




 本文深入探讨最大熵模型,它在不确定性的条件下寻求概率的最优解。通过骰子投掷的例子,解释了最大熵原理,即当未知事件概率相等时,熵最大。数学上,最大熵模型与条件熵、信息增益等概念紧密相关,并通过拉格朗日乘数法求解。最终,最大熵模型导出的后验概率分布与逻辑回归的sigmoid函数一致,揭示了两者间的内在联系。
本文深入探讨最大熵模型,它在不确定性的条件下寻求概率的最优解。通过骰子投掷的例子,解释了最大熵原理,即当未知事件概率相等时,熵最大。数学上,最大熵模型与条件熵、信息增益等概念紧密相关,并通过拉格朗日乘数法求解。最终,最大熵模型导出的后验概率分布与逻辑回归的sigmoid函数一致,揭示了两者间的内在联系。
1. 思想
假设所有未知的事件出现概率都相等,在有约束的条件下求最优解。
2. 解释
在投骰子的案例中,我们知道骰子有六个面,若我们不知道骰子每个面朝上的概率,那么最安全的选择是假设每个面朝上的概率都相等,即1/6,这样保留了所有的可能性,确保了最大的不确定性。这样的原理就是最大熵原理,将该原理应用到分类得到找出最大熵模型,也是最好的分类模型。
3. 数学表达
3.1 公式
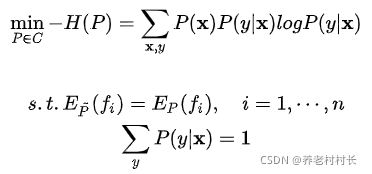
3.2 解释
3.2.1 最大熵原理
在信息论中,熵用于表示随机变量的不确定性大小,熵越大,不确定性则越大。假设离散型随机变量X的概率分布是 P(X),那么它的熵为:
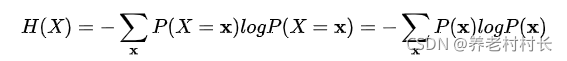
关于熵的解释可以看笔者的另一篇文章。传送门:熵和KL散度
若每个P(X)都是等可能的,即P(X) = 1/N,则此时H(X) = - logP(X)
第一个式子表示的是最小化给定X后Y的负的条件熵,换句话说,最大化条件熵。
说说条件熵。假设 Y是一个离散型随机变量,在已知 X的条件下,那么定义 Y 的条件熵为:
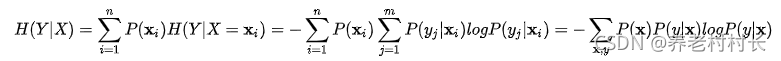
可能比较抽象,简单举个例子会容易理解些,现有X = {x1=下雨, x2=不下雨},Y = {y1=出去玩,y2=不出去玩},在已知X的条件下,Y的条件熵H(Y|X) = P(X=x1)H(Y|X=x1) + P(X=x2)H(Y|X=x2)。直观上理解这步操作将数据集划分成了两份,一份和x1有关,一份和x2有关,分别计算这两份数据集下y的熵,也就是条件熵。这点和决策树一样,决策树通过计算在已知某个特征的情况下,Y的条件熵,从而计算信息增益,进而找到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









