# encoding = 'utf-8'
import pandas as pd
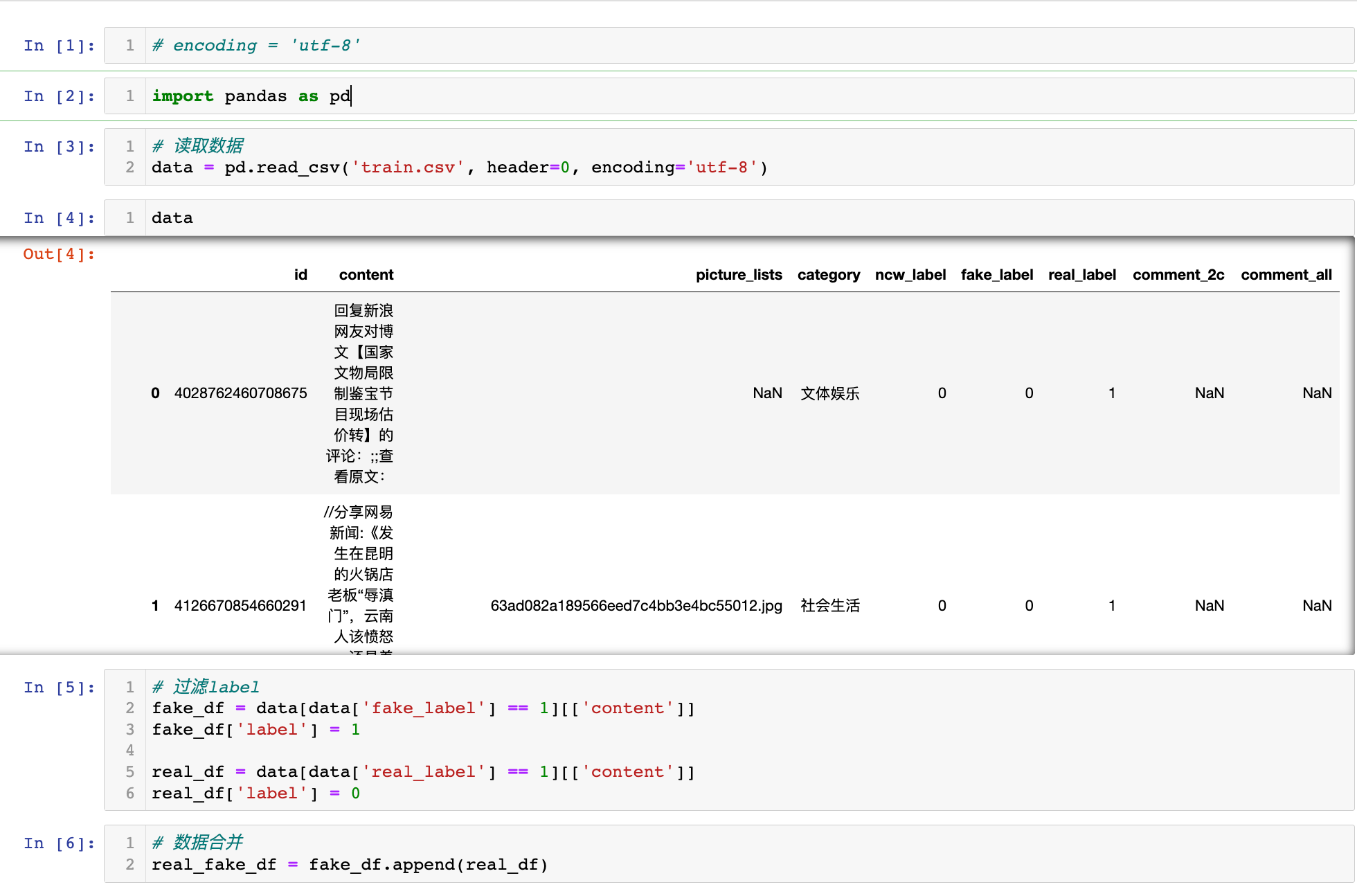
# 读取数据
data = pd.read_csv('train.csv', header=0, encoding='utf-8')
# 过滤label
fake_df = data[data['fake_label'] == 1][['content']]
fake_df['label'] = 1
real_df = data[data['real_label'] == 1][['content']]
real_df['label'] = 0
# 数据合并
real_fake_df = fake_df.append(real_df)
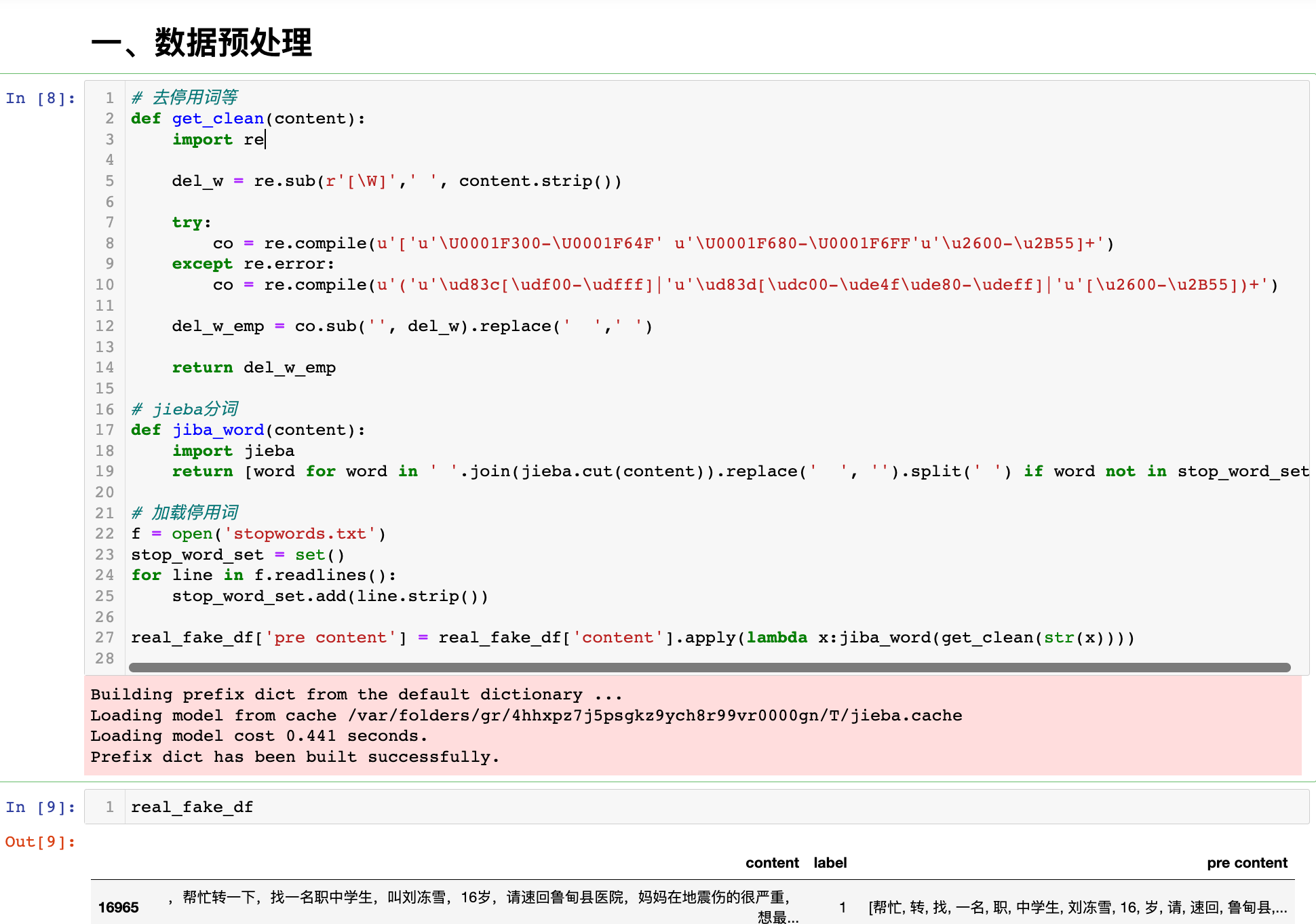
一、数据预处理
# 去停用词等
def get_clean(content):
import re
del_w = re.sub(r'[\W]',' ', content.strip())
try:
co = re.compile(u'['u'\U0001F300-\U0001F64F' u'\U0001F680-\U0001F6FF'u'\u2600-\u2B55]+')
except re.error:
co = re.compile(u'('u'\ud83c[\udf00-\udfff]|'u'\ud83d[\udc00-\ude4f\ude80-\udeff]|'u'[\u2600-\u2B55])+')
