







艾伦人工智能研究所(Ai2)最近发布了一个名为 OLMo 2 32B Instruct 的新语言模型,它是 OLMo-2 32B March 2025 模型的后训练变体。该模型已在聊天、数学、GSM8K 和 IFEval 等多种任务中进行了微调,是适用于各种应用的通用工具。

模型说明
OLMo 2 32B Instruct 是一个混合了公开数据集、合成数据集和人工创建数据集的训练模型。它主要针对英语语言而设计,采用 Apache 2.0 许可。该模型在 allenai/OLMo-2-0325-32B-DPO 模型的基础上进行了微调,而 allenai/OLMo-2-0325-32B-DPO 模型本身是在 Dolma 数据集上预先训练的。
安装和使用
要使用 OLMo 2 32B Instruct,需要使用以下命令从主分支安装最新版本的 Transformers:
pip install --upgrade git+https://github.com/huggingface/transformers.git
安装完成后,您可以使用以下代码段用 HuggingFace 加载模型:
from transformers import AutoModelForCausalLM
olmo_model = AutoModelForCausalLM.from_pretrained(allenai/OLMo-2-0325-32B-Instruct)
聊天模板和系统提示
OLMo 2 32B Instruct 的聊天模板与以前的 OLMo 2 和 Tülu 3 型号略有不同。它在其余部分之前没有 bos 标记,Ai2 演示中使用的默认系统提示是
You are OLMo 2, a helpful and harmless AI Assistant built by the Allen Institute for AI.
中间检查点
为了促进对 RL 微调的研究,Ai2 在模型的 RLVR 训练过程中发布了中间检查点。这些检查点每 20 个训练步骤保存一次,可在 HuggingFace 存储库的修订版中访问。
偏差、风险和限制
与任何语言模型一样,OLMo 2 32B Instruct 在用户提示时可能会生成有害和敏感的内容。在应用这项技术时,必须考虑到风险,因为模型中的许多语句可能是不准确的。
性能
OLMo 2 32B Instruct 在各种任务中都表现出令人印象深刻的性能。它在平均指标上获得了 68.8 分,在 AlpacaEval 2 LC 上获得了 42.8 分,在 BBH 上获得了 70.6 分,在 DROP 上获得了 78.0 分,在 GSM8k 上获得了 87.6 分,在 IFEval 上获得了 85.6 分,在 MATH 上获得了 49.7 分,在 MMLU 上获得了 77.3 分,在 Safety 上获得了 85.9 分,在 PopQA 上获得了 37.5 分,在 TruthQA 上获得了 73.2 分。
| Model | Average | AlpacaEval 2 LC | BBH | DROP | GSM8k | IFEval | MATH | MMLU | Safety | PopQA | TruthQA |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Closed API models | |||||||||||
