








 本文介绍了一种基于深度学习的人再识别(re-ID)方法——DeepMetricLearning(DML),它结合了特征提取与度量学习,实现了端到端的学习过程。DML使用SCNN网络并采用cosine距离度量,能有效应对不同视角下的行人识别挑战。此外,文章还探讨了跨数据集模型的泛化能力。
本文介绍了一种基于深度学习的人再识别(re-ID)方法——DeepMetricLearning(DML),它结合了特征提取与度量学习,实现了端到端的学习过程。DML使用SCNN网络并采用cosine距离度量,能有效应对不同视角下的行人识别挑战。此外,文章还探讨了跨数据集模型的泛化能力。
- 也是最早用深度学习方法做Re-ID的工作
- 对跨数据集模型的泛化性能进行了实验
Motivation
- 传统方法通常都是将特征提取与度量学习分开处理的,end-to-end的深度学习在计算视觉各个领域都取得了较大的成功,那么能不能在Re-ID上用一个统一的框架来联合进行特征提取与度量学习呢?
Contribution
- 提出了”Deep Metric Learning”(DML)方法来进行re-ID:SCNN+ cosine distance,该方法有三个优势:
- end to end学习
- multi-channel filters来捕捉各种特征,比传统方法的简单的融合更加合理(前两点感觉都是深度学习的基本操作0.0)
- 通过是否共享SCNN的参数来切换视角确定与更一般性的re—ID的任务
- 第一次严格意义上进行了跨数据集的实验,在CUHK Campus数据集上进行模型的训练,在VIPeR数据集上进行了测试,这种实验更符合实际场景
1.Introduction
- re-ID的定义以及应用场景:
- cross camera tracking
- behaviour analysis
- object retrieval等等
- 研究的重点:
- Featrue extraction
- Metric Learning
- 动机与贡献:见上文
2.Related Work
- featrue representation
- 各种特征:
- HSV color histogram
- LAB color histogram
- SIFT
- LBP histogram
- Gabor features
- 上述 特征的融合
- 利用人结构的轮廓与对称性:在预先定义的网格以及精细的局部区域提取颜色和纹理信息
- color invariant signature
- salience matching
- 以后肯定的方向:精度的身体部分分割、行人对齐、姿势归一化
- 各种特征:
- Metric Learning
- 相比标准的距离度量(L1,L2),学习到的度量对Re-ID来说可以得到更具判别力的特征,并且对于跨视角的人物图像变化更加鲁棒
- 度量的趋势:从整体->分区域
- siamese neural network
- 最早在1993年用在签名认证
- 优点:
- 统一端到端框架且目标明确
- 自动学习到最优的度量
- 最后一层一般是用来衡量相似性:
- L1、L2、cosine (cosine对样本的大小具有不变性)
3. Deep Metric Learning
- 因为分辨率、光照、姿势的变化的影响,两个人的相似性是十分难以度量的,理想的度量可能需要具有很高的非线性–>Deep Learning是一个很有效的学习非线性的工具
A.Architecture