del_w_emp = co.sub('', del_w).replace(' ',' ')
return del_w_emp
# jieba分词
def jiba_word(content):
import jieba
return [word for word in ' '.join(jieba.cut(content)).replace(' ', '').split(' ') if word not in stop_word_set]
# 加载停用词
f = open('stopwords.txt')
stop_word_set = set()
for line in f.readlines():
stop_word_set.add(line.strip())
real_fake_df['pre content'] = real_fake_df['content'].apply(lambda x:jiba_word(get_clean(str(x))))
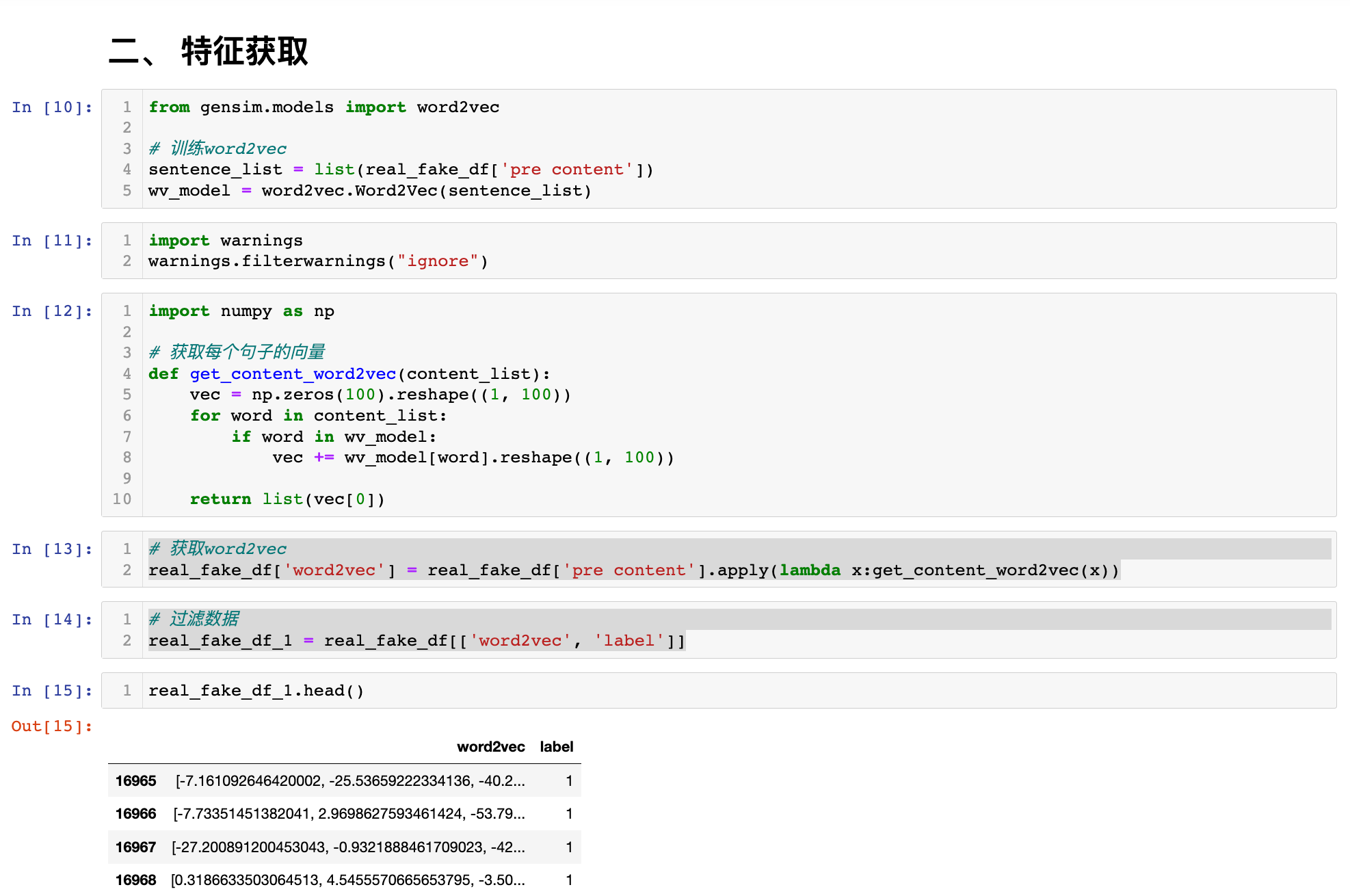
二、特征获取
from gensim.models import word2vec
import warnings
warnings.filterwarnings("ignore")
# 训练word2vec
sentence_list = list(real_fake_df['pre content'])
wv_model = word2vec.Word2Vec(sentence_list)
