




 本文详细探讨了Hadoop的顶级项目,分析了MapReduce执行性能低的原因,介绍了MapReduce的思想及其在Hadoop生态系统中的角色。同时,深入讲解了Hive作为构建在Hadoop之上的数据仓库的功能,包括其数据存储、执行方式、运行机制,以及安装配置过程。文章还对比了Hive与传统关系型数据库的优缺点,展示了Hive的SQL查询能力,并提供了实际操作示例。
本文详细探讨了Hadoop的顶级项目,分析了MapReduce执行性能低的原因,介绍了MapReduce的思想及其在Hadoop生态系统中的角色。同时,深入讲解了Hive作为构建在Hadoop之上的数据仓库的功能,包括其数据存储、执行方式、运行机制,以及安装配置过程。文章还对比了Hive与传统关系型数据库的优缺点,展示了Hive的SQL查询能力,并提供了实际操作示例。
apache的顶级项目
【1.为什么MR的执行性能低?】
1.map和reduce以一个进程来运行的,启动和销毁进程开销大;spark是线程级别的;
2.当Map 开始产生输出时,它并不是简单的把数据写到磁盘,因为频繁的磁盘操作会导致性能严重下降。它的处理过程更复杂,数据首先是写到内存中的一个缓冲区,并做了一些预排序,以提升效率。
【2.Mapreduce的思想】
map完成之后,为了确保每个reducer的的输入都是按键排序的,系统执行排序的过程,即将map task的输出通过一定规则传给reduce task,这个过程成为shuffle。
构建在Hadoop之上的数据仓库
数据:HDFS
执行:MR(2.0 过时) 或 Spark 或 Tez
运行:YARN
hive数据存储在hdfs之上
schema:database/table/column(name/type/index)
元数据信息:描述数据的数据,schema就是元数据信息里面的东西
hive的安装步骤
1.下载
2.解压
3.把hive添加到环境变量

4. 拷贝mysql的驱动到lib下

5)hive-site.xml配置mysql相关信息
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/ruoze_d6?createDatabaseIfNotExist=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
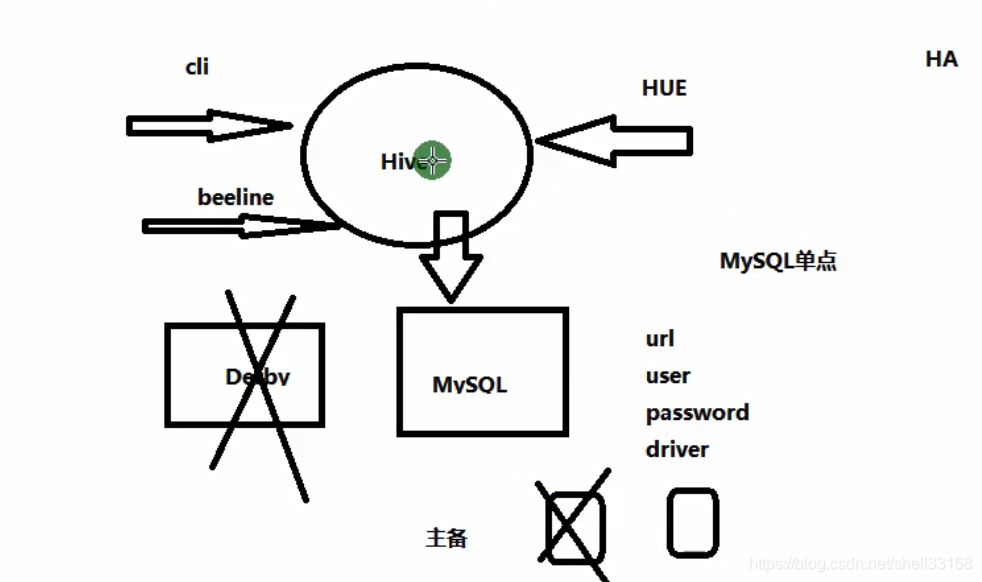
hive是一个客户端,不存在集群的概念。
【3.为什么yarn ui上看到的作业对应的队列是root.hadoop】

