







一.k近邻算法基本思想
依据距离欲判断的点最近的k个点来确定目标点的属性。解决监督学习中的分类问题,但也可解决回归问题。
[例如]肿瘤判断分类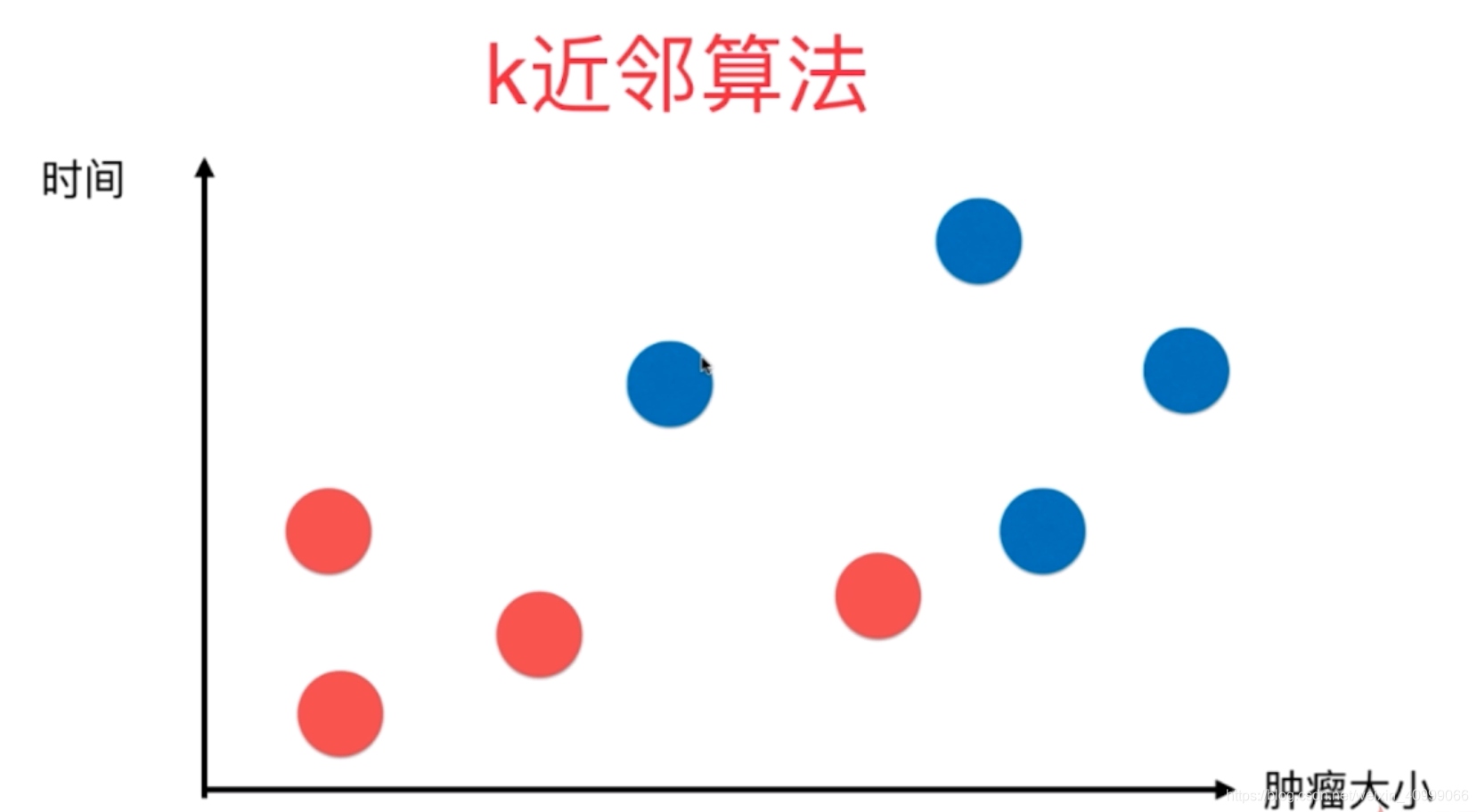
如图所示:本例中,我们仅依据肿瘤的大小和存在时间来判断肿瘤是良性还是恶性。图中,红色表示良性,蓝色表示恶性。可以见得这解决了一个分类问题。
我们依据现存的数据,判断一个新的病例为何性质。在这里我们取k为3(现实中具体的k值要依据经验等来获得)
假如新的病例举例最近的3个点中有大于等于2个属于良性,我们就判断这个肿瘤大概率属于良性。这便是k临近算法的思想。
二.kNN的实现
1.案例说明
import numpy as np
import matplotlib.pyplot as plt
raw_data_X = [[3.393533211,2.331273381],
[3.110073483,1.781539638],
[1.343808831,3.368369054],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.424088941],
[7.939820817,0.791637231],
]
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
x = np.array([8.093607318,3.365731514])
现在我们用raw_data_X来存储每个点的位置信息,用raw_data_y来存储该点是何性质,(0:良性,1:恶性),用x来存储欲判断点的信息。需要得出该点的性质。
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='g')
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='r')
plt.scatter(x[0],x[1],color='b')
plt.show()
绘制出已知点和欲判断点的位置关系。
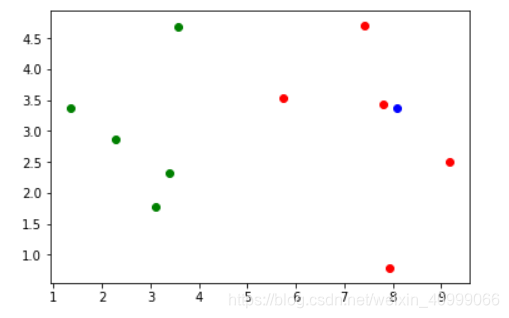
绿色表示良性,红色表示恶性,蓝色表示需要判断的点。现在我们可以得知,该点应该是恶性肿瘤,我们得出结果是1。
2.代码实现
from math import sqrt
distances = []
for x_train in X_train:
d = sqrt(np.sum((x_train - x) ** 2))
distances.append(d)
首先我们需要知道对于每个x_train实际上可以理解为一个横坐标和纵坐标组成的向量,np.sum(x_train - x) ** 2)就实现了将该向量对应元素都相减在平方,然后求和。sqrt()实现了开平方。如此便是我们初中学的求两点距离公式。
注:上面的代码可以用一行来实现
distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in X_train]
distances
输出的结果是:
[4.812566907609877,
5.229270827235305,
6.749799002320346,
4.6986266144110695,
5.83460014556857,
1.4900114024329525,
2.354574897431513,
