




简介
我们激动地推出Qwen-Image——这是一款拥有200亿参数的MMDiT图像基础模型,在复杂文本渲染和精准图像编辑领域实现重大突破。欢迎访问Qwen Chat选择"图像生成"功能体验最新模型。
核心特性包括:
- 卓越文本渲染:擅长处理多行排版、段落语义等复杂文本场景,对拼音文字(如英文)和表意文字(如中文)均能实现高保真呈现
- 连贯图像编辑:通过增强的多任务训练范式,在编辑过程中完美保持语义连贯性与视觉真实感
- 跨基准强性能:在多项公开基准测试中,该模型在各类生成与编辑任务上持续领先现有方案,确立了坚实的图像生成基础模型地位
性能表现
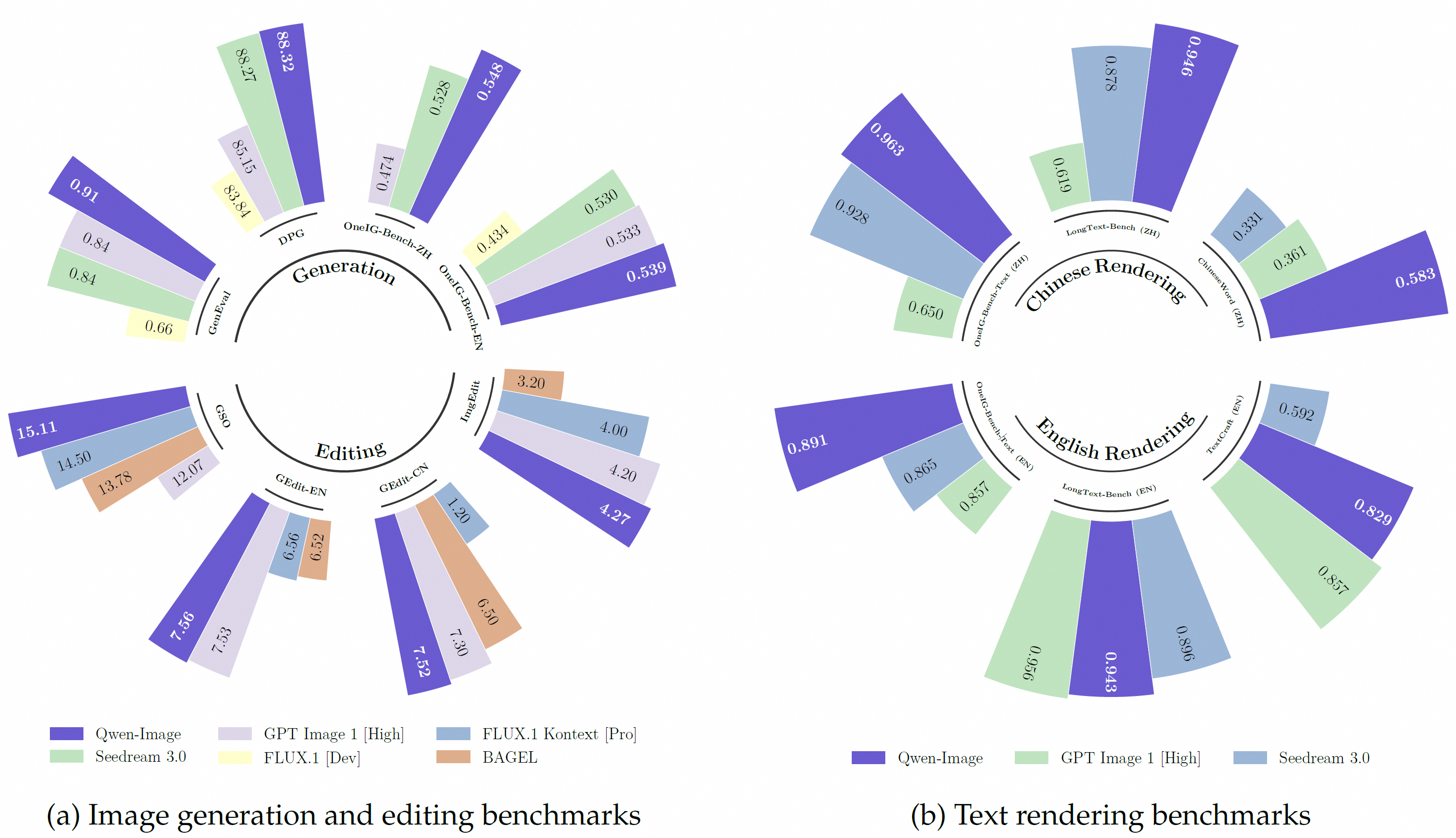
我们在多个公开基准测试中对Qwen-Image进行了全面评估,包括通用图像生成的GenEval、DPG和OneIG-Bench,以及图像编辑的GEdit、ImgEdit和GSO。Qwen-Image在所有基准测试中均取得了最先进的性能,展现了其在图像生成和编辑方面的强大能力。此外,在LongText-Bench、ChineseWord和TextCraft上的结果表明,该模型在文本渲染方面表现尤为突出——特别是在中文文本生成上——显著超越了现有的最先进模型。这凸显了Qwen-Image作为领先图像生成模型的独特地位,其兼具广泛的通用能力和卓越的文本渲染精度。
Demo
Qwen-Image的一个突出能力是能够在不同场景下实现高保真度的文本渲染。让我们来看以下中文渲染案例:
一副典雅庄重的对联悬挂于厅堂之中,房间是个安静古典的中式布置,桌子上放着一些青花瓷,对联上左书“义本生知人机同道善思新”,右书“通云赋智乾坤启数高志远”, 横批“智启通义”,字体飘逸,中间挂在一着一副中国风的画作,内容是岳阳楼。

