







 本文详细介绍了如何使用Scrapy爬虫框架来抓取网页上的教师信息。通过新建项目、设置爬虫、编写管道文件、配置settings.py以及定义items.py,成功解决了在爬取过程中遇到的模块导入错误和数据写入问题,最终实现了数据的顺利爬取和存储。
本文详细介绍了如何使用Scrapy爬虫框架来抓取网页上的教师信息。通过新建项目、设置爬虫、编写管道文件、配置settings.py以及定义items.py,成功解决了在爬取过程中遇到的模块导入错误和数据写入问题,最终实现了数据的顺利爬取和存储。
Scrapy爬虫实例——爬取网页教师的信息
具体代码资料等见:https://download.youkuaiyun.com/download/weixin_41104835/11006621
(如果有需要,没有积分的,留邮箱,发你链接)
新建项目
-
要了解具体步骤的,可以参考另外一篇博文:
https://blog.youkuaiyun.com/weixin_41104835/article/details/88319765
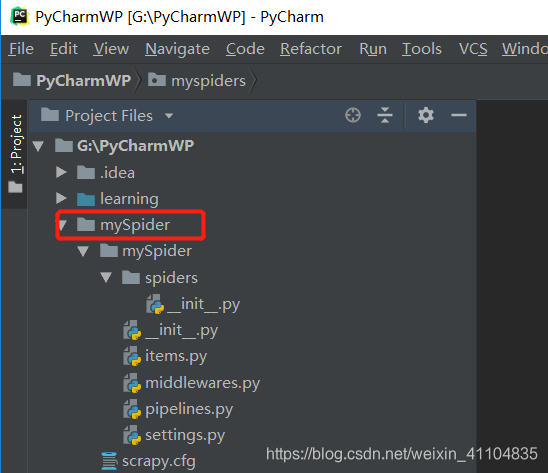
-
创建爬虫,指定爬取页面
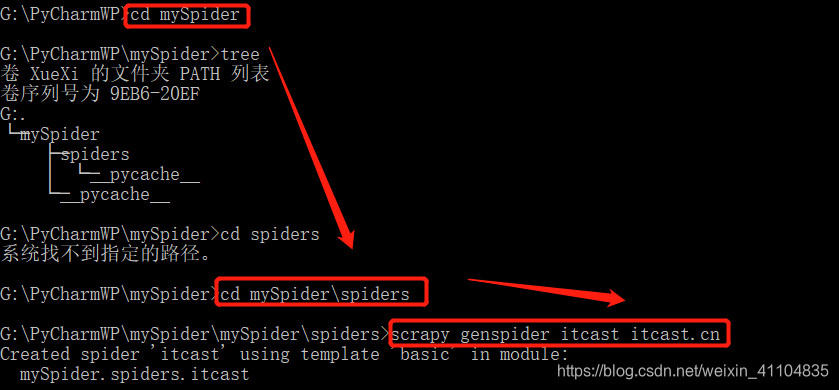
-
编写管道文件 pipelines.py: 处理爬虫返回的item数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