1.3761132675144652,
0.3064319992975,
2.5786840957478887]
然后就需要用到numpy中的argsort()函数,本文底部补充中会对该函数进行介绍。
nearest = np.argsort(distances)
可以得到结果:array([8, 7, 5, 6, 9, 3, 0, 1, 4, 2], dtype=int64)。这是diatances中由小到大排序后返回的元素序号,将其存在nearest中。然后指定k = 6。接下来需要做的是依据nearest中的前k个数据在y_train中对应的性质(0:良性,1:恶性)来判断即可。
topK_y = [y_train[i] for i in nearest[:k]]
topK_y
得到结果为[1, 1, 1, 1, 1, 0],因此该点属性应是1,即该点的性质为恶性肿瘤,因此与之前预判的结果是一样的。然后用Counter()函数对每个元素进行计数
from collections import Counter
votes = Counter(topK_y)
predict_y = votes.most_common(1)[0][0]
最后得到predict_y 的结果是1。
下面给出完整的代码:
import numpy as np
from math import sqrt
from collections import Counter
def kNN_classify(k,X_train,y_train,x):
assert 1<=k<=X_train.shape[0],"k must be vaild"
assert X_train.shape[0] == y_train.shape[0],\
"the size of X_train must equal to the size of y_train"
assert X_train.shape[1] == x.shape[0],\
"the feaure number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x)**2)) for x_train in X_train]
nearest = np.argsort(distances)
topK_y = [y_train[i] for i in nearest[:k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
三.本例中用到的函数详解:
1.argsort()函数:
argsort()函数,是numpy库中的函数,用来实现排序功能。
一维数组:
import numpy as np
x = np.array([2,4,3])
y = np.argsort(x)
print(y)
得到结果:[0 2 1]
二维数组:
import numpy as np
x = np.array([[2,5],[3,4]])
y = np.argsort(x,axis=0)
print(y)
axis=0:按列排序。首先搞明白现在的x是一个矩阵
[2 5]
[3 4]此时该矩阵按列排序,第一列输出的序列号应该是[0,1],第二列就应输出[1,0]
输出结果
[[0 1] [1 0]]
axis=-1:默认,按行排序。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