该模型准确绘制了左右对联和横批,应用了书法效果,并精确生成了中间的岳阳楼。桌上的青花瓷也显得非常逼真。
那么,该模型在英文方面表现如何呢?我们来看一个英文渲染示例:
Bookstore window display. A sign displays “New Arrivals This Week”. Below, a shelf tag with the text “Best-Selling Novels Here”. To the side, a colorful poster advertises “Author Meet And Greet on Saturday” with a central portrait of the author. There are four books on the bookshelf, namely “The light between worlds” “When stars are scattered” “The slient patient” “The night circus”

在这个例子中,模型不仅准确地输出了“本周新书”,还准确地生成了四本书的封面文字:《世界之间的光》、《当星星散落时》、《沉默的病人》和《夜之马戏团》。
让我们来看一个更复杂的英文渲染案例:
A slide featuring artistic, decorative shapes framing neatly arranged textual information styled as an elegant infographic. At the very center, the title “Habits for Emotional Wellbeing” appears clearly, surrounded by a symmetrical floral pattern. On the left upper section, “Practice Mindfulness” appears next to a minimalist lotus flower icon, with the short sentence, “Be present, observe without judging, accept without resisting”. Next, moving downward, “Cultivate Gratitude” is written near an open hand illustration, along with the line, “Appreciate simple joys and acknowledge positivity daily”. Further down, towards bottom-left, “Stay Connected” accompanied by a minimalistic chat bubble icon reads “Build and maintain meaningful relationships to sustain emotional energy”. At bottom right corner, “Prioritize Sleep” is depicted next to a crescent moon illustration, accompanied by the text “Quality sleep benefits both body and mind”. Moving upward along the right side, “Regular Physical Activity” is near a jogging runner icon, stating: “Exercise boosts mood and relieves anxiety”. Finally, at the top right side, appears “Continuous Learning” paired with a book icon, stating “Engage in new skill and knowledge for growth”. The slide layout beautifully balances clarity and artistry, guiding the viewers naturally along each text segment.

在这种情况下,模型需要生成6个子模块,每个模块需包含图标、标题及对应介绍文字。Qwen-Image已完成布局。
小号字体效果如何?让我们测试一下:
A man in a suit is standing in front of the window, looking at the bright moon outside the window. The man is holding a yellowed paper with handwritten words on it: “A lantern moon climbs through the silver night, Unfurling quiet dreams across the sky, Each star a whispered promise wrapped in light, That dawn will bloom, though darkness wanders by.” There is a cute cat on the windowsill.

在这种情况下,纸张仅占整个图像的不到十分之一,且文本段落相对较长,但模型仍能准确生成纸张上的文字内容。
如果文字数量更多呢?让我们尝试一个更具挑战性的案例:
一个穿着"QWEN"标志的T恤的中国美女正拿着黑色的马克笔面相镜头微笑。她身后的玻璃板上手写体写着 “一、Qwen-Image的技术路线: 探索视觉生成基础模型的极限,开创理解与生成一体化的未来。二、Qwen-Image的模型特色:1、复杂文字渲染。支持中英渲染、自动布局; 2、精准图像编辑。支持文字编辑、物体增减、风格变换。三、Qwen-Image的未来愿景:赋能专业内容创作、助力生成式AI发展。”

你可以看到模型在玻璃板上完全生成了一段完整的手写段落。
如果是双语呢?针对同样的场景,让我们试试这个提示:
一个穿着"QWEN"标志的T恤的中国美女正拿着黑色的马克笔面相镜头微笑。她身后的玻璃板上手写体写着 “Meet Qwen-Image – a powerful image foundation model capable of complex text rendering and precise image editing. 欢迎了解Qwen-Image, 一款强大的图像基础模型,擅长复杂文本渲染与精准图像编辑”

