




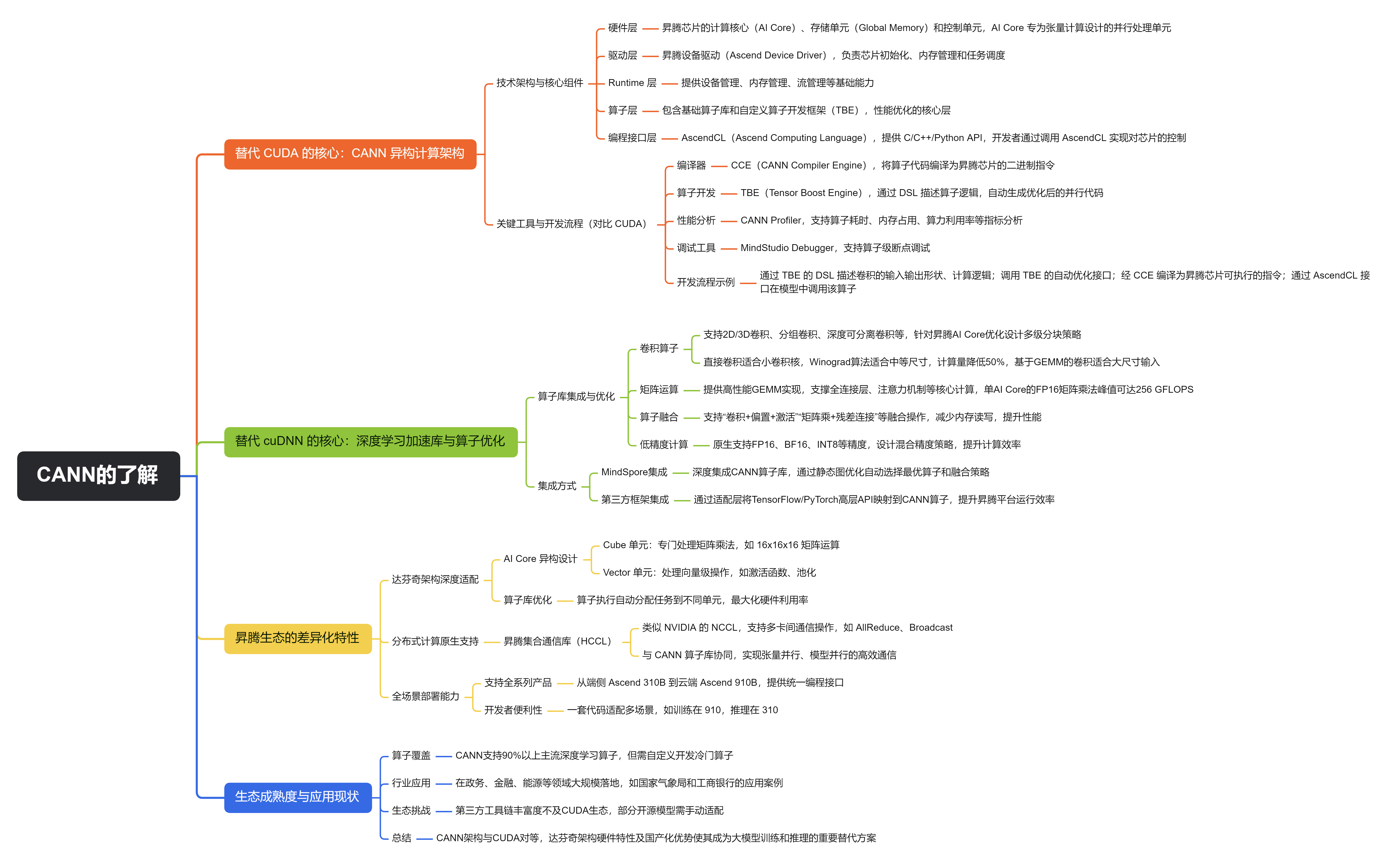
华为针对昇腾(Ascend)系列 AI 芯片构建了完整的软硬件生态,其核心技术栈在功能上对应 NVIDIA 的 CUDA 和 cuDNN,但在架构设计和优化方向上有显著的国产化特色。以下从技术细节、核心组件、算子优化等方面详细解析:
一、替代 CUDA 的核心:CANN 异构计算架构
CANN(Compute Architecture for Neural Networks) 是华为昇腾生态的底层基石,定位与 NVIDIA CUDA 一致 —— 为开发者提供高效利用昇腾芯片算力的编程接口和工具链,但针对昇腾芯片的 “达芬奇架构” 做了深度定制。
1. 技术架构与核心组件
CANN 采用 “分层设计”,从底层硬件到上层应用形成完整链路:
- 硬件层:昇腾芯片(如 Ascend 910/310)的计算核心(AI Core)、存储单元(Global Memory)和控制单元,其中 AI Core 是专为张量计算设计的并行处理单元(类似 NVIDIA 的 CUDA Core/Tensor Core)。
- 驱动层:昇腾设备驱动(Ascend Device Driver),负责芯片初始化、内存管理和任务调度,类似 NVIDIA 的 GPU 驱动。
- Runtime 层 :提供设备管理(如芯片初始化、上下文创建)、内存管理(全局内存 / 共享内存分配)、流管理(Stream,类似 CUDA Stream 的异步任务队列)等基础能力。
- 算子层:包含基础算子库(如矩阵运算、卷积)和自定义算子开发框架(TBE),是性能优化的核心层。
- 编程接口层:AscendCL(Ascend Computing Language),提供 C/C++/Python API,开发者通过调用 AscendCL 实现对芯片的控制,类似 CUDA Runtime API。
2. 关键工具与开发流程(对比 CUDA)
| 功能 | NVIDIA CUDA | 华为 CANN |
|---|---|---|
| 编译器 | nvcc(将 CUDA 代码编译为 PTX 指令) | CCE(CANN Compiler Engine),将算子代码编译为昇腾芯片的二进制指令 |
| 算子开发 | CUDA Kernel(手动编写并行代码) | TBE(Tensor Boost Engine),通过 DSL(领域专用语言)描述算子逻辑,自动生成优化后的并行代码 |
| 性能分析 | nvprof/nsight-systems | CANN Profiler,支持算子耗时、内存占用、算力利用率等指标分析 |
| 调试工具 | cuda-gdb | MindStudio Debugger,支持算子级断点调试 |
