







 本文通过随机森林算法实现验证码识别,适用于变形验证码。不涉及理论,直接展示实践过程,包括样本处理、特征向量化、模型训练和预测。使用默认参数的RandomForestClassifier,识别率高达99.8%。
本文通过随机森林算法实现验证码识别,适用于变形验证码。不涉及理论,直接展示实践过程,包括样本处理、特征向量化、模型训练和预测。使用默认参数的RandomForestClassifier,识别率高达99.8%。
注意
本文纯粹给未接触过机器学习的同学看到,高手请绕路
背景
本人接触了一个项目,需要登录web系统。使用robotframework + python 做自动化测试,发现开发同学设置了验证码,首页面根本就没法登录啊,而且还是变形的,使用基本的python库识别效果不好。于是本人查询了多位大侠的网站和文章,发现识别没有这么难,只是写的还不够白,所以我这次写的白一点,让大家看的更清楚一些。
![]()
本文只识别与上述这种不太复杂的图片,太复杂的,特征向量选取就比较麻烦
另外,
1、本文不介绍理论,直接使用为主,快速入门为目标
2、本文未考虑图像干扰点清理的过程
涉及的技术内容概念
样本:
对于本文来说,就是大量图片,和未来待识别的内容完全一致的东西,根据这些图片的内容,经过学习,生成学习后的model,用于后续的,预测,例如:

验证集(预测集)
和上述完全一致,是一类东西,上述的用于学习model,输出model文件后,那这个在用于预测下属的图片
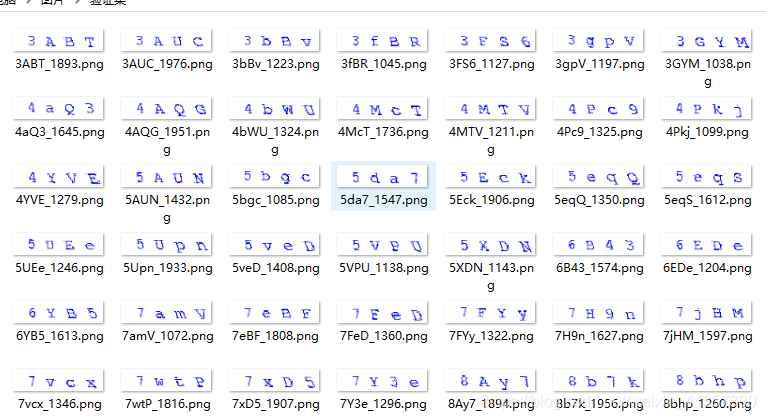
最小样本集:
实际上,机器学习,不是用上面的学习的,是要经过处理的,最终目标是识别某单个字符图片的字符是什么内容
观察上述的样本,有两个明显可以看出来的问题:
例如 一个图片内容是“3456”,最终需要分解成四张小图片去训练

样本来源(学习集和验证集)
各显其能吧,我是找开发要了他们原始的验证码和图片生成代码
样本预处理(图片数据清晰)
对于字符识别处理,基本都采用灰度处理,把字符变成了最终0和255两个值,其余的RGB信息全部去除
样本特征:
 针对这样的一个图片,要数字化,才能去调用机器学习算法学习
针对这样的一个图片,要数字化,才能去调用机器学习算法学习
一般使用向量标识
data = [[1,2,3,4,5,6,7,8,9,0], [1,2,3,4,5,6,7,8,9,0] ,[1,2,3,4,5,6,7,8,9,0] ,[1,2,3,4,5,6,7,8,9,0]]
上面是就是一个list,有四个元素,其中每个元素对应于一个10维空间的一个向量,每个向量描述一个字符
上述向量代表的值,没对应什么呢,对应于一一映射的另一个list
label = [3,4,5,6]
data和label 是两个一一对应的list,分别对应图片,及图片的字符是什么内容
学习模型(算法)
这个就是大家经常听到的,学习算法是什么,本文不讲理论,只是让大家快速用起来
所以使用最简单的随机森林算法RandomForestClassifier(),并使用其默认参数,而且会发现,即使默认参数,识别率就相当高
学习完成,会生成一个model文件
输入是data和label
模型预测
使用上述生成model,就可以
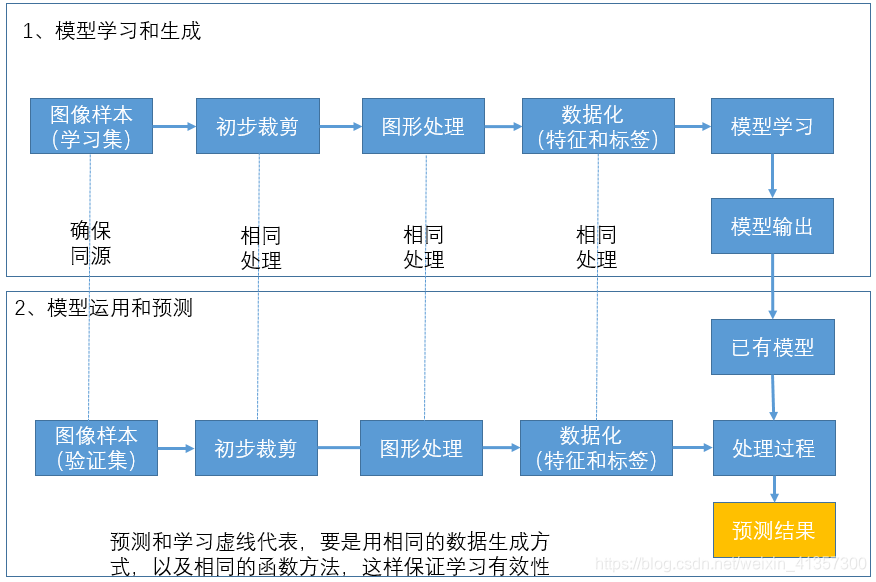
整个过程图
涉及的全部函数(后续再分解说)
公共函数
read_captcha_image( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 8900
8900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









