







前言:用Markov 不等式引出Chebyshev 不等式,介绍收敛这个概念,最后介绍weak law of large numbers,即sample mean 收敛到
E
[
X
]
E[X]
E[X]。
之所以有weak law 这个词, 是因为还有strong law。这里只介绍weak law of large numbers。

如果有成千上万的企鹅,想要得到他们的平均身高,也就是期望身高 E [ X ] E[X] E[X],不能够一个一个量,只能采取采样的方法求这采样的sample mean M n M_n Mn。
注意
E
[
X
]
E[X]
E[X]是一个数字,而
M
n
M_n
Mn是一个随机变量,因为他是由多次采样的值
X
i
X_i
Xi组成的值。
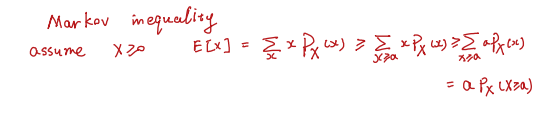
Markov inequality 连接了 E [ X ] E[X] E[X] 和 P ( X ≥ a ) P(X\geq a) P(X≥a)这两个量,即连接了期望值和概率值,当期望小的时候,概率 P ( X ≥ a ) P(X\geq a) P(X≥a)也跟着小。
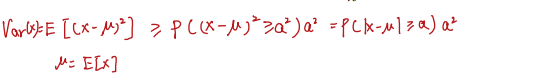
同理我们可以把上面的随机变量换成
(
X
−
μ
)
2
(X - \mu)^2
(X−μ)2那么就成了Var(X)

连续空间的完整推导。直观来看,随机变量落在离期望越远的事件,概率越小。

这里介绍了极限的含义,对于任意小的间隔
ϵ
\epsilon
ϵ, 都能够找到与之对应的
n
0
n_0
n0, 当
n
≥
n
0
n \geq n_0
n≥n0的时候,
a
n
a_n
an和
a
a
a的距离小于这个小间隔
ϵ
\epsilon
ϵ。
注意在这里 a n a_n an是某个确定的值。这里的 n n n代表序列的索引。

如果序列中的元素 a n a_n an不再是确定的,而是随机的 Y n Y_n Yn。如何给出定义呢? 我们可以借用上一篇对确定序列极限的定义,因为随机变量虽然随机, 但是随机变量的值离某个值a的距离大于 ϵ \epsilon ϵ这个事件的概率 P ( ∣ Y n − a ∣ ≥ ϵ ) P(|Y_n-a| \geq \epsilon) P(∣Yn−a∣≥ϵ)是一个确定的值,那么再定义这个值的极限为0,就可以定义随机变量的极限是a。

对于sample mean 这个随机变量,它的期望等于单次的期望,方差Var是原方差的
1
n
\frac{1}{n}
n1,再根据切比雪夫不等式和随机变量收敛的定义,可以推导出
M
n
M_n
Mn这个随机变量收敛到单次实验的期望
μ
\mu
μ

举一个大家爱可口可乐还是百事可乐的例子,我们的目标是求出sample mean距离真实值的误差小于1%的置信度大于95%时,需要多大的取样,即序列的索引要大于多少。
在这里,我们利用切比雪夫不等式,关联期望和概率的关系,再转换sample mean的方差为单次实验的方差,得到最少需要的试验次数。这里的切比雪夫不等式过于宽松,能不能找到一个更精确的不等式?


中心极限定理,sample sum这个随机变量在上一篇中表现为
n
E
[
X
]
nE[X]
nE[X]的期望和
n
σ
2
n\sigma^2
nσ2的方差,方差和期望都很大,我们可以将随机变量标准化为方差为1期望为0的
Z
n
Z_n
Zn。
中心极限定理就是当n很大的时候,
Z
n
Z_n
Zn会趋于一个标准正太分布。
digression : n离题,岔开;

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









