






《Oracle使用》
MERGE 使用例子1《既更新又插入》
MERGE INTO SDIS_T_6_2 A USING (
SELECT * FROM SDIS_T_6_2_R
WHERE pro_status = '2'
and data_dt = '2024-08-12'
and issued_no = '732151'
and rpt_org_no = '703220'
and dept_no = '001'
) AS B
ON A.rid = B.rid
WHEN MATCHED THEN
UPDATE SET A.F020063 = B.F020063,
A.F020001 = B.F020001,
A.F020002 = B.F020002
......,
A.rpt_org_no = B.rpt_org_no
WHEN NOT MATCHED THEN
INSERT (A.F020063,A.F020001,A.F020002,...,A.rpt_org_no)
VALUES(B.F020063,B.F020001,B.F020002,...,B.rpt_org_no)
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN
-- 目标表和源表中都有的id,则把源表中的数据更新到目标表中
update set t.desc = s.desc
WHEN NOT MATCHED THEN
-- 目标表中没有id,源表中有,则把源表中的数据插入到目标表中
insert (t.desc) values (s.desc)
WHEN NOT MATCHED BY SOURCE THEN
-- 目标表中有id,源表中没有,则把目标表中的id对应记录删除掉
delete;
MERGE 使用例子2
假设有两个表:target_table 和 source_table,我们要合并这两个表的数据,
MERGE INTO target_table AS target
USING source_table AS source
ON (target.id = source.id)
WHEN MATCHED THEN
UPDATE SET target.name = source.name, target.salary = source.salary
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
这个 MERGE INTO 语句的含义如下:
MERGE INTO target_table AS target:指定要合并数据的目标表 target_table,并为其指定别名 target。
USING source_table AS source:指定提供数据的源表 source_table,并为其指定别名 source。
ON (target.id = source.id):定义用于匹配目标表和源表的条件,这里是 id 列匹配。
WHEN MATCHED THEN:当条件匹配时执行的操作,这里是更新操作,将目标表的 name 和 salary 列更新为源表的对应值。
WHEN NOT MATCHED BY SOURCE THEN:当源表中没有匹配的记录时执行的操作,这里是删除操作,删除目标表中的记录。
MERGE是一个 DML 关键字,它能将 INSERT,UPDATE,DELETE 等操作并为一句,根据与源表联接的结果,对目标表执行插入、更新或删除操作。
MERGE 是一个 DML 关键字,它能将 INSERT,UPDATE,DELETE 等操作并为一句,根据与源表联接的结果,对目标表执行插入、更新或删除操作。
MERGE的语法
MERGE INTO target_table USING source_table
ON condition
WHEN MATCHED THEN
operation
WHEN NOT MATCHED THEN
operation;
-- target_table:目标表
-- source_table:原表
注意:其中最后语句分号不可以省略,且源表既可以是一个表也可以是一个子查询语句。
MERGE 的用法
merge 无法多次更新同一行,也无法更新和删除同一行
当源表和目标表不匹配时:
1 若数据是源表有目标表没有,则进行插入操作;
2 若数据是源表没有而目标表有,则进行更新或者删除数据操作
当源表和目标表匹配时:
3 进行更新操作或者删除操作
MERGE 的使用场景
1 数据同步
2 数据转换
3 基于源表对目标表做 INSERT,UPDATE,DELETE 操作
我们常用的是第三种场景
MERGE 使用限制
• 在 MERGE MATCHED 操作中,只能允许执行 UPDATE 或者 DELETE 语句。
• 在 MERGE NOT MATCHED 操作中,只允许执行 INSERT 语句。
• 一个 MERGE 语句中出现的 MATCHED 操作,只能出现一次 UPDATE 或者 DELETE 语句,
否则就会出现下面的错误:
An action of type 'WHEN MATCHED' cannot appear more than once in a 'UPDATE' clause of a MERGE statement.