# 获取每个句子的向量
def get_content_word2vec(content_list):
vec = np.zeros(100).reshape((1, 100))
for word in content_list:
if word in wv_model:
vec += wv_model[word].reshape((1, 100))
return list(vec[0])
# 获取word2vec
real_fake_df['word2vec'] = real_fake_df['pre content'].apply(lambda x:get_content_word2vec(x))
# 过滤数据
real_fake_df_1 = real_fake_df[['word2vec', 'label']]
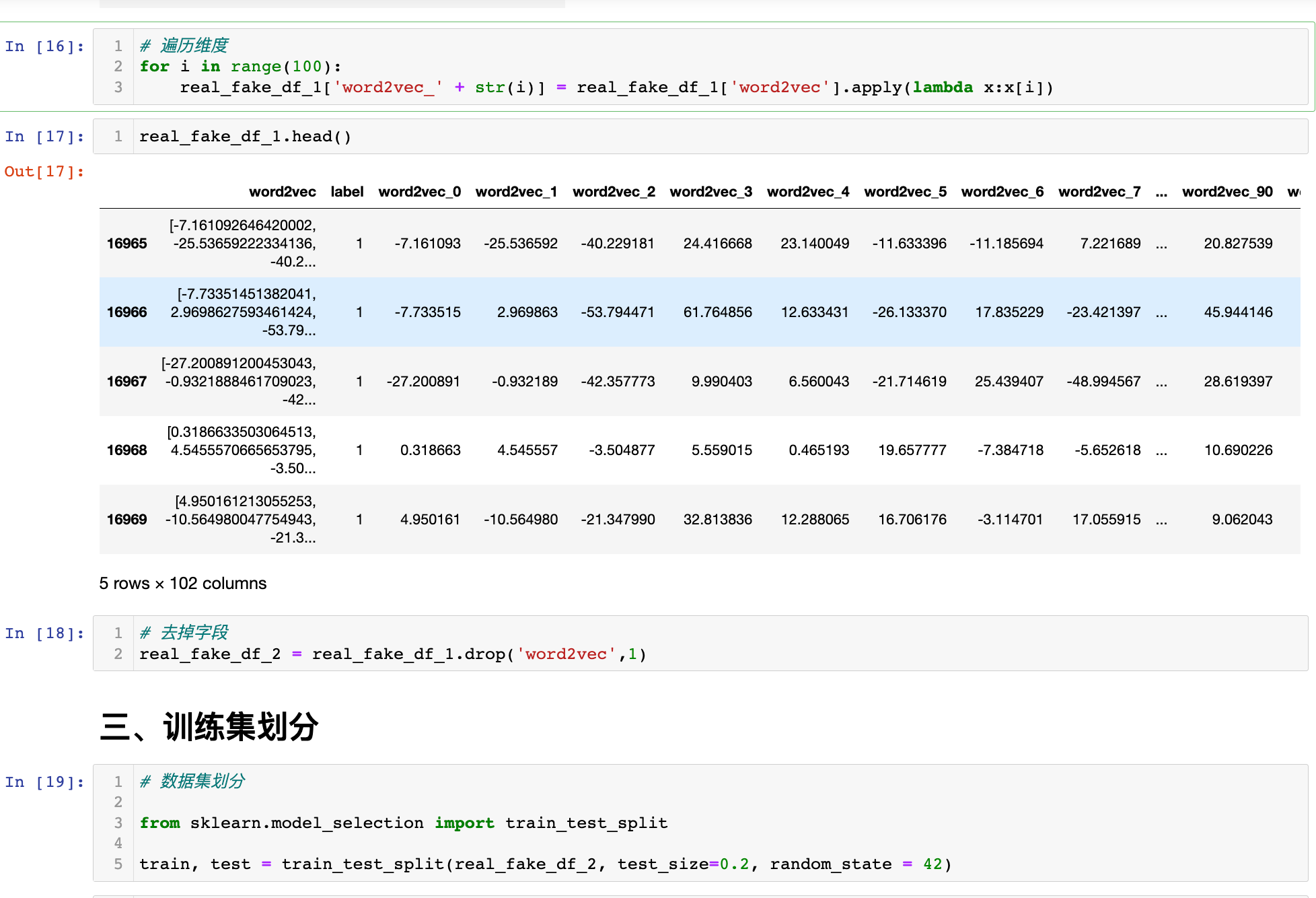
# 遍历维度
for i in range(100):
real_fake_df_1['word2vec_' + str(i)] = real_fake_df_1['word2vec'].apply(lambda x:x[i])
# 去掉字段
real_fake_df_2 = real_fake_df_1.drop('word2vec',1)
三、训练集划分
# 数据集划分
from sklearn.model_selection import train_test_split
train, test = train_test_split(real_fake_df_2, test_size=0.2, random_state = 42)
