




废话
这是一篇关于目标检测算法的新坑,参考资料都在文末,大佬已经写得很清楚,但是我学会了,我就要自己总结一遍,要不然怎么证明我会了捏!
再说了,没准同类小白就喜欢看我写的呢,毕竟小白之间的交流更加无障碍!为了普天之下的小白们,冲冲冲!!!
文章:《You Only Look Once: Unified, Real-Time Object Detection》 戳我.
作者是已经退出计算机视觉研究的Joseph Redmon,我也想退出啊~喂(醒醒,不搬砖谁养你,周星驰吗?)
开始正文
首先文中带言,YOLO的特点是重定义目标检测问题,把分类问题变成回归问题,用端到端的方式训练了一个目标检测模型。
之前的目标检测方法流程大致是:滑动窗口得到候选区–对类别进行分类预测–然后一些后处理去冗余得到最终结果。(细节的请参见本专题下的其他博客,嗯,我还没写,有空会写emmm~~ 手动狗头)
YOLO正如他的标题一样,你不需要耦合多个阶段方法,只需要输入一张图片,一切搞定!
But How??
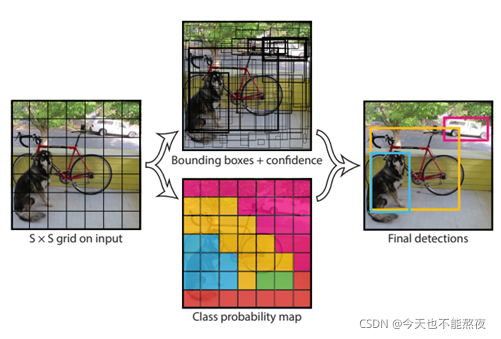
input: 一张作者家的狗的图片
- 给它划分网格,划分成S*S个(此处S = 7)
- 用这七七四十九个网格,每个网格去预测B(B=2)个Bbox,每个Bbox的信息包括位置信息(x,y,w,h),和一个confidence(置信度)信息(蕴含了所预测的box中含有object的置信度和这个box预测的有多准两重信息): P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)*IOU_{pred}^{truth} Pr(Object)∗IOUpredtruth
- 同时这七七四十九个网格,每一个将预测一个类别信息(一共有几类就有几个数,分类任务都学过哈)
output: S ∗ S ∗ B ∗ ( 4 + 1 ) + S ∗ S ∗ C S*S*B*(4+1)+S*S*C S∗S∗B∗(4+1)+S∗S∗C 文中一共20类因此输出 7 ∗ 7 ∗ 30 7*7*30 7∗7∗30维的Tensor
具体流程
Test:打格子 — 得到输出Tensor — 按照下式计算置信度得分 — 按照阈值淘汰一批,最后去冗余
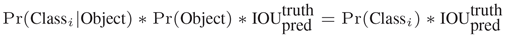
Train:打格子 — 得到输出Tensor — 计算损失函数
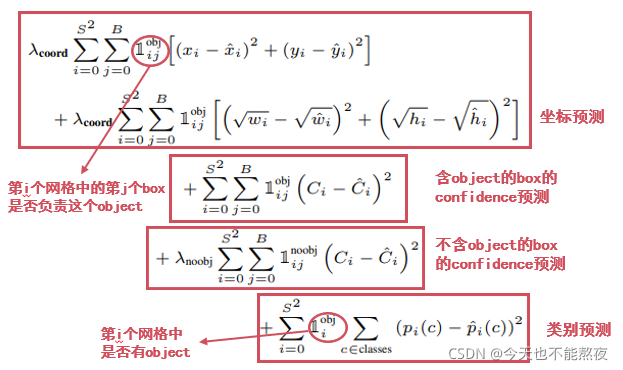
由于有真值,我们知道要预测的狗子的中心点落在一个网格里,那么这个网格所预测的两个box就负责检测这个狗子,我们取两个box里与真值IOU较大的那个( 7 ∗ 7 ∗ 30 7*7*30 7∗7∗30维的Tensor中找到对应网格的30维信息,这里有4维是位置信息,去计算IOU,然后找到两个中负责预测狗子的那个box),用它的(x,y,w,h)来计算损失函数的坐标预测。
注意:相对于大box,我们应该让小box对偏移更敏感,直观地,同样是偏移5可能对于大box几乎可以忽略,但是对于小box几乎是致命的,因此这里对于w,h计算的是平方根,根据函数图像(图),我们知道w,h较小的时候 w 与 h \sqrt w与\sqrt h w与h对于x轴的偏差越敏感。

中间两项分别计算包含和不包含object的框置信度预测,(计算不包含object的置信度可以防止背景的误检?)对应计算方法如下:

最后一项是对类别预测的损失,因为每一个网格预测一个类别因此这里前面要判断一下该网格是否负责物体预测,是则为1,不是就是0。
权重是为了平衡20维的类别信息与8维的位置信息带来的影响
综上,就是YOLO_v1的全部过程,如果有问题可以评论或留言,我们一起学习~~
参考:
https://zhuanlan.zhihu.com/p/362758477
b站同济子豪兄的视频–还有论文精读,不要太良心哦~~

















 2307
2307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