开发流程示例:用 TBE 开发自定义卷积算子
- 通过 TBE 的 DSL 描述卷积的输入输出形状、计算逻辑(如滑动窗口、权值乘加);
- 调用 TBE 的自动优化接口(如自动分块、内存复用);
- 经 CCE 编译为昇腾芯片可执行的指令;
- 通过 AscendCL 接口在模型中调用该算子。
二、替代 cuDNN 的核心:深度学习加速库与算子优化
华为未推出单独命名为 “cuDNN” 的产品,但在 CANN 中集成了深度学习专用加速算子库,并通过 MindSpore 框架实现了类似 cuDNN 的自动优化能力,核心针对神经网络的关键运算做了硬件级优化。
1. 算子库覆盖与优化方向(对比 cuDNN)
-
卷积算子:
支持 2D/3D 卷积、分组卷积、深度可分离卷积等,针对昇腾 AI Core 的计算特性(如 16x16 矩阵计算单元)设计了多级分块策略(Tile 级、Cube 级),并提供多种算法选择:- 直接卷积:适合小卷积核(如 3x3);
- Winograd 算法:适合中等尺寸(如 7x7),计算量降低 50%;
- 基于 GEMM 的卷积:通过 im2col 将卷积转换为矩阵乘法,适合大尺寸输入。
(类似 cuDNN 的卷积算法自适应,但针对达芬奇架构做了更细粒度的优化)
-
矩阵运算:
提供高性能 GEMM(General Matrix Multiplication)实现,支撑全连接层、注意力机制等核心计算。通过 “矩阵分块 + 流水线执行” 充分利用 AI Core 的计算单元,单 AI Core 的 FP16 矩阵乘法峰值可达 256 GFLOPS(Ascend 310)。 -
算子融合:
支持 “卷积 + 偏置 + 激活”“矩阵乘 + 残差连接” 等融合操作,减少中间结果的内存读写(昇腾芯片的内存带宽相对 GPU 较低,融合操作对性能提升更关键)。例如,ResNet 的瓶颈层(conv+bn+relu)可融合为一个算子,耗时降低 40% 以上。 -
低精度计算:
原生支持 FP16、BF16、INT8 等精度,针对大模型训练设计了混合精度策略(如 FP16 存储 + FP32 累加),在精度损失可控的前提下提升计算效率(类似 NVIDIA 的 AMP,但适配昇腾的计算单元)。
2. 与框架的集成方式
- MindSpore(华为自研框架):深度集成 CANN 算子库,通过 “静态图优化” 提前分析计算图,自动选择最优算子和融合策略。例如,定义
nn.Conv2d时,MindSpore 会根据输入形状(如(128, 3, 224, 224))和卷积核大小自动调用 CANN 中对应的优化卷积算子。 - 第三方框架(TensorFlow/PyTorch):通过 “适配层” 将框架的高层 API 映射到 CANN 算子。例如,PyTorch 的
