






 本文详细介绍了SQL的基础操作包括增删改查,深入探讨了事务处理、锁机制、多版本并发控制(MVCC)以及InnoDB存储引擎的特点。涵盖了从基本SQL语法到高级数据库管理的重要知识点。
本文详细介绍了SQL的基础操作包括增删改查,深入探讨了事务处理、锁机制、多版本并发控制(MVCC)以及InnoDB存储引擎的特点。涵盖了从基本SQL语法到高级数据库管理的重要知识点。
基础增删改查(怕忘)
insert into 表名(字段名1,字段名2…)value(值1,值2…);
insert into 表名 value(值1,值2…);
insert into 表名 value(),(),…;
delete from 表名 (where 条件),不加where就是全删
truncate table 表名 只能删全表
注意!使用TRUNCATE语句删除记录后,新添加的记录时,自动增长字段(如本文中student表中的 id 字段)会默认从1开始,而使用DELETE删除记录后,新添加记录时,自动增长字段会从删除时该字段的的最大值加1开始计算(即原来的id最大为5,则会从6开始计算)。
update 表名 set 字段名1=值1,字段名2 = 值2 (where条件)
如不使用where条件,则全表更新
Select select 选项 字段列表 from 数据源 where 条件 group by 分组 having 条件 order by 排序 limit 限制;
Mysql服务器的逻辑框架
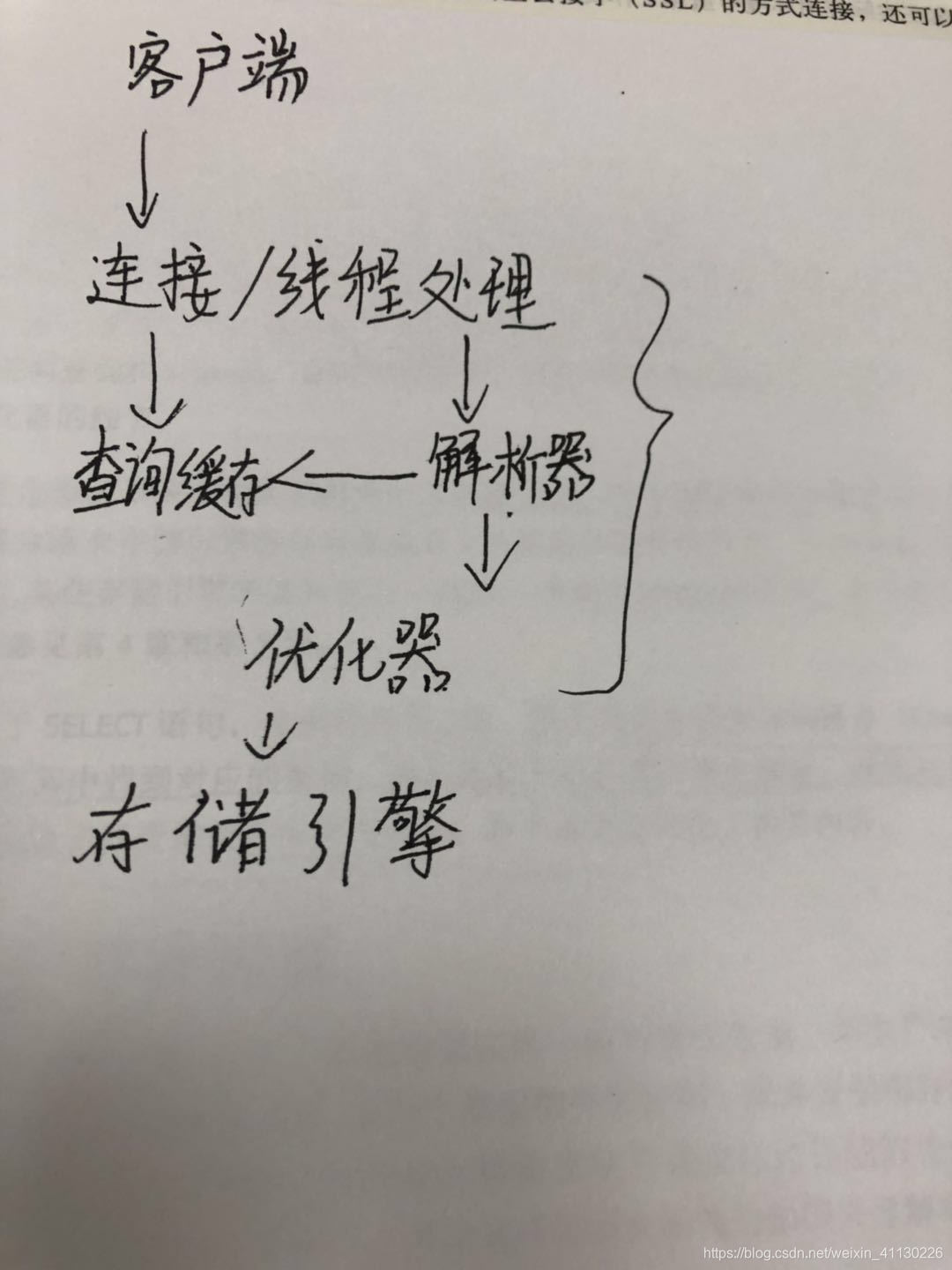
mysql会解析查询,并创建内部数据结构,优化器不关心表使用的是什么存储引擎,但存储引擎对优化查询是有影响的。
在解析查询之前,服务器会先查询缓存,如果能在其中找到对应的查询,服务器就不必在执行查询解析,优化和执行整个过程。而是直接返回查询缓存中的结果。
读写锁
概念,读锁是共享的,或者说是互不排斥的,写锁是排他的,
表锁
是mysql中最基本的锁策略,而且开销最小,锁定整张表,写操作之前要获取写锁,阻塞所有其他操作,读锁之间是不阻塞的
行级锁
可以最大程度的支持并发处理,同时它的锁开销也是最大的,InnoDB和其他一些引擎都实现了行级锁,行级锁只在引擎层实现。
事务
一组原子性的sql查询
事务内的语句,要么全部成功,要么全部失败
银行应用是最好的一个解释例子,两张表checking表1支票表,savings表2 存储
从我的支票账户转200块到存储账户
1检查支票账户的余额高于200
2支票账户减200
3存储账户加200
以上3个操作必须打包在一个事务中,任何一个失败都要全部回滚
start transaction;
select balance from checking where id = 123;