MERGE 示例
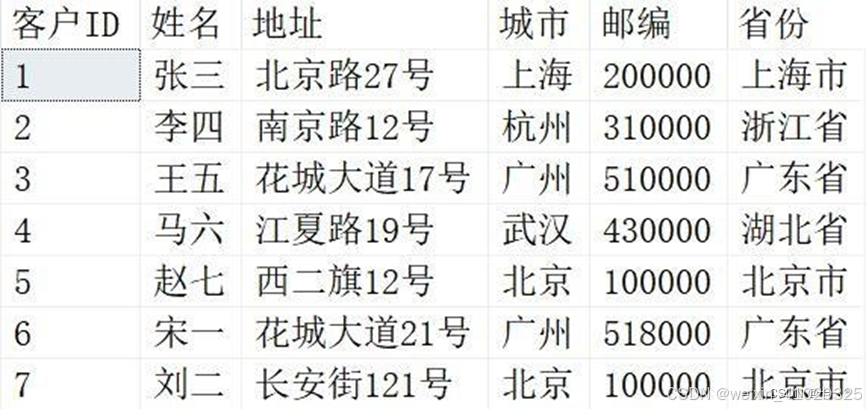
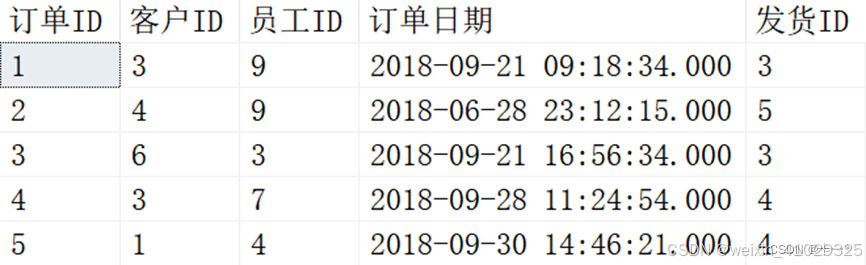
下面我们通过一个示例来介绍一下该如何使用 MERGE,我们以 Customers 表和Orders 表为例。数据如下:
Customers表:
Orders表:
Q:当 Customers 表里的客户有购买商品,我们就更新一下他们的下单时间,将他们的下单时间往后推迟一小时,如果客户没有购买商品,那么我们就将这些客户的信息插入到订单表里。
根据上面的要求我们可以这样写 SQL:
MERGE INTO Orders O
--确定目标表Orders
USING Customers C ON C.客户 ID=O.客户 ID
--从源表Customers 确定关联条件 C.客户ID=O.客户 ID
WHEN MATCHED
--当匹配时对目标表的订单日期执行更新操作
THEN UPDATE SET O.订单日期=DATEADD(HOUR,1,O.订单日期)
WHEN NOT MATCHED BY TARGET
--当不匹配时对目标表进行插入操作
THEN INSERT (客户 ID,员工 ID,订单日期,发货 ID) VALUES (C.客户 ID,NULL,NULL,NULL);
我们看一下 Orders 表里的结果: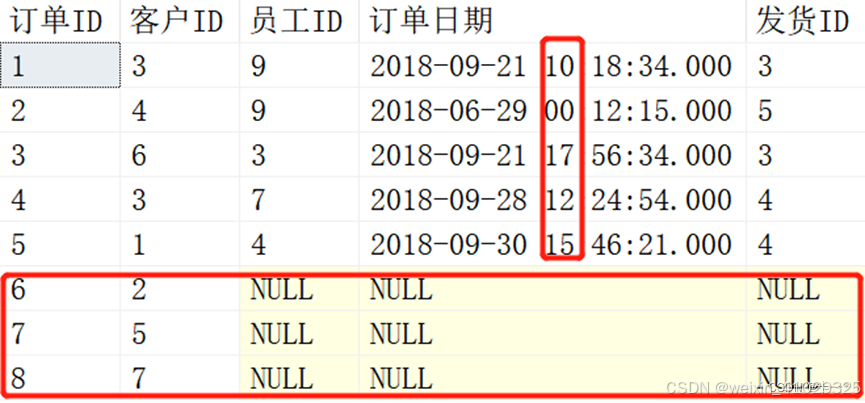 我们发现与 Customers 表里匹配上的订单日期被修改了,订单日期往后推迟了一小时,而没有匹配上的在订单表尾部增加了几行记录。这就是MERGE 的实际应用了。
我们发现与 Customers 表里匹配上的订单日期被修改了,订单日期往后推迟了一小时,而没有匹配上的在订单表尾部增加了几行记录。这就是MERGE 的实际应用了。
OUTPUT 子句
MERGE 还能与 OUTPUT 一起使用,可以将刚刚做过变动的数据进行输出,我们以上面的示例为基础,进行示范。
--确定目标表Orders
USING Customers C ON C.客户 ID=O.客户 ID
--从源表Customers 确定关联条件 C.客户ID=O.客户ID
WHEN MATCHED
--当匹配时对目标表的订单日期执行更新操作
THEN UPDATE SET O.订单日期=DATEADD(HOUR,1,O.订单日期) WHEN NOT MATCHED BY TARGET
--当不匹配时对目标表进行插入操作
THEN INSERT (客户 ID,员工 ID,订单日期,发货 ID) VALUES (C.客户 ID,NULL,NULL,NULL)
OUTPUT $action AS [ACTION],Inserted.订单日期 , Inserted.客户 ID,Inserted.发货 ID,Inserted.员工 ID
--用OUTPUT 输出刚刚变动过的数据
;
执行上述语句结果如下: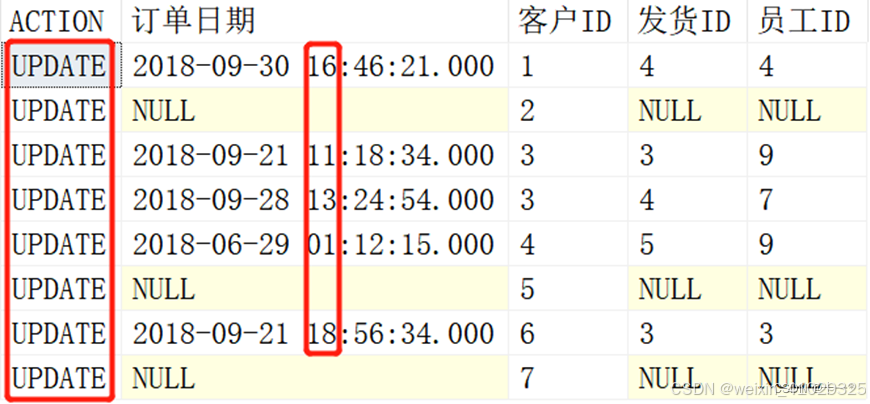
从上图我们看到,执行的动作都是更新,这里的动作只有 UPDATE 和 DELETE,插入也属于更新,此外我们看到订单日期又往后推迟了一小时,是因为我们又一次执行了往后增加一小时的更新操作,其他的字段没变。
总结
MERGE 功能比较丰富,以上我们只是简单介绍了一些常用功能,还有其他一些用法,有兴趣的可以搜索一下并动手尝试。在我们要对表做多种操作时,这种写法不仅可以节省代码,而且有时候还可以提高执行效率。
《Mysql 8.x 版本引入了 MERGE INTO 语法 》
《将oracle中的merge into转换成MySQL的语法》
-- 方法一:update + insert
-- merge其实就是不存在则insert,存在则update,所以可以把它拆分成:
update ... where exist(select 1 from ... where 条件)
insert .... where not exist(select 1 from ... where 条件)
-- where exists 的用法
1、where exists
(1)介绍
exists和in都有过滤功能,他俩最大的差别就是in引导的子句只能对一个字段进行限制,比如
-- 对id字段进行限定
select * from A where sid in (1,2,3)
但是如果我们想对多个字段进行限制,使用in就不合适了,例如:
select * from A where (sid,tid) in (select sid,tid from B)
