确定如何划分桶。
声明一个表使其使用排序桶:
CREATE TABLE bucketed_user (id INT, name STRING)
CLUSTERED BY (id) SORTED BY (id ASC) INTO 4 BUCKETS;
存储格式
Hive从两个维度对表的存储进行管理,分别为行格式(row format)和文件格式(file format)。
行格式指行和一行中的字段如何存储。
行格式定义由SerDe(序列化和反序列化工具)定义。
其中,反序列化用法就是查询表的时候,SerDe将把文件中字节形式的数据行反序列化为Hive内部操作数据行时所用的对象形式。序列化用法就是INSERT或者CTAS时候,表的SerDe会把Hive 的数据行内部表示形式序列化成字节形式并写到输出文件中。
文件格式指一行中字段容器的格式。
1、默认存储格式:分割的文本
如果在创建表时没有用ROW FORMAT或者STORED AS子句,那么Hive所使用的默认格式是分隔的文本,每行存储一个数据行。
默认的行内分隔符不是制表符,而是ASCII控制码集合中的Control-A(ASCII码为1),因为出现在字段文本中的可能性比较小。
集合类元素的默认分隔符为字符Control-B,用于分隔ARRAY或STRUCT或MAP的键值对中的元素。默认的映射键分隔符为字符Control-C,用于分隔MAP的键和值。表中各行之间用换行符分隔。
对于嵌套数据类型,嵌套的层次决定了使用哪种分隔符。
Hive支持8级分隔符,分别对应于ASCII编码的1,2,3……8
CREATE TABLE …
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\001’
COLLECTION ITEMS TERMINATED BY ‘\002’
MAP KEYS TERMINATED BY ‘\003’
LINES TERMINATED BY ‘\n’
STORED AS TEXTFILE;
2、二进制存储格式:顺序文件、Avro数据文件、Parquet文件、RCFile与ORCFile
二进制格式只需要通过CREATE TABLE语句中的STORED AS子句做相应声明。
二进制格式分为两大类:面向行的格式和面向列的格式。
(列格式对于那些只访问表中一小部分列的查询比较有效,行格式适合同时处理一行中很多列的情况)
Hive支持两种面向行的格式:Avro数据文件和顺序文件
Avro:
SET hive.exec.compress.output=true;
SET avro.output.codec=snappy;
CREATE TABLE … STORED AS AVRO;
顺序:
CREATE TABLE语句中的STORED AS SEQUENCEFILE子句声明,将顺序文件作为存储格式。
列式存储:Parquet、RCFile、ORCFile
3、使用定制的SerDe:RegexSerDe
CREATE TABLE stations (usaf STRING, wban STRING, name STRING)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.contrib.serde2.RegexSerDe’
WITH SERDEPROPERTIES (
“input.regex” = “(\d{6}) (\d{5}) (.{29}) .*”
);
RegexSerDe能帮助Hive获取数据,但是它的效率很低,一般不用于通用存储格式,应当考虑把数据复制为二进制存储格式。
4、存储句柄
存储句柄用户Hive自身无法访问的存储系统,比如HBase;
使用STORED BY子句指定;
代替了ROW FORMAT和STORED AS子句。

















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