在hadoop的配置文件capacity-scheduler.xml里定义成了默认,root默认,机器是hadoop用户。所以是root.hadoop
Hive提供了一种类SQL的语法 Hive QL
SQL
Hive vs RDBMS(关系型数据库)
- 都是使用sql编程
- 关系型数据库查询速度快,时效性好;一个hive跑十几个小时很正常
- hive的事物鸡肋,不建议使用
hive支持insert、update操作,但是性能差
大数据不怕数据量大,就怕数据倾斜!!!
Hive实例
hive> create table d6_wc(sentence string);
OK
Time taken: 0.933 seconds
hive> select * from d6_wc;
OK
Time taken: 0.421 seconds
hive> load data local inpath '/home/hadoop/a.txt' into table d6_wc;
Loading data to table default.d6_wc
Table default.d6_wc stats: [numFiles=1, totalSize=49]
OK
Time taken: 0.524 seconds
hive> select * from d6_wc;
OK
hello world
hello yuan
hello nice
hello shanghai
Time taken: 0.096 seconds, Fetched: 4 row(s)
hive> select word,count(1) c
> from
> (select explode(split(sentence,' ')) as word from d6_wc) t
> group by word
> order by c desc;
Query ID = hadoop_20190301010202_b52ff6a4-0be3-485d-8c71-6bc9a4b6f4d7
Total jobs = 2
Launching Job 1 out of 2
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1550935198005_0003, Tracking URL = http://10-9-61-124:18088/proxy/application_1550935198005_0003/
Kill Command = /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin/hadoop job -kill job_1550935198005_0003
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-03-01 01:02:57,511 Stage-1 map = 0%, reduce = 0%
2019-03-01 01:03:02,914 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.76 sec
2019-03-01 01:03:09,246 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.11 sec
MapReduce Total cumulative CPU time: 3 seconds 110 msec
Ended Job = job_1550935198005_0003
Launching Job 2 out of 2
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1550935198005_0004, Tracking URL = http://10-9-61-124:18088/proxy/application_1550935198005_0004/
Kill Command = /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin/hadoop job -kill job_1550935198005_0004
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 1
2019-03-01 01:03:16,165 Stage-2 map = 0%, reduce = 0%
2019-03-01 01:03:21,415 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 0.91 sec
2019-03-01 01:03:27,743 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 2.65 sec
MapReduce Total cumulative CPU time: 2 seconds 650 msec
Ended Job = job_1550935198005_0004
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.11 sec HDFS Read: 6763 HDFS Write: 217 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 2.65 sec HDFS Read: 4709 HDFS Write: 41 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 760 msec
OK
hello 4
yuan 1
world 1
shanghai 1
nice 1
Time taken: 39.905 seconds, Fetched: 5 row(s)
DDL
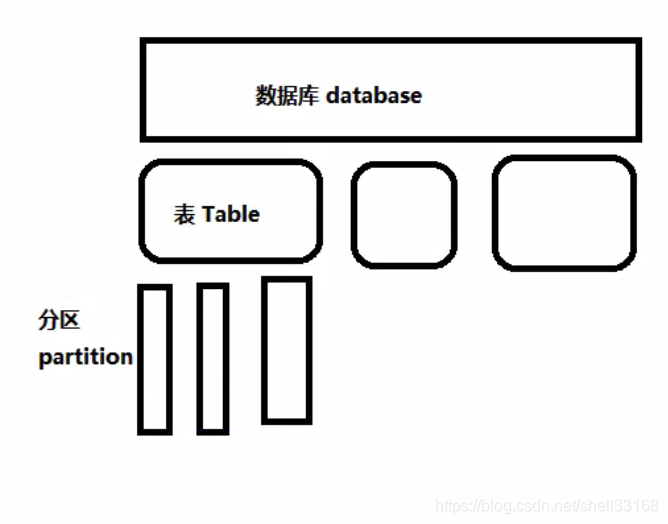
Hive: DB/table/partition,任何一次层次都是对应hdfs上的一个目录或者文件夹
DDL
create database d6;
hdfs://10-9-61-124:9000/user/hive/warehouse
hdfs://10-9-61-124:9000:hdfs目录
/user/hive/warehouse:默认的hive存储在hdfs上的目录
修改hive参数的几种形式
1) set hive.metastore.warehouse.dir;
set key 取值
set key=value 设置值
局部 单session
2)hive-site.xml
全局
创建表
create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
拷贝表结构:
CREATE TABLE emp2
LIKE emp;
拷贝表数据:
create table emp3 as select * from emp;
显示表的具体信息:
desc formatted emp3;
DML
导入数据
LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' OVERWRITE INTO TABLE emp ;
内部表,外部表
1.内部表(MANAGED):hive在hdfs中存在默认的存储路径,即default数据库。之后创建的数据库及表,如果没有指定路径应都在/user/hive/warehouse下,所以在该路径下的表为内部表。
2.外部表(EXTERNAL):指定了/user/hive/warehouse以外路径所创建的表
而内部表和外部表的主要区别就是
- 内部表:当删除内部表时,MySQL的元数据和HDFS上的普通数据都会删除 ;
- 外部表:当删除外部表时,MySQL的元数据会被删除,HDFS上的数据不会被删除;
外部表使用场景
对于一些原始日志文件,同时被多个部门同时操作的时候就需要使用外部表,如果不小心将meta data删除了,HDFS上 的data还在可以恢复,增加了数据的安全性。
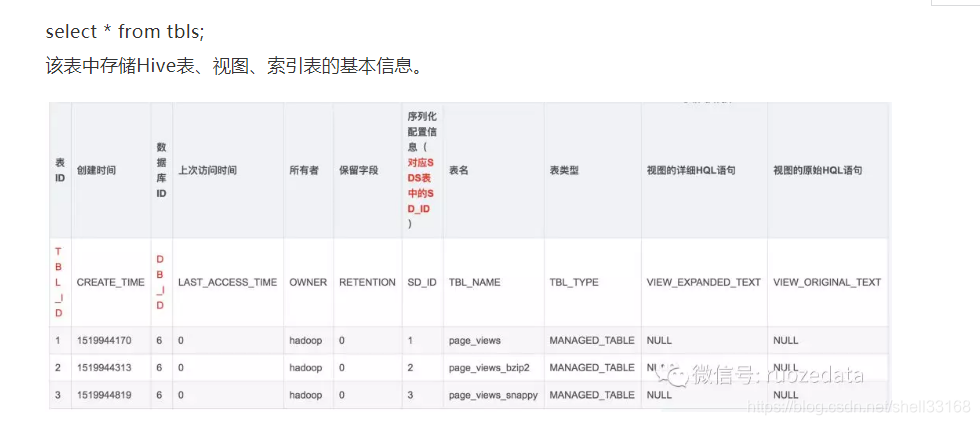
【梳理元数据信息表中的DBS和TBLS中的字段信息】


















 3620
3620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