- Re-ID因为训练集与测试集label是不一样的,不能直接用传统神经网络的sample–> label模式,本文采用siamese network转换成sample pair –> label
- 本文的方法将输入图片对分成三个重叠部分,每个对应的部分由三个SCNN来匹配,最后预测+1对应同一个人,-1不同人,具体流程如下图:

- 因为在probe过程中需要比较相似性,本文最后的输出为a similarity score,网络的结构如下图:
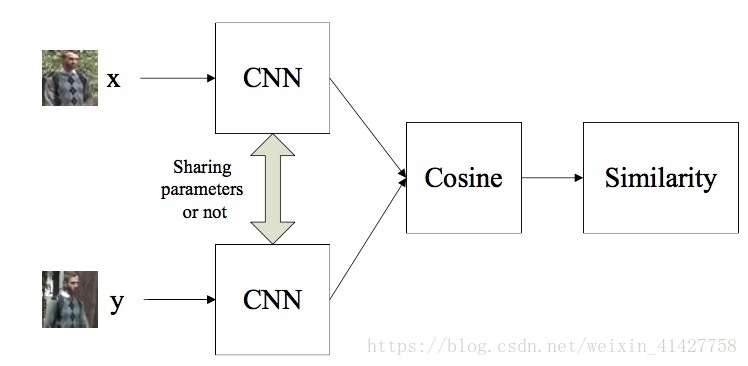
相似性计算:
s=B1(x)TB2(y)B1(x)TB1(x)B2(y)TB2(y)‾‾‾‾‾‾‾‾‾‾‾√‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√ s = B 1 ( x ) T B 2 ( y ) B 1 ( x ) T B 1 ( x ) B 2 ( y ) T B 2 ( y )本文的网络有共享SCNN权重与不共享两种模式:
- 权重共享更适合一般性的任务
- 权重不共享可以更自然的处理特定视角的匹配任务(不同参数的CNN对不同的视角下的特征进行处理)
B. Convolutional Neural Network
- 本文的CNN由2个卷积层、2个池化层、1个全连接层组成,具体结构如下图:
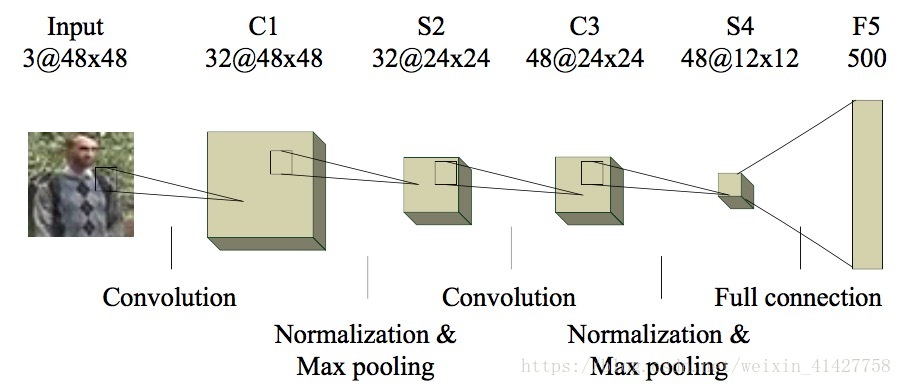
- 每层pooling layer包含一个cross channel normalization unit
- 在卷积前对数据进行了0填充,保证输入输出大小相同,C1为7x7, C2为5x5,激活函数使用的relu
C. Cost Function and Learning
- 三个候选的损失函数,均方损失、指数损失、二项偏差:
Jsquare=(s−l)2,Jexp=e−sl,Jdev=ln(e−2sl+1) J s q u a r e = ( s − l ) 2 , J e x p = e − s l , J d e v = l n ( e − 2 s l + 1 )
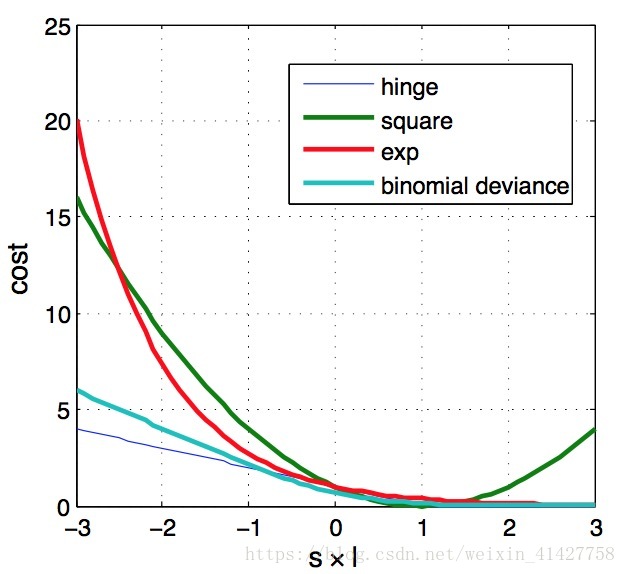
- 如图,hinge cost是作者作为参考,当cosine输出为1(-1),label为1(-1)时,损失为0,文中说当符号不相同时,指数损失有最大的loss,应该是只比了sl
- 同时从图中可以看出Deviance loss与hinge loss很像,而Hing loss对异常点很鲁棒,但在sl=1处不可导,所以选择Deviance代替。
- 问题:对于re-ID任务什么算异常值呢?
- BP的推导:
Jdev=ln(e−2Cosine(B1(x),B2(y))l+1).∂Jdev∂x=−2le−2Cosine(B1(x),B2(y))le−2Cosine(B1(x),B2(y))l+1⋅1‖B1(x)‖‖B2(y)⋅(B2(y)−B1(x)TB2(y)B1(x)B1(x)TB1(x)⋅dB1dx,∂Jdev∂y=−2le−2Cosine(B1(x),B2(y))le−2Cosine(B1(x),B2(y))l+1⋅1‖B1(x)‖‖B2(y)⋅(B1(x)−B2(y)TB1(x)B2(y)B2(y)TB2(y)⋅dB2dy
J
d
e
v
=
l
n
(
e
−
2
C
o
s
i
n
e
(
B
1
(
x
)
,
B
2
(
y
)
)
l
+
1
)
.