| GPT-3.5 Turbo 0125 | 59.6 | 38.7 | 66.6 | 70.2 | 74.3 | 66.9 | 41.2 | 70.2 | 69.1 | 45.0 | 62.9 |
| GPT 4o Mini 2024-07-18 | 65.7 | 49.7 | 65.9 | 36.3 | 83.0 | 83.5 | 67.9 | 82.2 | 84.9 | 39.0 | 64.8 |
| Open weights models | |||||||||||
| Mistral-Nemo-Instruct-2407 | 50.9 | 45.8 | 54.6 | 23.6 | 81.4 | 64.5 | 31.9 | 70.0 | 52.7 | 26.9 | 57.7 |
| Ministral-8B-Instruct | 52.1 | 31.4 | 56.2 | 56.2 | 80.0 | 56.4 | 40.0 | 68.5 | 56.2 | 20.2 | 55.5 |
| Gemma-2-27b-it | 61.3 | 49.0 | 72.7 | 67.5 | 80.7 | 63.2 | 35.1 | 70.7 | 75.9 | 33.9 | 64.6 |
| Qwen2.5-32B | 66.5 | 39.1 | 82.3 | 48.3 | 87.5 | 82.4 | 77.9 | 84.7 | 82.4 | 26.1 | 70.6 |
| Mistral-Small-24B | 67.6 | 43.2 | 80.1 | 78.5 | 87.2 | 77.3 | 65.9 | 83.7 | 66.5 | 24.4 | 68.1 |
| Llama-3.1-70B | 70.0 | 32.9 | 83.0 | 77.0 | 94.5 | 88.0 | 56.2 | 85.2 | 76.4 | 46.5 | 66.8 |
| Llama-3.3-70B | 73.0 | 36.5 | 85.8 | 78.0 | 93.6 | 90.8 | 71.8 | 85.9 | 70.4 | 48.2 | 66.1 |
| Gemma-3-27b-it | - | 63.4 | 83.7 | 69.2 | 91.1 | - | - | 81.8 | - | 30.9 | - |
| Fully open models | |||||||||||
| OLMo-2-7B-1124-Instruct | 55.7 | 31.0 | 48.5 | 58.9 | 85.2 | 75.6 | 31.3 | 63.9 | 81.2 | 24.6 | 56.3 |
| OLMo-2-13B-1124-Instruct | 61.4 | 37.5 | 58.4 | 72.1 | 87.4 | 80.4 | 39.7 | 68.6 | 77.5 | 28.8 | 63.9 |
| OLMo-2-32B-0325-SFT | 61.7 | 16.9 | 69.7 | 77.2 | 78.4 | 72.4 | 35.9 | 76.1 | 93.8 | 35.4 | 61.3 |