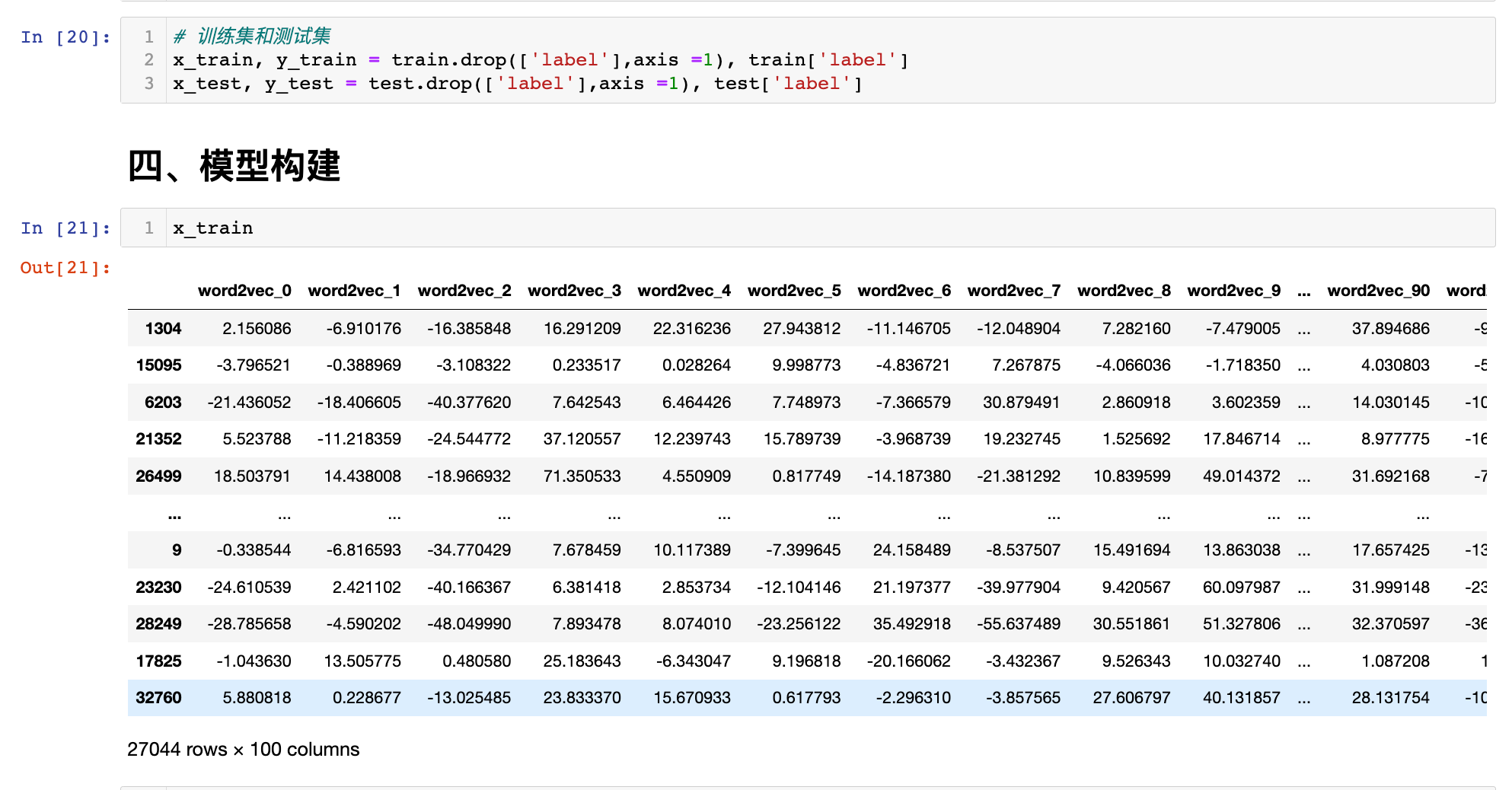
# 训练集和测试集
x_train, y_train = train.drop(['label'],axis =1), train['label']
x_test, y_test = test.drop(['label'],axis =1), test['label']
四、模型构建
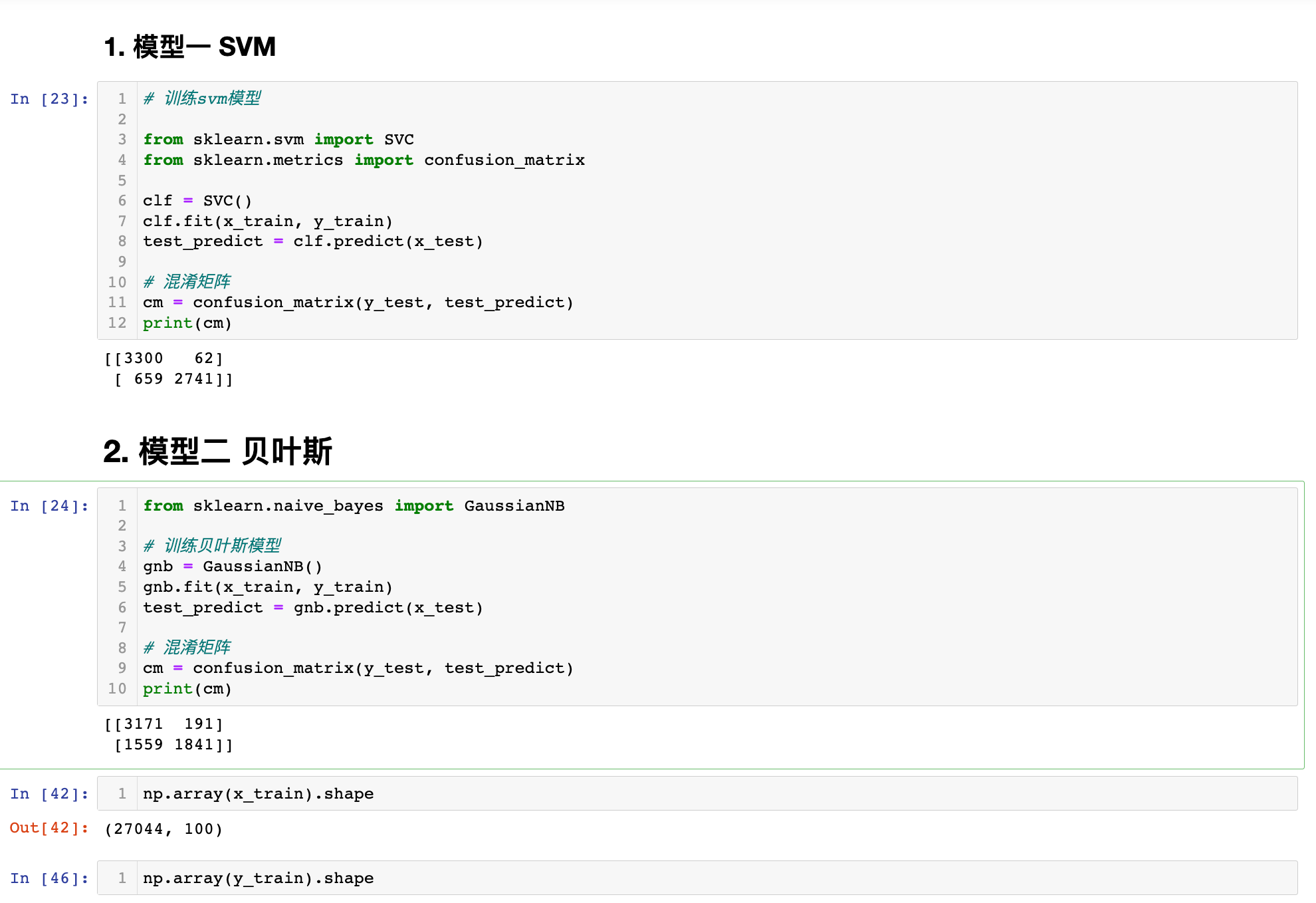
一、SVM
# 训练svm模型
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix
clf = SVC()
clf.fit(x_train, y_train)
test_predict = clf.predict(x_test)
# 混淆矩阵
cm = confusion_matrix(y_test, test_predict)
print(cm)
二、贝叶斯
from sklearn.naive_bayes import GaussianNB
# 训练贝叶斯模型
gnb = GaussianNB()
gnb.fit(x_train, y_train)
test_predict = gnb.predict(x_test)
# 混淆矩阵
cm = confusion_matrix(y_test, test_predict)
print(cm)
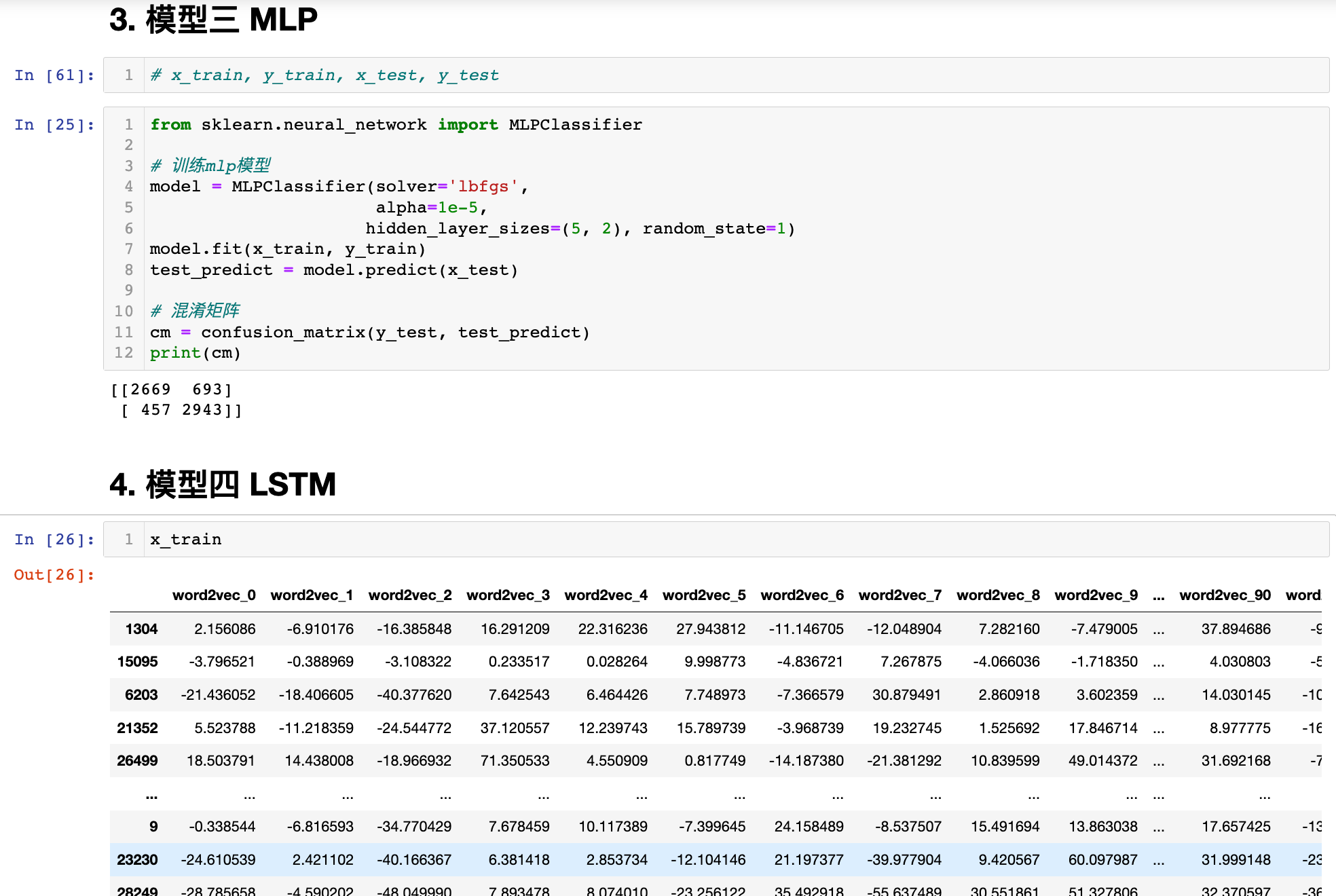