∂
J
d
e
v
∂
x
=
−
2
l
e
−
2
C
o
s
i
n
e
(
B
1
(
x
)
,
B
2
(
y
)
)
l
e
−
2
C
o
s
i
n
e
(
B
1
(
x
)
,
B
2
(
y
)
)
l
+
1
⋅
1
‖
B
1
(
x
)
‖
‖
B
2
(
y
)
⋅
(
B
2
(
y
)
−
B
1
(
x
)
T
B
2
(
y
)
B
1
(
x
)
B
1
(
x
)
T
B
1
(
x
)
⋅
d
B
1
d
x
,
∂
J
d
e
v
∂
y
=
−
2
l
e
−
2
C
o
s
i
n
e
(
B
1
(
x
)
,
B
2
(
y
)
)
l
e
−
2
C
o
s
i
n
e
(
B
1
(
x
)
,
B
2
(
y
)
)
l
+
1
⋅
1
‖
B
1
(
x
)
‖
‖
B
2
(
y
)
⋅
(
B
1
(
x
)
−
B
2
(
y
)
T
B
1
(
x
)
B
2
(
y
)
B
2
(
y
)
T
B
2
(
y
)
⋅
d
B
2
d
y
- 训练的batch size:128
- 64 positive 64 negative
- 将多分类转换为二分类后,负样本的数量远大于正样本,本文每个batch随机从整个负样本池中选择(是不是考虑困难样本更好)
4. Experiment
- 两种实验方式:
- 训练、测试都在VIPeR,使用了view specific SCNN(即不共享网络参数)
- 在CUHK Campus上训练,在VIPeR上测试,使用general SCNN (即共享网络参数)
A. Single Database Person Re-Identification
VIPeR共632个人,每个人两张照片来自两个不同的录像机,随机分了316个作为训练,316个作为测试,重复了11次,第一次用来调整参数,后10次用来得到结果
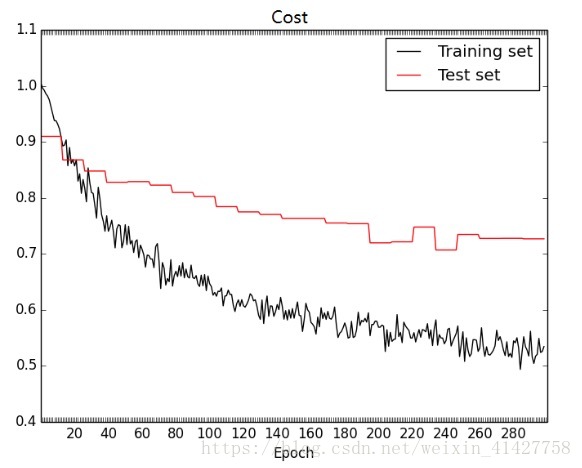
1) The Number of Epoch:结果如下图:
- 2)Asymetric Cost:因为负样本远大于正样本的数量,在训练过程中随机选取来组成batch可能会导致negative pairs under-fitting –> asymmetric costs
- 固定正样本对l为1,负样本对l值取c从0.25到4,如下式子,