| OLMo-2-32B-0325-DPO | 68.8 | 44.1 | 70.2 | 77.5 | 85.7 | 83.8 | 46.8 | 78.0 | 91.9 | 36.4 | 73.5 |
| OLMo-2-32B-0325-Instruct | 68.8 | 42.8 | 70.6 | 78.0 | 87.6 | 85.6 | 49.7 | 77.3 | 85.9 | 37.5 | 73.2 |
学习曲线
OLMo 2 32B Instruct 的训练曲线展示了其随时间推移的学习进度。该模型使用 5 个 8xH100 节点进行训练,学习曲线可在模型库中找到。

以下是 allenai/OLMo-2-0325-32B-Instruct 各步的核心评估分数(注意,我们将第 320 步作为最终检查点,对应第 573,440 集):
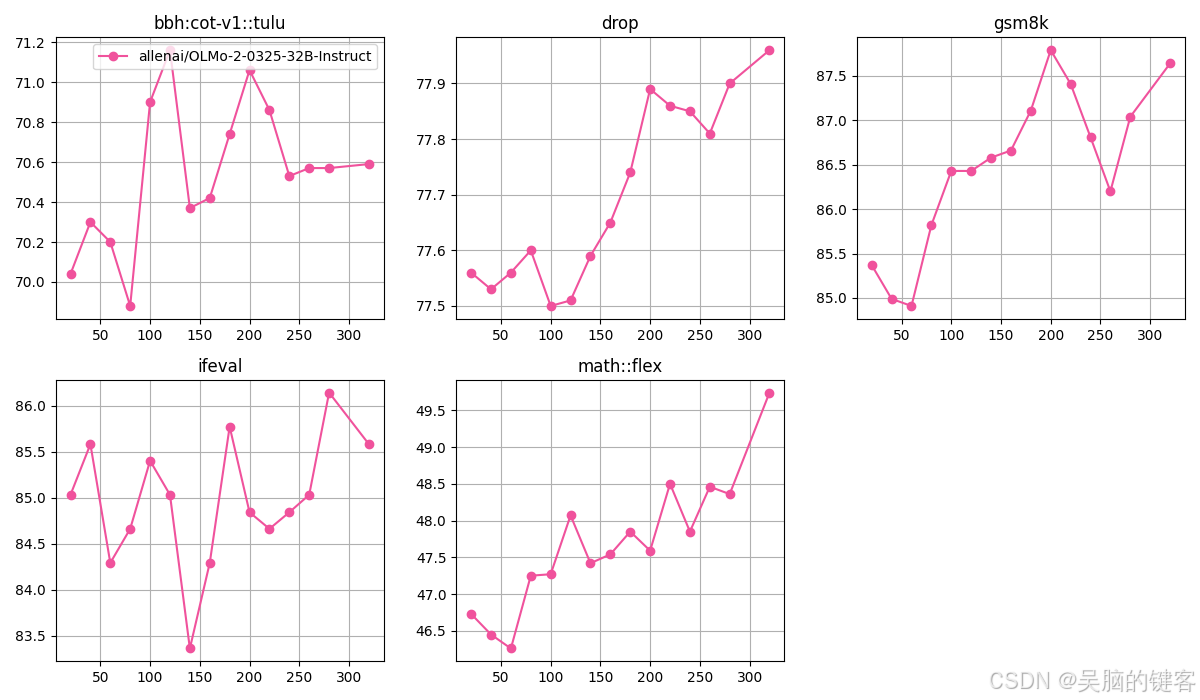
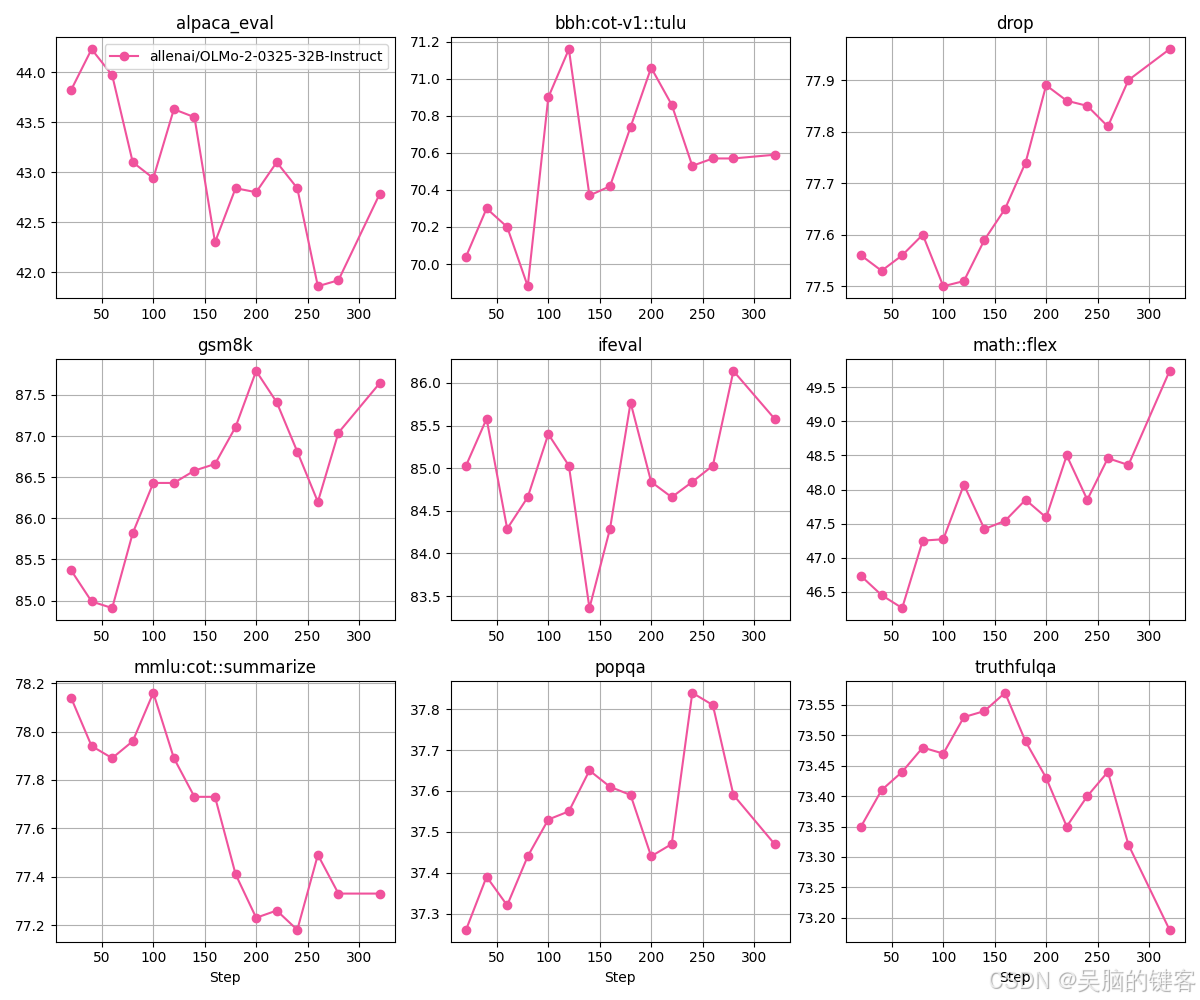
以下是 allenai/OLMo-2-0325-32B-Instruct 的其他评估分数:
复制命令
模型库中提供了 OLMo 2 32B Instruct 的复制命令,研究人员可以复制训练过程。
# clone and check out commit
git clone https://github.com/allenai/open-instruct.git
# this should be the correct commit, the main thing is to have the vllm monkey patch for
# 32b olmo https://github.com/allenai/open-instruct/blob/894ffa236319bc6c26c346240a7e4ee04ba0bd31/open_instruct/vllm_utils2.py#L37-L59
git checkout a51dc98525eec01de6e8a24c071f42dce407d738
uv sync
uv sync --extra compile
# note that you may need 5 8xH100 nodes for the training.
# so please setup ray properly, e.g., https://github.com/allenai/open-instruct/blob/main/docs/tulu3.md#llama-31-tulu-3-70b-reproduction
python open_instruct/grpo_vllm_thread_ray_gtrl.py \
--exp_name 0310_olmo2_32b_grpo_12818 \
--beta 0.01 \
--local_mini_batch_size 32 \
--number_samples_per_prompt 16 \
--output_dir output \
--local_rollout_batch_size 4 \
--kl_estimator kl3 \
--learning_rate 5e-7 \
--dataset_mixer_list allenai/RLVR-GSM-MATH-IF-Mixed-Constraints 1.0 \