三、MLP
from sklearn.neural_network import MLPClassifier
# 训练mlp模型
model = MLPClassifier(solver='lbfgs',
alpha=1e-5,
hidden_layer_sizes=(5, 2), random_state=1)
model.fit(x_train, y_train)
test_predict = model.predict(x_test)
# 混淆矩阵
cm = confusion_matrix(y_test, test_predict)
print(cm)
四、LSTM
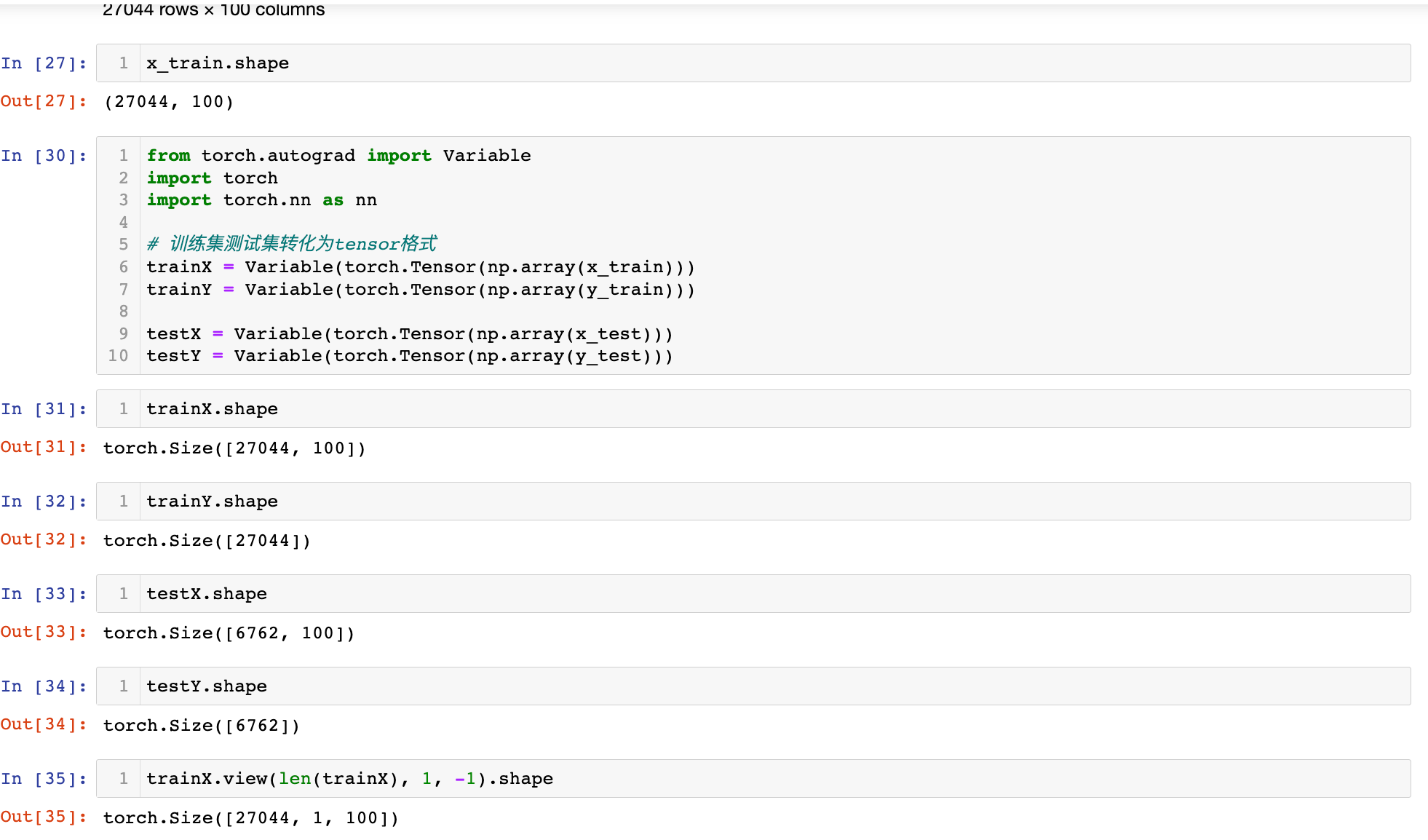
from torch.autograd import Variable
import torch
import torch.nn as nn
# 训练集测试集转化为tensor格式
trainX = Variable(torch.Tensor(np.array(x_train)))
trainY = Variable(torch.Tensor(np.array(y_train)))
testX = Variable(torch.Tensor(np.array(x_test)))
testY = Variable(torch.Tensor(np.array(y_test)))
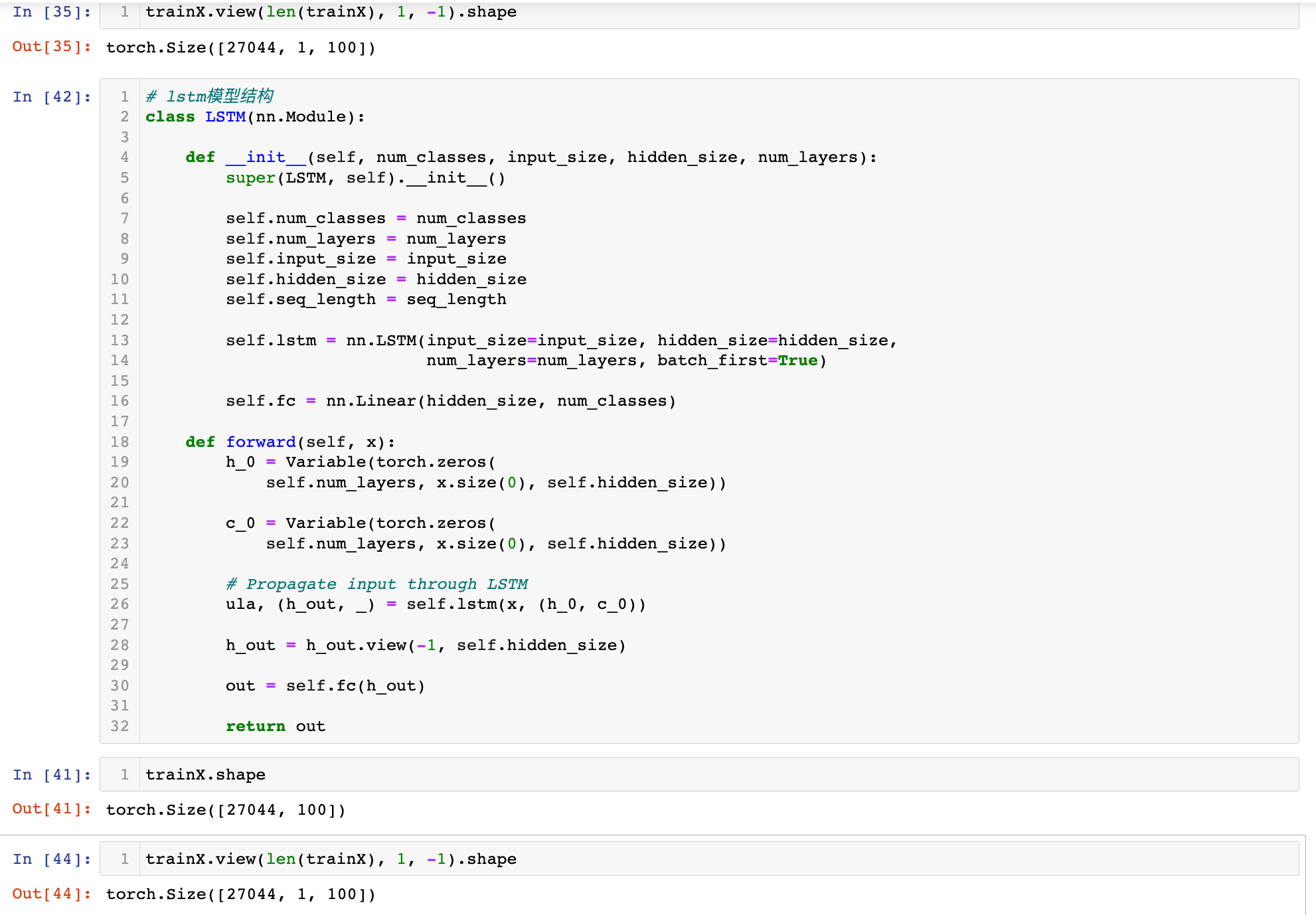