update checking set balance = balance-200 where id = 123;
updata saving set balance = balance +200 where id =123;
commit;
事务要有ACID特性,A表示原子性,C表示一致性,I表示隔离性,D表示持久性
原子性:一个事务必须看做一个不可被分割的最小工作单元,整个事务的所有操作要么全成功,要么全失败回滚。
一致性:数据库总是从一个状态转移到另一个状态。假如前面的例子3行失败了,checking也不会少200,因为没有提交。
隔离性:一个事务在最终做完提交之前,对其他事务是不可见的。
持久性:一旦提交,对其做的修改就永久保存在数据库中。
实际中,要完全实现ACID不可能,这种事务处理过程中的安全性,需要很大的系统开销,对一些不需要事务的应用,选择一个非事务引擎,会提高性能。
mysql默认采用自动提交的模式,就是如果不是显式的开始一个事务,每个查询都会被当做一个事务执行提交操作。
可以用 show variables like ‘AUTOCOMMIT’;
SET AUTOCOMMIT = 0 ;关闭,直到显式执行commit或者ROLLBACK回滚。
在同一个事务中,使用多种存储引擎不可靠
为每张表选择最适合的存储引擎很重要。
在事务执行过程中,随时都可以执行锁定,锁只有在执行commit或者rollback的时候才会释放,并且所有的锁都是在同一时间释放,这就是隐式锁定,InnoDB不需要显式的使用LOCK table语句,而且还会严重影响性能,实际上InnoDB的行级锁工作的很好。
隔离级别
read uncommitted(未提交读),事务可以读未提交的数据,脏读(对于两个事务T1与T2,T1读取了已经被T2更新但是还没有提交的字段之后,若此时T2回滚,T1读取的内容就是临时并且无效的),几乎很少用
read committed(提交读)一个事务开始时只能看见已经提交的事务所做的修改, 有不可重复读的问题(对于两个事务T1与T2,T1读取了已经被T2更新但是还没有提交的字段之后,若此时T2回滚,T1读取的内容就是临时并且无效的),一次查询执行两次,可能得到不一样的结果。
repetable read可重复读,解决了脏读和不可重复读,但是无法解决幻读( 对于两个事务T1、T2,T1从表中读取数据,然后T2进行了INSERT操作并提交,当T1’再次读取的时候,结果不一致的情况发生。),InnoDB通过MVCC解决了这个问题,他是mysql默认的事务隔离级别
serializable可串行化在读取的每一行数据上加锁,同一时刻支持多个事务并发,但是针对DML(UPDATE\INSERT\DELETE)操作时,当前发起操作的事务会被阻塞,直到其他事务commit或者rollback才会继续执行事务语句。可见效率十分低下。
死锁
两个或多个事务在同一资源上互相占用,请请求获得对方正在占用的锁。
