






众所周知,Redis的性能非常强大,单机QPS可以达到数万甚至十万。但是Redis默认是单线程模式,也就是说redis只使用了一颗CPU就能达到如此高的性能。这是怎么实现的呢?
这篇文章我们就来细致地介绍一下redis的线程模型,以及为什么redis的性能这么高。
一、知识背景:什么是Socket?
要理解Redis的事件驱动模型,必须要了解socket,这里简单介绍一下socket,如果读者对socket已经很了解了可以跳过这一节。
套接字(Socket)是由 BSD(伯克利软件开发组) 在 1980s 提出这套接口标准,称为 Berkeley Sockets API。它定义了如何在应用程序和网络协议栈之间进行通信。这个标准是操作系统和编程语言提供网络功能的基础。
可以理解为,操作系统提供了一个基于这个标准的接口,允许开发者通过编程语言(如 C、Python、Java)使用这个接口来进行网络通信。
套接字的主要功能:
- 建立连接:套接字用于发起或接受连接,通常客户端与服务器之间的通信是通过套接字来完成的。
- 数据传输:套接字用于发送和接收数据。
- 关闭连接:当通信结束后,套接字会关闭连接,释放相关的资源。
套接字的工作流程:
-
服务器端:
- 创建套接字并绑定到指定的端口。
- 监听来自客户端的连接请求。
- 接受连接并与客户端进行数据交换。
- 关闭连接。
-
客户端:
- 创建套接字并连接到服务器的 IP 地址和端口。
- 发送请求并接收服务器的响应。
- 关闭连接。
每个操作系统如何实现套接字?
操作系统通过实现套接字标准来提供网络通信功能。不同操作系统的实现细节可能有所不同,但它们都遵循套接字标准,提供了类似的API接口。
- Linux 和 macOS 基于 BSD 套接字 API 实现,提供类似的系统调用,如
socket()、bind()、listen()、accept()、recv()等。 - Windows 提供了类似的套接字功能,但接口细节有所不同,Windows 下的套接字接口称为 Winsock。不过,Winsock 也是基于 BSD 套接字接口进行实现的,只是做了一些 Windows-specific 的调整。
不同操作系统会通过不同的内核实现来支持这些套接字操作,但应用程序使用的接口大致是一样的。
各大编程语言(如 C、Python、Java、Go)都提供了自己的 套接字库,这些库封装了操作系统提供的套接字接口。虽然底层实现依赖于操作系统的网络栈,但开发者使用的接口通常是统一的。
上面提到的创建套接字创建的是什么?
在服务端和客户端的网络通信中,创建套接字的目的是为了让程序能够与操作系统的网络协议栈进行交互。套接字本身是操作系统内部的一种数据结构,操作系统通过它来管理网络连接和通信的相关操作。创建套接字后,程序可以使用它进行数据发送、接收,甚至建立连接。
当你在程序中调用socket()函数时,你实际上是请求操作系统创建一个用于网络通信的“接口”,这个接口会被用来与其他计算机进行数据交换。
创建一个套接字,实际上是在创建一个 通信端点,它包含了以下几个主要部分:
-
协议族(Address Family):指定套接字将使用哪种网络协议族(例如 IPv4 或 IPv6)。常见的有
AF_INET(IPv4 地址族)和AF_INET6(IPv6 地址族)。 -
套接字类型(Socket Type):决定了套接字如何进行数据传输。常见的有:
SOCK_STREAM(流式套接字,用于 TCP 协议,面向连接的可靠传输)SOCK_DGRAM(数据报套接字,用于 UDP 协议,无连接、不可靠传输)