如你所见,该模型在呈现文本时可以随时切换两种语言。
Qwen-Image的文本能力使其可以轻松制作海报,例如:
A movie poster. The first row is the movie title, which reads “Imagination Unleashed”. The second row is the movie subtitle, which reads “Enter a world beyond your imagination”. The third row reads “Cast: Qwen-Image”. The fourth row reads “Director: The Collective Imagination of Humanity”. The central visual features a sleek, futuristic computer from which radiant colors, whimsical creatures, and dynamic, swirling patterns explosively emerge, filling the composition with energy, motion, and surreal creativity. The background transitions from dark, cosmic tones into a luminous, dreamlike expanse, evoking a digital fantasy realm. At the bottom edge, the text “Launching in the Cloud, August 2025” appears in bold, modern sans-serif font with a glowing, slightly transparent effect, evoking a high-tech, cinematic aesthetic. The overall style blends sci-fi surrealism with graphic design flair—sharp contrasts, vivid color grading, and layered visual depth—reminiscent of visionary concept art and digital matte painting, 32K resolution, ultra-detailed.

事实上,除了文本处理外,通义千问-图像模型在通用图像生成方面同样表现出色,支持多种艺术风格。从写实场景到印象派绘画,从动漫风格到极简设计,该模型能灵活响应多样化的创作指令,成为艺术家、设计师和故事创作者的多功能工具。我们将在技术报告中对此进行详细阐述。

在图像编辑方面,Qwen-Image支持多种操作,包括风格迁移、增删内容、细节增强、文字编辑和人物姿态调整。这使得普通用户也能轻松实现专业级的图像编辑效果。我们将在技术报告中对此进行详细说明。

代码上手
Diffusers
安装最新版本的diffusers
pip install git+https://github.com/huggingface/diffusers
以下代码片段展示了如何使用该模型根据文本提示生成图像:
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
# Load the pipeline
if torch.cuda.is_available():
torch_dtype = torch.bfloat16
device = "cuda"
else:
torch_dtype = torch.float32
device = "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
positive_magic = [
"en": "Ultra HD, 4K, cinematic composition." # for english prompt,
"zh": "超清,4K,电影级构图" # for chinese prompt,
]
# Generate image
prompt = '''A coffee shop entrance features a chalkboard sign reading "Qwen Coffee 😊 $2 per cup," with a neon light beside it displaying "通义千问". Next to it hangs a poster showing a beautiful Chinese woman, and beneath the poster is written "π≈3.1415926-53589793-23846264-33832795-02384197". Ultra HD, 4K, cinematic composition'''
negative_prompt = " "
# Generate with different aspect ratios
aspect_ratios = {
"1:1": (1328, 1328),
"16:9": (1664, 928),
"9:16": (928, 1664),
"4:3": (1472, 1140),
"3:4": (1140, 1472)
}
width, height = aspect_ratios["16:9"]
image = pipe(
prompt=prompt + positive_magic["en"],
negative_prompt=negative_prompt,
width=width,
height=height,
num_inference_steps=50,
true_cfg_scale=4.0,
generator=torch.Generator(device="cuda").manual_seed(42)
).images[0]
image.save("example.png")
DiffSynth-Studio
安装依赖包
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .
以下代码片段展示了如何使用该模型根据文本提示生成图像:
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="transformer/diffusion_pytorch_model*.safetensors"),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors"),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors"),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
)
prompt = "精致肖像,水下少女,蓝裙飘逸,发丝轻扬,光影透澈,气泡环绕,面容恬静,细节精致,梦幻唯美。"
image = pipe(prompt, seed=0, num_inference_steps=40)
image.save("image.jpg")
Qwen-Image-Distill-Full
from diffsynth.pipelines.qwen_image import QwenImagePipeline, ModelConfig
import torch
pipe = QwenImagePipeline.from_pretrained(
torch_dtype=torch.bfloat16,
device="cuda",
model_configs=[
ModelConfig(model_id="DiffSynth-Studio/Qwen-Image-Distill-Full", origin_file_pattern="diffusion_pytorch_model*.safetensors"),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="text_encoder/model*.safetensors"),
ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="vae/diffusion_pytorch_model.safetensors"),
],
tokenizer_config=ModelConfig(model_id="Qwen/Qwen-Image", origin_file_pattern="tokenizer/"),
)
prompt = "精致肖像,水下少女,蓝裙飘逸,发丝轻扬,光影透澈,气泡环绕,面容恬静,细节精致,梦幻唯美。"
image = pipe(prompt, seed=0, num_inference_steps=15, cfg_scale=1)
image.save("image.jpg")
总之,我们希望Qwen-Image能进一步推动图像生成技术的发展,降低视觉内容创作的技术门槛,激发更多创新应用。同时,我们也期待社区的积极参与和反馈,共同构建开放、透明、可持续的生成式AI生态系统。


















 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