torch.nn.Conv2d在昇腾上运行时,会被转换为 CANN 的卷积算子调用(需安装昇腾版 PyTorch 适配包)。
三、昇腾生态的差异化特性
-
达芬奇架构深度适配:
昇腾芯片的 AI Core 采用 “Cube 计算单元 + Vector 计算单元” 的异构设计(不同于 NVIDIA 的 Tensor Core),CANN 和算子库针对该架构做了定制化优化:- Cube 单元:专门处理矩阵乘法(如 16x16x16 的矩阵运算);
- Vector 单元:处理向量级操作(如激活函数、池化);
算子执行时会自动分配任务到不同单元,最大化硬件利用率。
-
分布式计算原生支持:
CANN 内置 “昇腾集合通信库(HCCL)”,类似 NVIDIA 的 NCCL,支持多卡间的通信操作(如 AllReduce、Broadcast)。在大模型训练中,HCCL 与 CANN 的算子库协同,实现张量并行、模型并行的高效通信(如盘古大模型采用 8 卡张量并行时,通信效率接近 NCCL)。 -
全场景部署能力:
不同于 CUDA 主要面向 GPU,CANN 支持昇腾芯片的全系列产品(从端侧 Ascend 310B 到云端 Ascend 910B),并提供统一的编程接口,开发者可一套代码适配多场景(如训练在 910,推理在 310)。
四、生态成熟度与应用现状
- 算子覆盖:截至 2024 年,CANN 已支持 90% 以上的主流深度学习算子(如 CNN、Transformer、RNN),但在一些冷门算子(如特定医学影像处理算子)上仍需自定义开发。
- 行业应用:在政务、金融、能源等国产化需求较高的领域已大规模落地,例如:
- 国家气象局用昇腾集群训练气象预测模型;
- 工商银行基于昇腾芯片部署智能风控模型。
- 生态挑战:第三方工具链(如可视化工具、自动调参库)的丰富度仍落后于 CUDA 生态,部分开源模型需手动适配才能在昇腾上高效运行。
总结
华为昇腾生态中,CANN 架构通过 AscendCL 接口、CCE 编译器和 TBE 算子开发框架,实现了与 CUDA 对等的底层计算能力;而CANN 内置的深度学习算子库(结合 MindSpore 的优化)则承担了类似 cuDNN 的角色,针对神经网络运算做了深度优化。这套方案虽在生态成熟度上与 NVIDIA 有差距,但凭借达芬奇架构的硬件特性和国产化优势,已成为大模型训练和推理的重要替代方案,尤其在对自主可控有强需求的场景中不可替代。
如果这个知识点对你有用,那就别客气——点赞、关注、收藏。你的每一次反馈都是给我打的小鸡血,一起冲鸭,变强不掉线!🐒🐒



















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