-
协议(Protocol):指定套接字使用的具体协议类型。通常,操作系统会根据协议族和套接字类型自动选择适当的协议,如 TCP 或 UDP。
创建套接字的过程通常通过调用操作系统提供的 socket() 函数来完成。这个函数会返回一个 套接字描述符(一个整数值),表示套接字的唯一标识符,程序可以通过它来引用这个套接字并执行后续的网络操作(如连接、绑定、发送、接收数据等)。
二、进入正题:Redis事件驱动模型
Redis 的单线程并不是传统意义上的“逐个执行请求”,而是结合了事件驱动模型,使得单线程也能够高效处理大量并发请求。Redis 使用 I/O 多路复用技术来实现这一目标。
I/O 多路复用
I/O 多路复用 是一种能够 同时监视多个 I/O 操作(如读写操作)的技术,允许单个线程(或进程)同时处理多个网络连接(socket套接字)而不需要为每个连接创建一个线程或进程。
I/O 多路复用的工作原理是通过操作系统提供的系统调用来 监听多个 I/O 资源(例如多个套接字)的状态变化,并在这些资源可读、可写时通知应用程序,从而避免了阻塞等待。
不同的操作系统提供了不同的系统调用来实现 I/O 多路复用,这里不详细介绍具体的系统是怎么实现的了,感兴趣的同学自己去查资料吧。
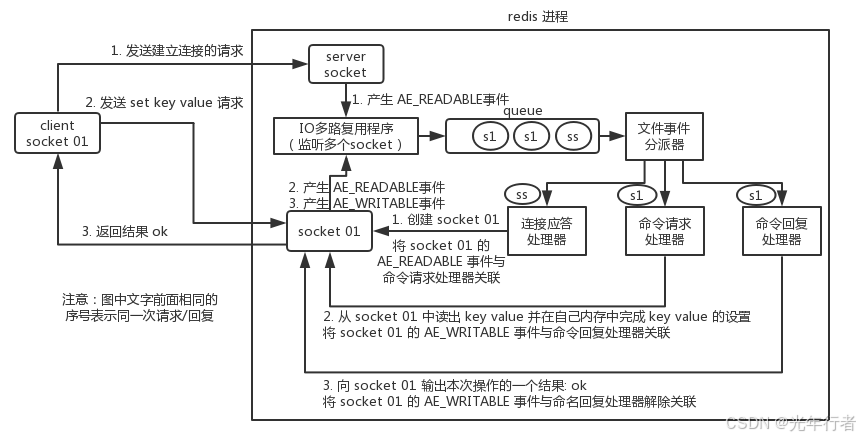
详细流程
- 当 Redis 启动时,它会初始化一个 事件集合,并将所有需要监听的事件类型注册到这个集合中,比如:服务器套接字(
server_socket)将被注册为监听AE_READABLE事件,用来监听所有客户端建立连接的请求。而后面每个和Redis建立连接的客户端都会被创建一个客户端套接字(socket01)并将其对应的AE_READABLE事件添加到这个事件集合里。 - 接下来,Redis 进入事件循环,多路复用程序开始监听事件。如果一个事件(例如
AE_READABLE)发生了,它会将这个事件放入 事件队列 中。 - 事件分派器从 事件队列 中取出事件,并根据 事件集合 中的注册信息,查找哪个处理器与这个事件类型相关,然后调用对应的 事件处理器处理这个事件(如 命令请求处理器 或 命令回复处理器)。
举个简单的例子
假设我们有一个 socket01(客户端套接字),客户端发送了一个 SET key value 命令:
- Redis 启动时,将
socket01注册为监听AE_READABLE事件,并与 命令请求处理器 关联。 - 客户端发送请求时,
socket01会触发AE_READABLE事件,事件多路复用程序将这个事件加入 事件队列。 - 事件分派器从事件队列中取出事件,并根据 事件集合 中的注册信息,调用 命令请求处理器 来处理请求。
- 处理完成后,命令请求处理器 注册一个新的
AE_WRITABLE事件到事件集合中,表示可以发送响应。 - 当
AE_WRITABLE事件触发时,事件分派器会调用 命令回复处理器,并将响应返回给客户端。
流程图:
为什么Redis单线程模型效率这么高?
- 纯内存操作。
- 核心是基于非阻塞的 IO 多路复用机制。
- C 语言实现,一般来说,C 语言实现的程序“距离”操作系统更近,执行速度相对会更快。
- 单线程反而避免了多线程的频繁上下文切换问题,预防了多线程可能产生的竞争问题。

















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