# lstm模型结构
class LSTM(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers):
super(LSTM, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.seq_length = seq_length
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size))
c_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size))
# Propagate input through LSTM
ula, (h_out, _) = self.lstm(x, (h_0, c_0))
h_out = h_out.view(-1, self.hidden_size)
out = self.fc(h_out)
return out
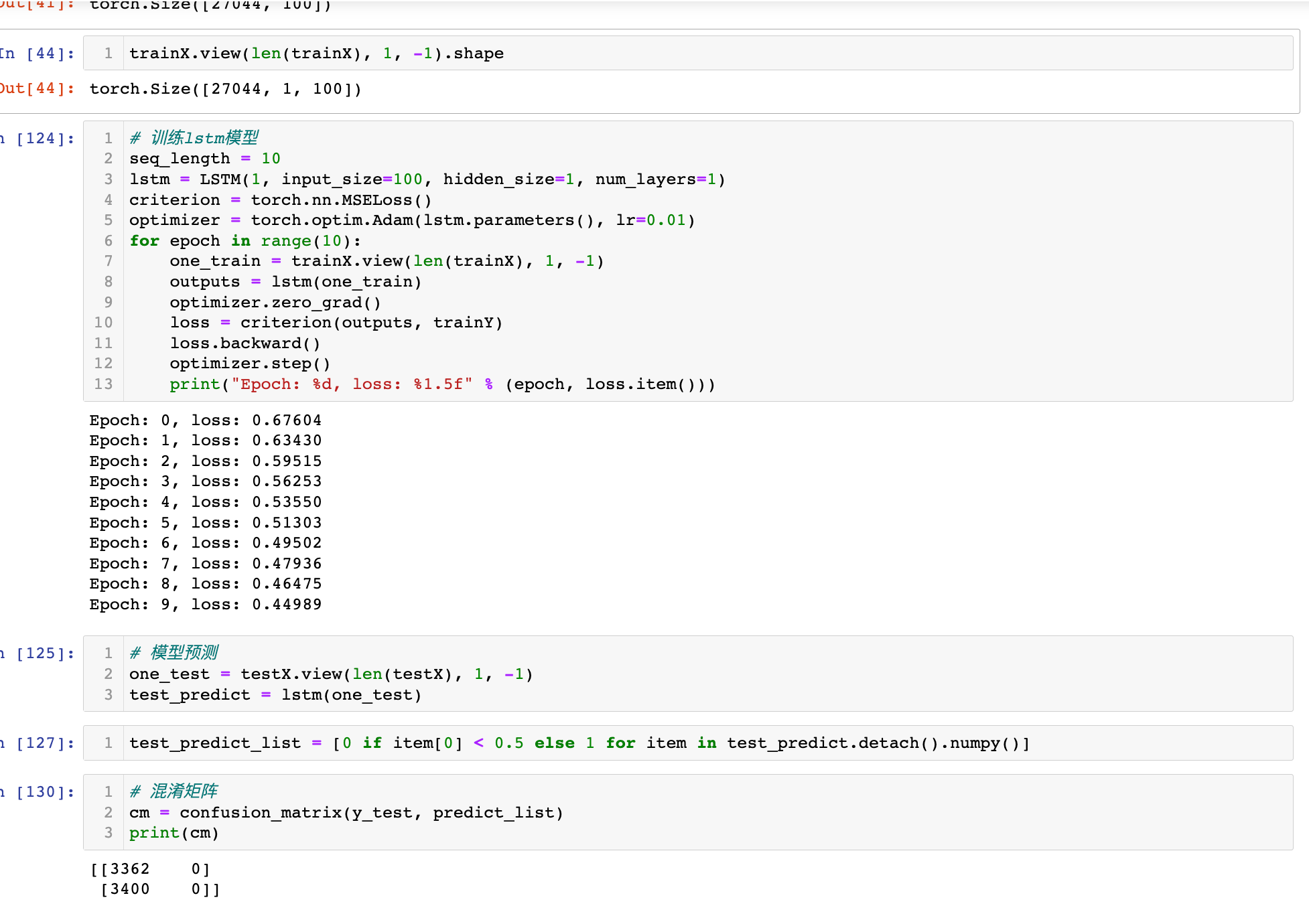
# 训练lstm模型
seq_length = 10
lstm = LSTM(1, input_size=100, hidden_size=1, num_layers=1)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(lstm.parameters(), lr=0.01)
for epoch in range(10):
one_train = trainX.view(len(trainX), 1, -1)