陷入死循环,
InnoDB目前处理死锁的方法是,将持有最少行级锁排他锁的事务回滚。
死锁的原因:
1真正的数据冲突,很难避免
2存储引擎的实现方式导致的。
多版本并发控制
MVCC
是行级锁的一个变种,但是他在很多情况下避免了加锁的操作,因为他开销更低,写操作也只是锁定必要行
InnoDB的MVCC:
在每行记录后保存两个隐藏列实现的,这俩列一个保存行的创建时间,一个保存行的过期时间(删除时间),每开始一个新事物,系统版本号都会自动递增,事务开始时刻的系统版本号会作为事务的版本号。
select:
InnoDB的两个条件
1)删除版本号未指定或者大于当前事务版本号,即查询事务开启后确保读取的行未被删除。
2) 创建版本号 小于或者等于 当前事务版本号 ,就是说记录创建是在当前事务中(等于的情况)或者在当前事务启动之前的其他事物进行的insert。
Insert:
插入每一行保存当前系统版本号作为行版本号,
Delete
为删除的每一行都保存当前的系统版本号作为删除标识
Update
在更新操作的时候,采用的是先标记旧的那行记录为已删除,并且删除版本号是事务版本号,然后插入一行新的记录的方式。
比如,针对上面那行记录,事务Id为2 要把name字段更新
update table set name= ‘new_value’ where id=1;

保存这两个额外的版本号,使得大部分操作都不需要加锁,这样可以使读数据很简单,性能很好,只是每行都需要额外的空间,需要更多的行检查工作。
MVCC只在隔离级别为repeatble read和read commitred时工作,其他两个都不兼容MVCC,read uncommitted总会读取最新的数据行,serializable则会对所有读取的行加锁。
InnoDB存储引擎
是mysql默认的事务性引擎,是最重要,用的最多的引擎,
InnoDB采用MVCC来支持高并发,默认隔离级别是repeatable read,通过间隙锁来防止幻读。不仅仅锁定查询设计的行,还会对索引中的间隙进行锁定,防止幻影行的插入。
索引:https://zhuanlan.zhihu.com/p/29118331
基于聚簇索引,对主键查询的性能很好。不过他的二级索引必须包含主键列
若表上有很多索引的话,主键应尽可能的小。
从磁盘中读取数据是采用可预测性预读,能够自动在内存中创建hash索引来加速操作的自适应哈希索引。
大部分时候,InnoDB引擎都是正确的选择。
将表的引擎改为InnoDB
alter table 表名 ENGINE = InnoDB;
可能会执行很长时间,如果将一张InnoDB表转为MyISAM,然后再转回去,原InnoDB表上所有的外键都会丢失。

















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