-- 不过很可惜,上面的语句只能再DB2上执行,SQL Server不行
此时就可以使用exists 来对多个字段进行限制了
select * from A where exists (select 1 from B where A.sid=B.sid and A.tid=B.tid)
(2)原理
exists做为where条件时,是先对where 前的主查询询进行查询,然后用主查询的结果一个一个的代入exists的查询进行判断,如果为真则输出当前这一条主查询的结果,否则不输出。
查询时,一般情况下,子查询会分成两种情况:
select * from A where exists (select 1 from B where A.sid=B.sid and A.tid=B.tid)
它先执行A表的查询,再将查询结果一条一条放到B表的条件中去查询,如果存在,则显示此条
2.子查询与外表的字段没有任何关联
select * from A where exists (select * from B where B.id=‘条件‘)
在这种情况下,只要子查询的条件成立,就会查询出表1中的所有记录,反之,如果子查询中没有查询到记录,则表1不会查询出任何的记录。
以上两种方式本质上都是对A表查询进行过滤
2、update + insert
此种替代方式较为灵活,表可以无主键,自定义匹配规则。
注意:使用insert的时候需要加 where not exists(select 1 from 表明 where 条件),防止重复插入
insert可以不加 where exists
方法二:replace into
语法同insert into,使用简单,但有限制, replace into是根据主键去匹配,故replace into的表必须有主键,常用于单表更新新增。
REPLACE的运行与INSERT很相似。只有一点例外,假如表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除 !删除 !
所以还需要你有删除数据的权限。
注意,除非表有一个PRIMARY KEY或UNIQUE索引,否则,使用一个REPLACE语句没有意义。该语句会与INSERT相同,因为没有索引被用于确定是否新行复制了其它的行。
需要注意的问题就是replace into的时候会删除老记录。如果表中有一个自增的主键,那么就要出问题了。
方法三:on duplicate key update
在MYSQL中有语句 insert into ... on duplicate key update...
INSERT INTO table (id, name, age) values (1, 'yourname', 18)
ON DUPLICATE KEY UPDATE name='yourname', age=18;
id字段是主键或者UNIQUE索引。上述语句的作用是:
如果id = 1这条记录是不存在的,那么执行INSERT INTO语句。
如果id = 1在数据库中是存在的,那么执行UPDATE命令,此时这条语句相当于:
UPDATE table SET name='yourname', age=18 WHERE id=1;
再如果 age 字段也是UNIQUE的,相当于
UPDATE table SET name='yourname' WHERE id=1 OR age=18 LIMIT 1;
执行UPDATE语句的条件是INSERT语句的执行会造成唯一键的重复。
通常,应该尽量避免对带有多个唯一关键字的表使用ON DUPLICATE KEY子句。
还可以这样写:
INSERT INTO table
(SELECT id, 'hisname' as name FROM table WHERE id >= 3)
ON DUPLICATE KEY UPDATE name=VALUES(name);
这种方法还可以用来批量执行UPDATE操作(因为单条UPDATE语句只能执行一种update操作)
方法四:创建存储过程
CREATE PROCEDURE name()
if exists(select 1 from 表 where ID = @ID)
begin
UPDATE 表 SET XX= XX WHERE ID = @ID
end
else
begin
INSERT 表 VALUES(XX...)
end

















 4850
4850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