outputs = lstm(one_train)
optimizer.zero_grad()
loss = criterion(outputs, trainY)
loss.backward()
optimizer.step()
print("Epoch: %d, loss: %1.5f" % (epoch, loss.item()))
# 模型预测
one_test = testX.view(len(testX), 1, -1)
test_predict = lstm(one_test)
test_predict_list = [0 if item[0] < 0.5 else 1 for item in test_predict.detach().numpy()]
# 混淆矩阵
cm = confusion_matrix(y_test, predict_list)
print(cm)
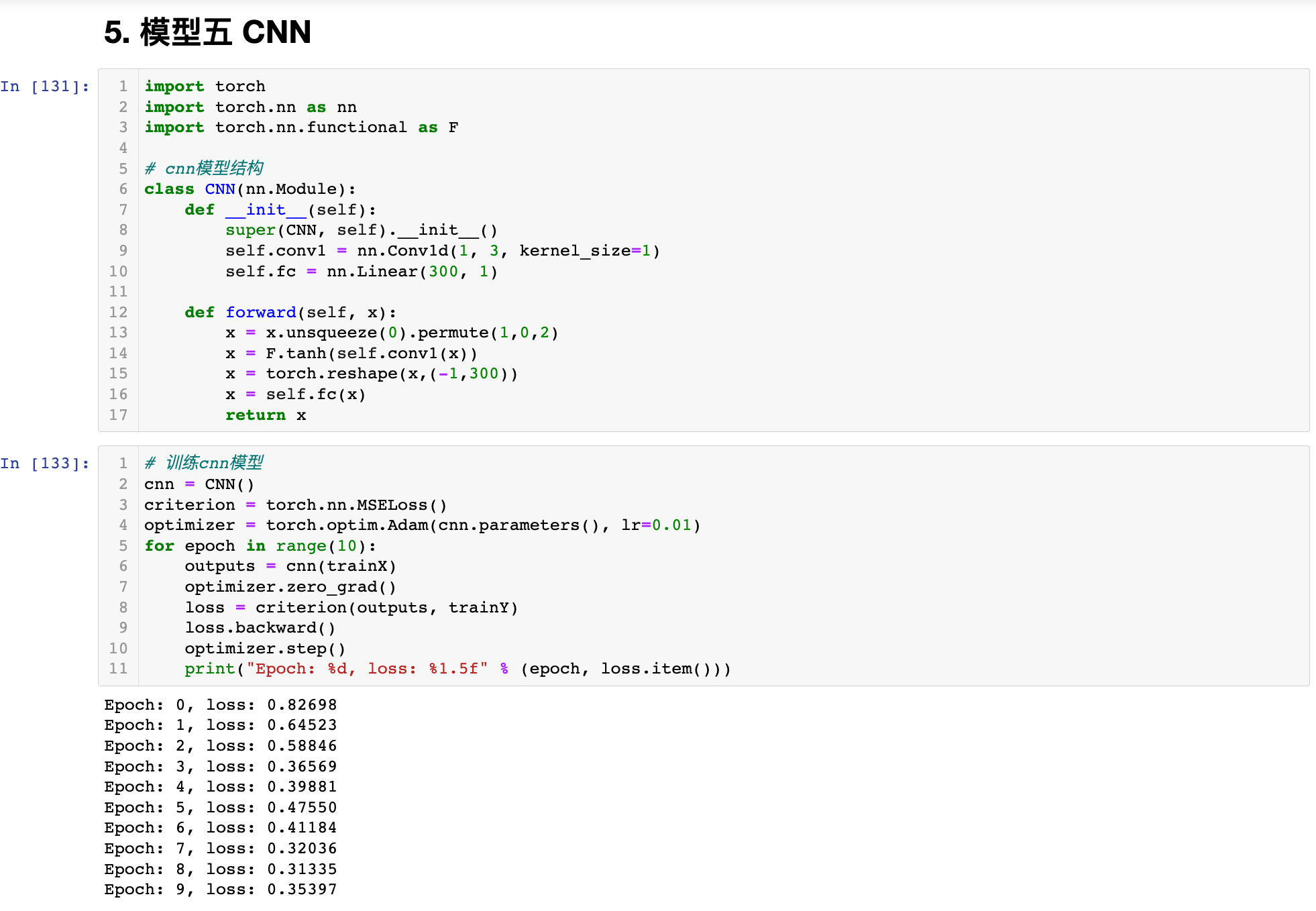
五、CNN
import torch
import torch.nn as nn
import torch.nn.functional as F
# cnn模型结构
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv1d(1, 3, kernel_size=1)
self.fc = nn.Linear(300, 1)
def forward(self, x):
x = x.unsqueeze(0).permute(1,0,2)