l={1−cfor positive pairfor negative pair l = { 1 for positive pair − c for negative pair - c的选取实验结果如下表:当c=2时得到最好的性能,说明负样本应该得到更多的注意:
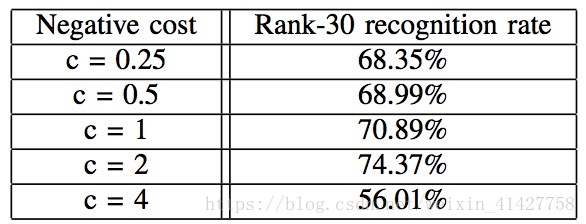
- 固定正样本对l为1,负样本对l值取c从0.25到4,如下式子,
- 3)results:
- 在epoch=300,c=2下,对于三个身体部分相似性得分进行了加和(这里是不是加权更好?),结果比较如下:
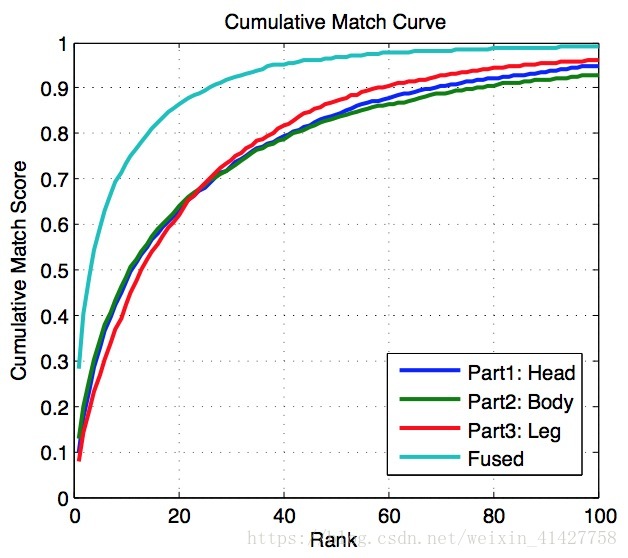
- 学习得到网络前两层卷积核可视化如下:

- 在epoch=300,c=2下,对于三个身体部分相似性得分进行了加和(这里是不是加权更好?),结果比较如下:
B. Cross Database Person Re-Identification
- 在CUHK Campus数据集上进行训练,在VIPer上进行测试,对算法的泛化性能有较高的要求,实验选择了共享参数的SCNN
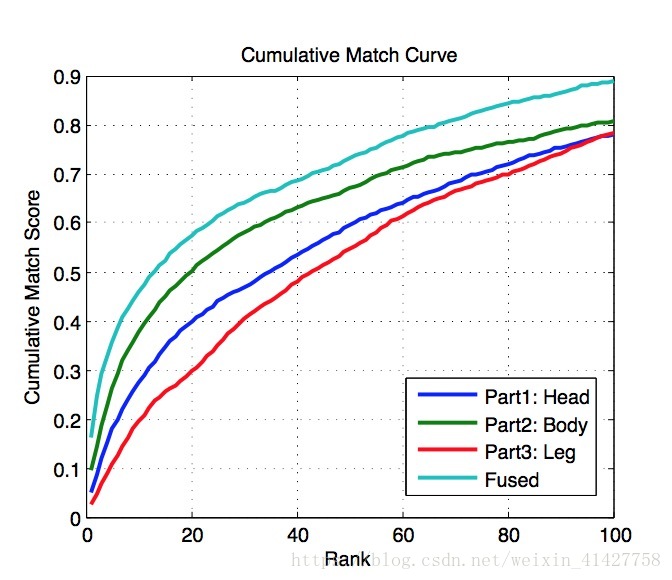
- 下图是一些实验结果:
- 不同部分以及融合后的的rank curve ,可以看出Body具有最高的判别力,三个融合后有一定提升 问题:为什么在VIPeR上效果三个部分差异很小,是数据集太小了么?
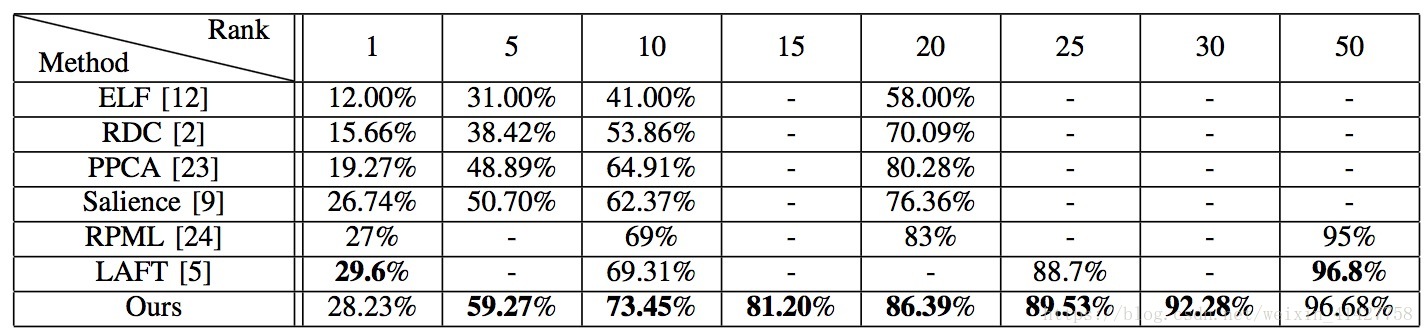
- 识别结果如下表:

- 在CUHK上训练网络卷积核可视化结果如下图,因为CUHK图片相比VIPeR有更丰富的纹理与较高的质量,可视化的卷积核有更清晰的结构。而VIPeR中的filers在颜色上有较高的对比度,可能因为不同的摄像机环境

- 不同部分以及融合后的的rank curve ,可以看出Body具有最高的判别力,三个融合后有一定提升 问题:为什么在VIPeR上效果三个部分差异很小,是数据集太小了么?
Conclusions
- 总结了本文的贡献
- 第一个将深度学习应用在re-ID问题的工作,同时也是第一个研究跨数据集re-ID问题的工作
- 未来工作:
- 将DML应用到更多的应用
- 探索pre-trained model
- 研究dropout在应用的作用
- 继续研究如何在跨数据集下得到更加泛化的模型

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