--dataset_mixer_list_splits train \
--dataset_mixer_eval_list allenai/RLVR-GSM-MATH-IF-Mixed-Constraints 16 \
--dataset_mixer_eval_list_splits train \
--max_token_length 2048 \
--max_prompt_token_length 2048 \
--response_length 2048 \
--model_name_or_path allenai/OLMo-2-0325-32B-DPO \
--non_stop_penalty \
--stop_token eos \
--temperature 1.0 \
--ground_truths_key ground_truth \
--chat_template_name tulu \
--sft_messages_key messages \
--eval_max_length 4096 \
--total_episodes 10000000 \
--penalty_reward_value 0.0 \
--deepspeed_stage 3 \
--no_gather_whole_model \
--per_device_train_batch_size 2 \
--local_rollout_forward_batch_size 2 \
--actor_num_gpus_per_node 8 8 8 4 \
--num_epochs 1 \
--vllm_tensor_parallel_size 1 \
--vllm_num_engines 12 \
--lr_scheduler_type constant \
--apply_verifiable_reward true \
--seed 1 \
--num_evals 30 \
--save_freq 20 \
--reward_model_multiplier 0.0 \
--no_try_launch_beaker_eval_jobs \
--try_launch_beaker_eval_jobs_on_weka \
--gradient_checkpointing \
--with_tracking
License and Use
OLMo 2 32B Instruct 采用 Apache 2.0 许可协议,用于研究和教育用途。该软件使用第三方模型生成的输出数据集进行了微调,这些输出数据集受附加条款约束。
结论
OLMo 2 32B Instruct 是一个功能强大的语言模型,针对各种任务进行了微调。它的性能、多功能性和开源性使其成为研究人员和开发人员开发基于语言的应用程序的宝贵资源。该模型的中间检查点、学习曲线和重现命令为进一步探索和实验提供了额外的工具。与任何语言模型一样,在使用 OLMo 2 32B Instruct 时必须考虑风险和局限性,尤其是生成有害或敏感内容方面。
https://huggingface.co/allenai/OLMo-2-0325-32B-Instruct


















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