x = F.tanh(self.conv1(x))
x = torch.reshape(x,(-1,300))
x = self.fc(x)
return x
# 训练cnn模型
cnn = CNN()
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(cnn.parameters(), lr=0.01)
for epoch in range(10):
outputs = cnn(trainX)
optimizer.zero_grad()
loss = criterion(outputs, trainY)
loss.backward()
optimizer.step()
print("Epoch: %d, loss: %1.5f" % (epoch, loss.item()))
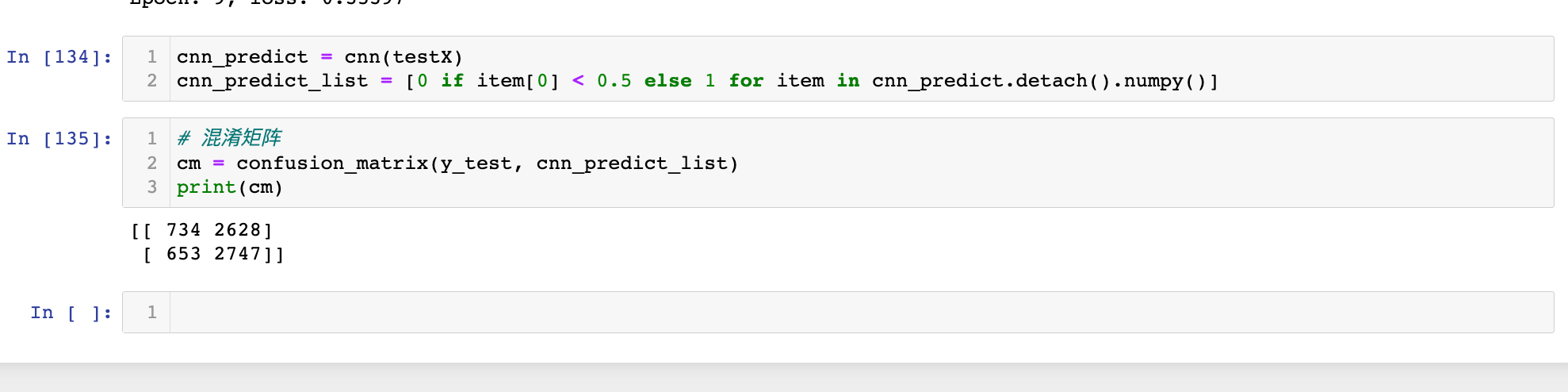
cnn_predict = cnn(testX)
cnn_predict_list = [0 if item[0] < 0.5 else 1 for item in cnn_predict.detach().numpy()]
# 混淆矩阵
cm = confusion_matrix(y_test, cnn_predict_list)
print(cm)

























 3177
3177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









